L’ANOVA mixte sert à comparer les moyennes des groupes classés selon deux types différents de variables categorielles, incluant:
- des facteurs inter-sujets, qui ont des catégories indépendantes (p. ex., sexe : homme/femme)
- des facteurs intra-sujets, qui ont des catégories apparentées aussi appelées mesures répétées (p. ex., temps : avant/après le traitement).
Le test ANOVA mixte est également appelé ANOVA à modèle mixte et ANOVA à mesures mixtes..
Ce chapitre décrit différents types d’ANOVA mixte, notamment:
- ANOVA à deux facteurs mixtes, utilisée pour comparer les moyennes des groupes croisées par deux variables catégorielles indépendantes, incluant un facteur inter-sujets et un facteur intra-sujets.
- ANOVA à trois facteurs mixtes, utilisée pour évaluer s’il y a une interaction entre trois variables indépendantes, incluant les facteurs inter-sujets et intra-sujets. Vous pouvez avoir deux modèles différents pour l’ANOVA mixte à trois facteur:
- un facteur inter-sujets et deux facteurs intra-sujets
- deux facteurs inter-sujets et un facteur intra-sujets
Vous apprendrez à:
- Calculer et interpréter les différents tests d’ANOVA mixtes dans R.
- Vérifier les hypothèses de l’ANOVA mixte
- Effectuer des tests post-hoc, de multiples comparaisons par paires entre les groupes pour identifier les groupes qui sont différents
- Visualiser les données avec des boxplots, ajouter au graphique, les p-values de l’ANOVA et celles des comparaisons multiples par paires
Sommaire:
Livre Apparenté
Pratique des Statistiques dans R II - Comparaison de Groupes: Variables NumériquesHypothèses
L’ANOVA mixte formule les hypothèses suivantes au sujet des données:
- Aucune valeur aberrante significative dans aucune cellule du plan. Ceci peut être vérifié en visualisant les données à l’aide de boxplots et en utilisant la fonction
identify_outliers()[package rstatix]. - Normalité : la variable-réponse (ou dépendante) doit être distribuée approximativement normalement dans chaque cellule du plan expérimental. Ceci peut être vérifié en utilisant le test de normalité de Shapiro-Wilk (
shapiro_test()[rstatix]) ou par inspection visuelle en utilisant le QQ plot (ggqqplot()[ggpubr package]). - Homogénéité des variances : la variance de la variable-réponse doit être égale entre les groupes des facteurs inter-sujets. Ceci peut être évalué à l’aide du test de Levene pour l’égalité des variances (
levene_test()[rstatix]). - Hypothèse de sphéricité : la variance des différences entre les groupes intra-sujets doit être égale. Ceci peut être vérifié en utilisant le test de sphéricité de Mauchly, qui est automatiquement rapporté en utilisant la fonction R
anova_test(). - Homogénéité des covariances testées par la méthode M de Box. Les matrices de covariance devraient être égales dans les cellules formées par les facteurs inter-sujets.
Avant de calculer le test ANOVA mixte, vous devez effectuer quelques tests préliminaires pour vérifier si les hypothèses sont respectées.
Prérequis
Assurez-vous d’avoir installé les paquets R suivants:
tidyversepour la manipulation et la visualisation des donnéesggpubrpour créer facilement des graphiques prêts à la publicationrstatixcontient des fonctions R facilitant les analyses statistiquesdatarium: contient les jeux de données requis pour ce chapitre
Commencez par charger les paquets R suivants:
library(tidyverse)
library(ggpubr)
library(rstatix)Fonctions R clés:
anova_test()[paquet rstatix], un wrapper autour decar::Anova()pour faciliter le calcul de l’ANOVA sur mesures répétées. Principaux arguments pour executer l’ANOVA sur mesures répétées:data: data framedv: (numérique) le nom de la variable dépendante (ou variable-réponse).wid: nom de la variable spécifiant l’identificateur de cas/échantillon.between: facteur inter-sujets ou variable de groupementwithin: facteur ou variable de groupement intra-sujets
get_anova_table()[paquet rstatix]. Extrait le tableau ANOVA à partir du résultat deanova_test(). Elle retourne le tableau ANOVA qui est automatiquement corrigé pour tenir compte d’un éventuel écart par rapport à l’hypothèse de sphéricité. Par défaut, la correction de sphéricité de Greenhouse-Geisser est appliquée automatiquement aux seuls facteurs intra-sujets violant l’hypothèse de sphéricité (c.-à-d. la valeur p du test de Mauchly est significative, p <= 0,05). Pour en savoir plus, lisez le chapitre @ref(mauchly-s-test-of-sphericity-in-r).
ANOVA à deux facteurs mixtes
Préparation des données
Nous utiliserons le jeu de données anxiety [package datarium], qui contient le score d’anxiété, mesuré à trois moments (t1, t2 et t3), de trois groupes d’individus pratiquant des exercices physiques à différents niveaux (grp1 : basal, grp2 : moyen et grp3 : élevé)
L’ANOVA mixte à deux facteurs peut être utilisée pour évaluer s’il y a interaction entre le groupe et le temps pour expliquer le score d’anxiété.
Charger et afficher une ligne aléatoire par groupe:
# Format large
set.seed(123)
data("anxiety", package = "datarium")
anxiety %>% sample_n_by(group, size = 1)## # A tibble: 3 x 5
## id group t1 t2 t3
## <fct> <fct> <dbl> <dbl> <dbl>
## 1 5 grp1 16.5 15.8 15.7
## 2 27 grp2 17.8 17.7 16.9
## 3 37 grp3 17.1 15.6 14.3# Rassemblez les colonnes t1, t2 et t3 en format long.
# Convertir l'identifiant et le temps en facteurs
anxiety <- anxiety %>%
gather(key = "time", value = "score", t1, t2, t3) %>%
convert_as_factor(id, time)
# Inspecter quelques lignes aléatoires des données par groupes
set.seed(123)
anxiety %>% sample_n_by(group, time, size = 1)## # A tibble: 9 x 4
## id group time score
## <fct> <fct> <fct> <dbl>
## 1 5 grp1 t1 16.5
## 2 12 grp1 t2 17.7
## 3 7 grp1 t3 16.5
## 4 29 grp2 t1 18.4
## 5 30 grp2 t2 18.9
## 6 16 grp2 t3 12.7
## # … with 3 more rowsStatistiques descriptives
Regrouper les données par time et group, puis calculer quelques statistiques descriptives de la variable score : moyenne et sd (écart-type)
anxiety %>%
group_by(time, group) %>%
get_summary_stats(score, type = "mean_sd")## # A tibble: 9 x 6
## group time variable n mean sd
## <fct> <fct> <chr> <dbl> <dbl> <dbl>
## 1 grp1 t1 score 15 17.1 1.63
## 2 grp2 t1 score 15 16.6 1.57
## 3 grp3 t1 score 15 17.0 1.32
## 4 grp1 t2 score 15 16.9 1.70
## 5 grp2 t2 score 15 16.5 1.70
## 6 grp3 t2 score 15 15.0 1.39
## # … with 3 more rowsVisualisation
Créer un boxplot:
bxp <- ggboxplot(
anxiety, x = "time", y = "score",
color = "group", palette = "jco"
)
bxp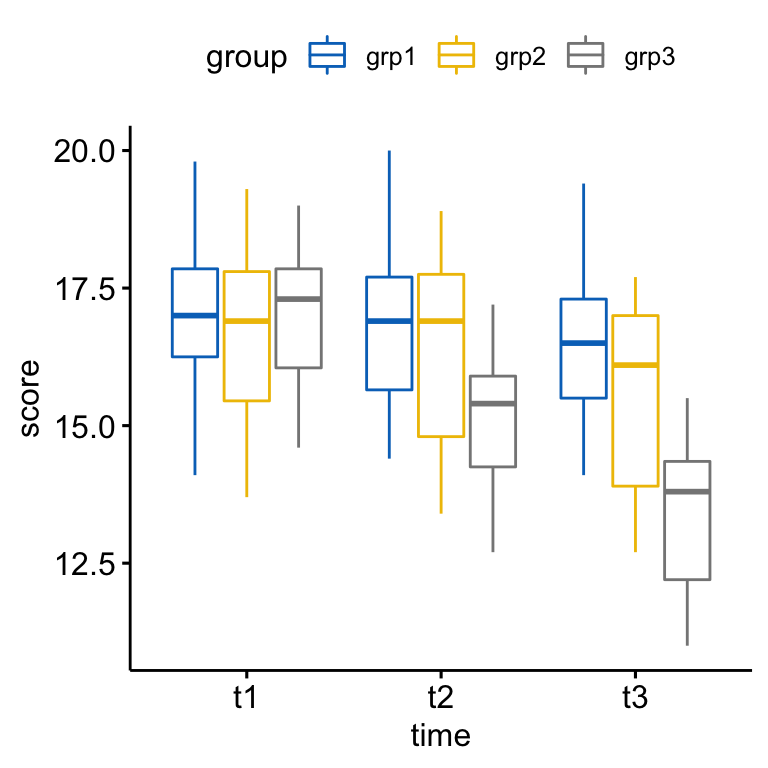
Vérifier les hypothèses
Valeurs aberrantes
Les valeurs aberrantes peuvent être facilement identifiées à l’aide de méthodes des boxplots, implémentées dans la fonction R identify_outliers() [paquet rstatix].
anxiety %>%
group_by(time, group) %>%
identify_outliers(score)## [1] group time id score is.outlier is.extreme
## <0 rows> (or 0-length row.names)Il n’y avait pas de valeurs extrêmes aberrantes.
Notez que, dans le cas où vous avez des valeurs extrêmes aberrantes, cela peut être dû à : 1) erreurs de saisie de données, erreurs de mesure ou valeurs inhabituelles.
Vous pouvez de toute façon inclure la valeur aberrante dans l’analyse si vous ne croyez pas que le résultat sera affecté de façon substantielle. Ceci peut être évalué en comparant le résultat de l’ANOVA avec et sans la valeur aberrante.
Il est également possible de conserver les valeurs aberrantes dans les données et d’effectuer un test ANOVA robuste en utilisant le package WRS2.
Hypothèse de normalité
L’hypothèse de normalité peut être vérifiée en calculant le test de Shapiro-Wilk pour chaque combinaison de niveaux des facteurs. Si les données sont normalement distribuées, la p-value doit être supérieure à 0,05.
anxiety %>%
group_by(time, group) %>%
shapiro_test(score)## # A tibble: 9 x 5
## group time variable statistic p
## <fct> <fct> <chr> <dbl> <dbl>
## 1 grp1 t1 score 0.964 0.769
## 2 grp2 t1 score 0.977 0.949
## 3 grp3 t1 score 0.954 0.588
## 4 grp1 t2 score 0.956 0.624
## 5 grp2 t2 score 0.935 0.328
## 6 grp3 t2 score 0.952 0.558
## # … with 3 more rowsLe score était normalement distribué (p > 0,05) pour chaque cellule, tel qu’évalué par le test de normalité de Shapiro-Wilk.
Notez que, si la taille de votre échantillon est supérieure à 50, le graphique de normalité QQ plot est préféré parce qu’avec des échantillons de plus grande taille, le test de Shapiro-Wilk devient très sensible même à un écart mineur par rapport à la distribution normale.
Le graphique QQ plot dessine la corrélation entre une donnée définie et la distribution normale.
ggqqplot(anxiety, "score", ggtheme = theme_bw()) +
facet_grid(time ~ group)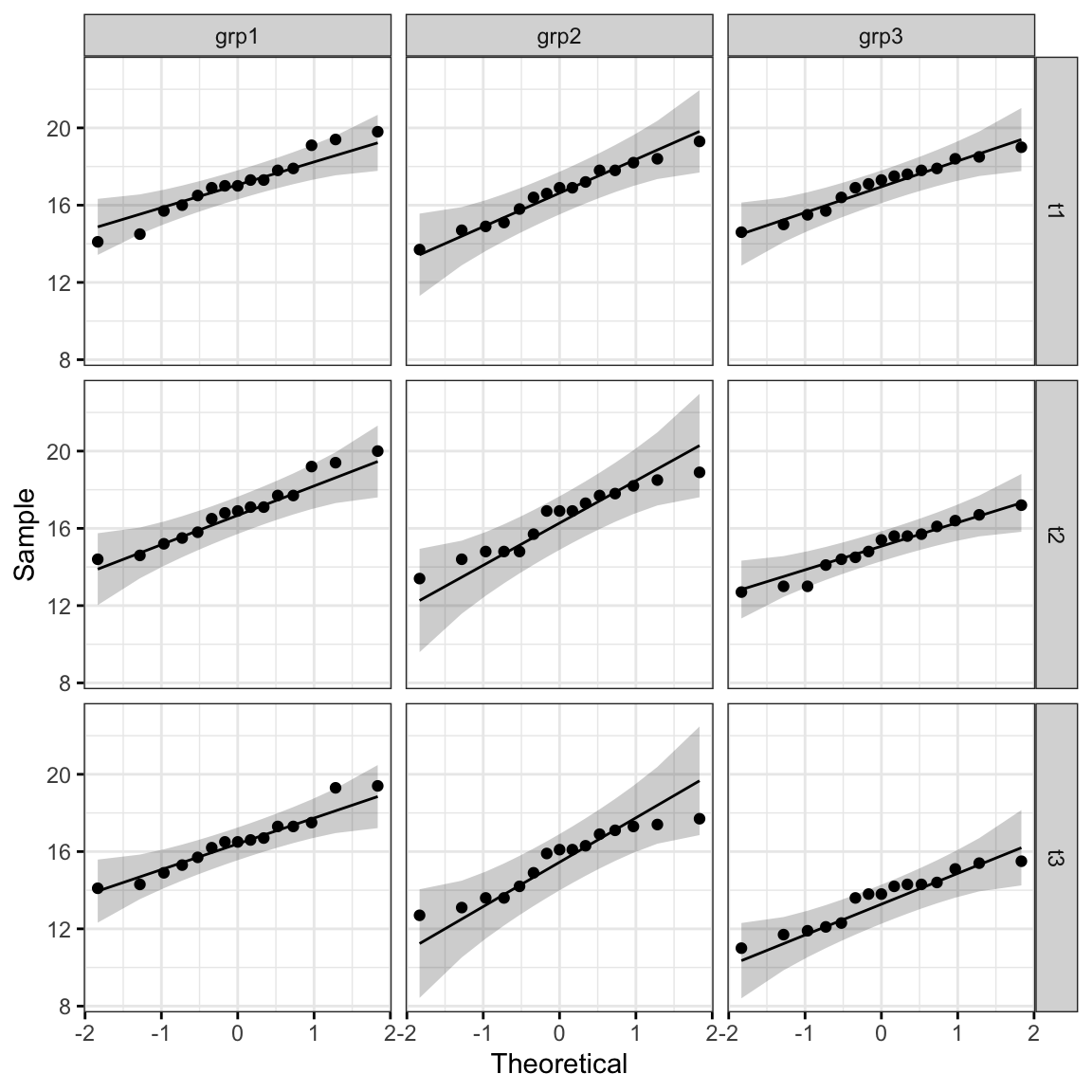
Tous les points se situent approximativement le long de la ligne de référence, pour chaque cellule. Nous pouvons donc supposer la normalité des données.
Dans le cas où les hypothèses ne sont pas satisfaites, vous pourriez envisager d’exécuter l’ANOVA sur les données transformées ou d’effectuer une ANOVA robuste à l’aide du package R WRS2.
L’hypothèse d’homogénéité des variances
L’homogénéité de l’hypothèse de variance du facteur inter-sujets (group) peut être vérifiée à l’aide du test de Levene. Le test est effectué à chaque niveau de la variable time:
anxiety %>%
group_by(time) %>%
levene_test(score ~ group)## # A tibble: 3 x 5
## time df1 df2 statistic p
## <fct> <int> <int> <dbl> <dbl>
## 1 t1 2 42 0.176 0.839
## 2 t2 2 42 0.249 0.781
## 3 t3 2 42 0.335 0.717L’homogénéité des variances, telle qu’évaluée par le test de Levene (p > 0,05), a été observée.
Notez que, si vous n’avez pas d’homogénéité des variances, vous pouvez essayer de transformer la variable-réponse (dépendante) pour corriger l’inégalité des variances.
Il est également possible d’effectuer un test ANOVA robuste à l’aide du package R WRS2.
Homogénéité de l’hypothèse de covariances
L’homogénéité des covariances du facteur inter-sujets (group) peut être évaluée à l’aide du test M de Box implémenté dans le package rstatix. Si ce test est statistiquement significatif (p < 0,001), vous n’avez pas les mêmes covariances, mais si le test n’est pas statistiquement significatif (p > 0,001), vous avez les mêmes covariances et vous n’avez pas violé l’hypothèse de l’homogénéité des covariances.
Notez que le test M de Box est très sensible, donc à moins que p < 0.001 et que vos tailles d’échantillon soient inégales, ignorez le. Cependant, si significatif et que la taille des échantillons est inégale, le test n’est pas robuste (https://en.wikiversity.org/wiki/Box%27s_M, Tabachnick & Fidell, 2001).
Calculer le test M de Box:
box_m(anxiety[, "score", drop = FALSE], anxiety$group)## # A tibble: 1 x 4
## statistic p.value parameter method
## <dbl> <dbl> <dbl> <chr>
## 1 1.93 0.381 2 Box's M-test for Homogeneity of Covariance MatricesIl y avait homogénéité des covariances, telle qu’évaluée par le test M de Box (p > 0,001).
Notez que, si vous n’avez pas d’homogénéité des covariances, vous pourriez envisager de séparer vos analyses en plusieurs ANOVA à mesures répétées pour chaque groupe. Vous pouvez également omettre l’interprétation du terme d’interaction.
Malheureusement, il est difficile de remédier à un échec de cette hypothèse. Souvent, une ANOVA mixte est exécutée de toute façon et la violation notée.
Hypothèse de sphéricité
Comme mentionné dans les sections précédentes, l’hypothèse de sphéricité sera automatiquement vérifiée lors du calcul du test ANOVA en utilisant la fonction R anova_test() [package rstatix]. Le test de Mauchly est utilisé en interne pour évaluer l’hypothèse de sphéricité.
En utilisant la fonction get_anova_table() [rstatix] pour extraire la table ANOVA, la correction de sphéricité de Greenhouse-Geisser est automatiquement appliquée aux facteurs qui violent l’hypothèse de sphéricité.
Calculs
# Test ANOVA à deux facteurs mixtes
res.aov <- anova_test(
data = anxiety, dv = score, wid = id,
between = group, within = time
)
get_anova_table(res.aov)## ANOVA Table (type II tests)
##
## Effect DFn DFd F p p<.05 ges
## 1 group 2 42 4.35 1.90e-02 * 0.168
## 2 time 2 84 394.91 1.91e-43 * 0.179
## 3 group:time 4 84 110.19 1.38e-32 * 0.108D’après les résultats ci-dessus, on peut voir qu’il existe une interaction statistiquement significative entre le groupe et le temps sur le score d’anxiété, F(4, 84) = 110.18, p < 0.0001.
Tests post-hoc
Une interaction significative à deux facteurs indique que l’impact d’un facteur sur la variable-réponse dépend du niveau de l’autre facteur (et vice versa). Ainsi, vous pouvez décomposer une interaction significative, à deux facteurs, en:
- Effet principal : exécuter le modèle à un facteur avec la première variable (facteur A) à chaque niveau de la deuxième variable (facteur B),
- Comparaisons par paires : si l’effet principal est significatif, effectuez plusieurs comparaisons par paires pour déterminer quels groupes sont différents.
Dans le cas d’une interaction à deux facteurs non significative, vous devez déterminer si vous avez des effets principaux statistiquement significatifs dans le résultat de l’ANOVA.
Procédure pour une interaction significative à deux facteurs
Effet principal la variable group. Dans notre exemple, nous étudierons l’effet du facteur inter-sujets group sur le score d’anxiété à chaque point de time.
# Effet de `group` à chaque point de `time`
one.way <- anxiety %>%
group_by(time) %>%
anova_test(dv = score, wid = id, between = group) %>%
get_anova_table() %>%
adjust_pvalue(method = "bonferroni")
one.way## # A tibble: 3 x 9
## time Effect DFn DFd F p `p<.05` ges p.adj
## <fct> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
## 1 t1 group 2 42 0.365 0.696 "" 0.017 1
## 2 t2 group 2 42 5.84 0.006 * 0.218 0.018
## 3 t3 group 2 42 13.8 0.0000248 * 0.396 0.0000744# Comparaisons par paires entre les niveaux de groupe
pwc <- anxiety %>%
group_by(time) %>%
pairwise_t_test(score ~ group, p.adjust.method = "bonferroni")
pwc## # A tibble: 9 x 10
## time .y. group1 group2 n1 n2 p p.signif p.adj p.adj.signif
## * <fct> <chr> <chr> <chr> <int> <int> <dbl> <chr> <dbl> <chr>
## 1 t1 score grp1 grp2 15 15 0.43 ns 1 ns
## 2 t1 score grp1 grp3 15 15 0.895 ns 1 ns
## 3 t1 score grp2 grp3 15 15 0.51 ns 1 ns
## 4 t2 score grp1 grp2 15 15 0.435 ns 1 ns
## 5 t2 score grp1 grp3 15 15 0.00212 ** 0.00636 **
## 6 t2 score grp2 grp3 15 15 0.0169 * 0.0507 ns
## # … with 3 more rows
Si l’on considère la p-value ajustée de Bonferroni (p.adj), on peut voir que l’effet principal de group était significatif à t2 (p = 0,018) et t3 (p < 0,0001) mais pas à t1 (p = 1).
Les comparaisons par paires montrent que le score d’anxiété moyen était significativement différent dans les comparaisons grp1 vs grp3 à t2 (p = 0,0063) ; dans grp1 vs grp3 (p < 0,0001) et dans grp2 vs grp3 (p = 0,0013) à t3.
Effets principaux de la variable time. Il est également possible d’effectuer la même analyse pour la variable intra-sujet time à chaque niveau de la variable group, comme indiqué dans le code R suivant. Vous n’avez pas nécessairement besoin de faire cette analyse.
# Effet du temps à chaque niveau du groupe d'exercices
one.way2 <- anxiety %>%
group_by(group) %>%
anova_test(dv = score, wid = id, within = time) %>%
get_anova_table() %>%
adjust_pvalue(method = "bonferroni")
one.way2## # A tibble: 3 x 9
## group Effect DFn DFd F p `p<.05` ges p.adj
## <fct> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
## 1 grp1 time 2 28 14.8 4.05e- 5 * 0.024 1.21e- 4
## 2 grp2 time 2 28 77.5 3.88e-12 * 0.086 1.16e-11
## 3 grp3 time 2 28 490. 1.64e-22 * 0.531 4.92e-22# Comparaisons par paires entre les points de temps (`time`)
# à chaque niveau de groupe (`group`)
# Le test t apparié est utilisé parce que
# nous avons répété les mesures en fonction du temps
pwc2 <- anxiety %>%
group_by(group) %>%
pairwise_t_test(
score ~ time, paired = TRUE,
p.adjust.method = "bonferroni"
) %>%
select(-df, -statistic, -p) # Supprimer les détails
pwc2## # A tibble: 9 x 8
## group .y. group1 group2 n1 n2 p.adj p.adj.signif
## * <fct> <chr> <chr> <chr> <int> <int> <dbl> <chr>
## 1 grp1 score t1 t2 15 15 0.194 ns
## 2 grp1 score t1 t3 15 15 0.002 **
## 3 grp1 score t2 t3 15 15 0.006 **
## 4 grp2 score t1 t2 15 15 0.268 ns
## 5 grp2 score t1 t3 15 15 0.000000151 ****
## 6 grp2 score t2 t3 15 15 0.0000000612 ****
## # … with 3 more rowsIl y avait un effet statistiquement significatif du temps sur le score d’anxiété pour chacun des trois groupes. En utilisant des comparaisons par paires de tests t appariés, on peut voir que pour grp1 et grp2, le score moyen d’anxiété n’était pas statistiquement significativement différent entre les temps t1 et t2.
Les comparaisons par paires t1 vs t3 et t2 vs t3 étaient statistiquement significativement différentes pour tous les groupes.
Procédure pour une interaction non significative à deux facteurs
Si l’interaction n’est pas significative, il faut interpréter les effets principaux pour chacune des deux variables : group ettime. Un effet principal significatif peut être suivi par des comparaisons par paires.
Dans notre exemple, il y avait un effet principal statistiquement significatif de la variable groupe (F(2, 42) = 4,35, p = 0,02) et du temps (F(2, 84) = 394,91, p < 0,0001) sur le score d’anxiété.
Effectuer plusieurs t-tests appariés par paires pour la variable time, en ignorant group. Les p-values sont ajustées à l’aide de la méthode de correction des tests multiples de Bonferroni.
anxiety %>%
pairwise_t_test(
score ~ time, paired = TRUE,
p.adjust.method = "bonferroni"
)Toutes les comparaisons par paires sont significatives.
Vous pouvez effectuer une analyse similaire pour la variable group.
anxiety %>%
pairwise_t_test(
score ~ group,
p.adjust.method = "bonferroni"
)Toutes les comparaisons par paires sont significatives sauf pour grp1 vs grp2.
Rapporter
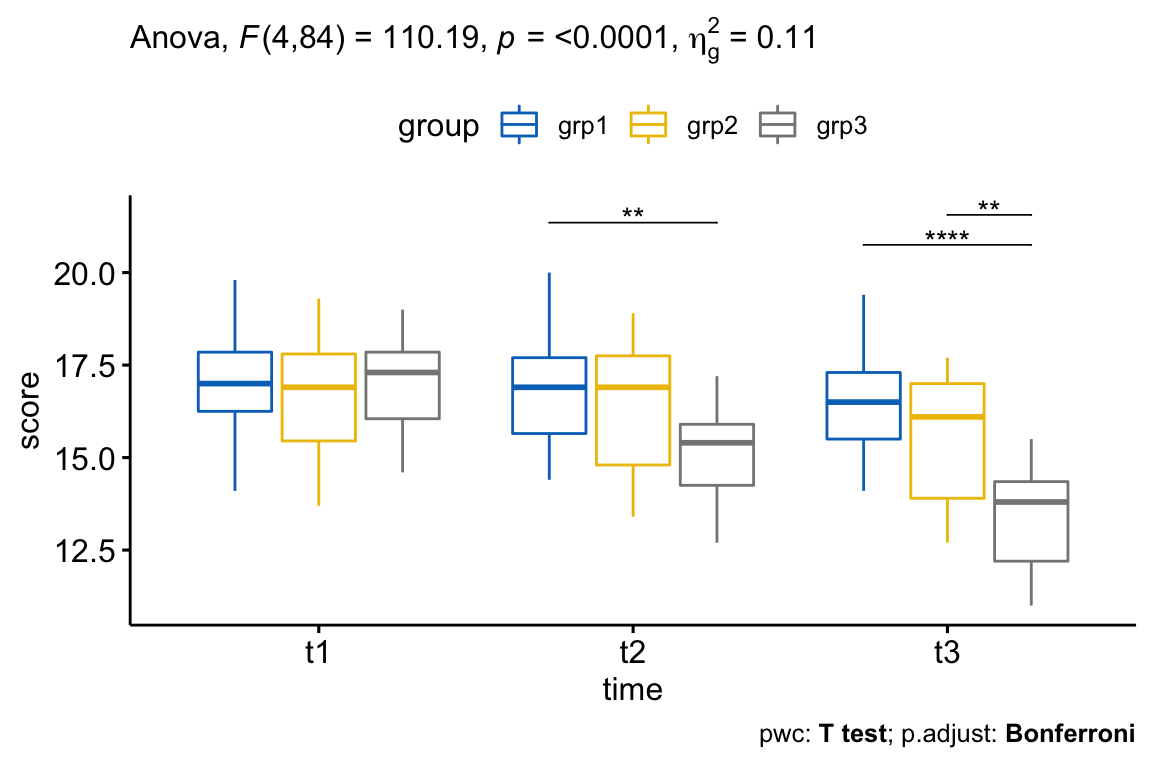
Il y avait une interaction statistiquement significative entre la variable exercises et time pour expliquer le score d’anxiété, F(4, 84) = 110.19, p < 0.0001.
Si l’on considère la p-value ajustée de Bonferroni, l’effet principal de la variable exercices était significatif à t2 (p = 0,018) et t3 (p < 0,0001) mais pas à t1 (p = 1).
Les comparaisons par paires montrent que le score d’anxiété moyen était significativement différent dans les comparaisons grp1 vs grp3 à t2 (p = 0,0063) ; dans grp1 vs grp3 (p < 0,0001) et dans grp2 vs grp3 (p = 0,0013) à t3.
Notez que, pour le graphique ci-dessous, nous n’avons besoin que des résultats de la comparaison par paires pour t2 et t3 mais pas pour t1 (parce que l’effet principal de la variable exercice n’était pas significatif à ce temps précis). Nous filtrerons les résultats de la comparaison en conséquence.
# Visualisation : boxplots avec p-values
pwc <- pwc %>% add_xy_position(x = "time")
pwc.filtered <- pwc %>% filter(time != "t1")
bxp +
stat_pvalue_manual(pwc.filtered, tip.length = 0, hide.ns = TRUE) +
labs(
subtitle = get_test_label(res.aov, detailed = TRUE),
caption = get_pwc_label(pwc)
)
ANOVA mixte à trois facteurs : 2 facteurs inter-sujets et 1 intra-sujets
Cette section décrit comment calculer l’ANOVA à trois facteurs, dans R, pour une situation où vous avez deux facteurs inter-sujets et un facteur intra-sujets.
Ce paramètre permet d’étudier les différences entre les groupes au fil du temps (c.-à-d. le facteur intra-sujets) lorsque les groupes sont formés par la combinaison de deux facteurs inter-sujets. Par exemple, vous voudrez peut-être comprendre comment le score de performance change au fil du temps (p. ex., 0, 4 et 8 mois) selon le sexe (p. ex., homme/femme) et le stress (faible, moyen et élevé).
Préparation des données
Nous utiliserons le jeu de données de performance [package datarium] contenant les mesures de performance des participants à deux temps différents. Le but de cette étude est d’évaluer l’effet du genre et du stress sur le score de performance.
Les données contiennent les variables suivantes:
- Score de performance (variable-réponse ou variable-dépendante) mesuré à deux points dans le temps,
t1ett2. - Deux facteurs inter-sujets : le sexe (niveaux : masculin et féminin) et le stress (faible, modéré, élevé)
- Un facteur intra-sujets,
time, qui comporte deux points dans le temps :t1ett2.
Charger et inspecter les données en affichant une ligne aléatoire par groupe:
# Charger et inspecter les données
# Format large
set.seed(123)
data("performance", package = "datarium")
performance %>% sample_n_by(gender, stress, size = 1)## # A tibble: 6 x 5
## id gender stress t1 t2
## <int> <fct> <fct> <dbl> <dbl>
## 1 3 male low 5.63 5.47
## 2 18 male moderate 5.57 5.78
## 3 25 male high 5.48 5.74
## 4 39 female low 5.50 5.66
## 5 50 female moderate 5.96 5.32
## 6 51 female high 5.59 5.06# Rassemblez les colonnes t1, t2 et t3 en format long.
# Convertir l'identifiant et le temps en facteurs
performance <- performance %>%
gather(key = "time", value = "score", t1, t2) %>%
convert_as_factor(id, time)
# Inspecter quelques lignes aléatoires des données par groupes
set.seed(123)
performance %>% sample_n_by(gender, stress, time, size = 1)## # A tibble: 12 x 5
## id gender stress time score
## <fct> <fct> <fct> <fct> <dbl>
## 1 3 male low t1 5.63
## 2 8 male low t2 5.92
## 3 15 male moderate t1 5.96
## 4 19 male moderate t2 5.76
## 5 30 male high t1 5.38
## 6 21 male high t2 5.64
## # … with 6 more rowsStatistiques descriptives
Regroupez les données par gender, stress et time, puis calculez quelques statistiques descriptives de la variable score : moyenne et sd (écart-type)
performance %>%
group_by(gender, stress, time ) %>%
get_summary_stats(score, type = "mean_sd")## # A tibble: 12 x 7
## gender stress time variable n mean sd
## <fct> <fct> <fct> <chr> <dbl> <dbl> <dbl>
## 1 male low t1 score 10 5.72 0.19
## 2 male low t2 score 10 5.70 0.143
## 3 male moderate t1 score 10 5.72 0.193
## 4 male moderate t2 score 10 5.77 0.155
## 5 male high t1 score 10 5.48 0.121
## 6 male high t2 score 10 5.64 0.195
## # … with 6 more rowsVisualisation
Créez des box plots du score de performance par sexe, colorés par les niveaux de stress et facettés par time:
bxp <- ggboxplot(
performance, x = "gender", y = "score",
color = "stress", palette = "jco",
facet.by = "time"
)
bxp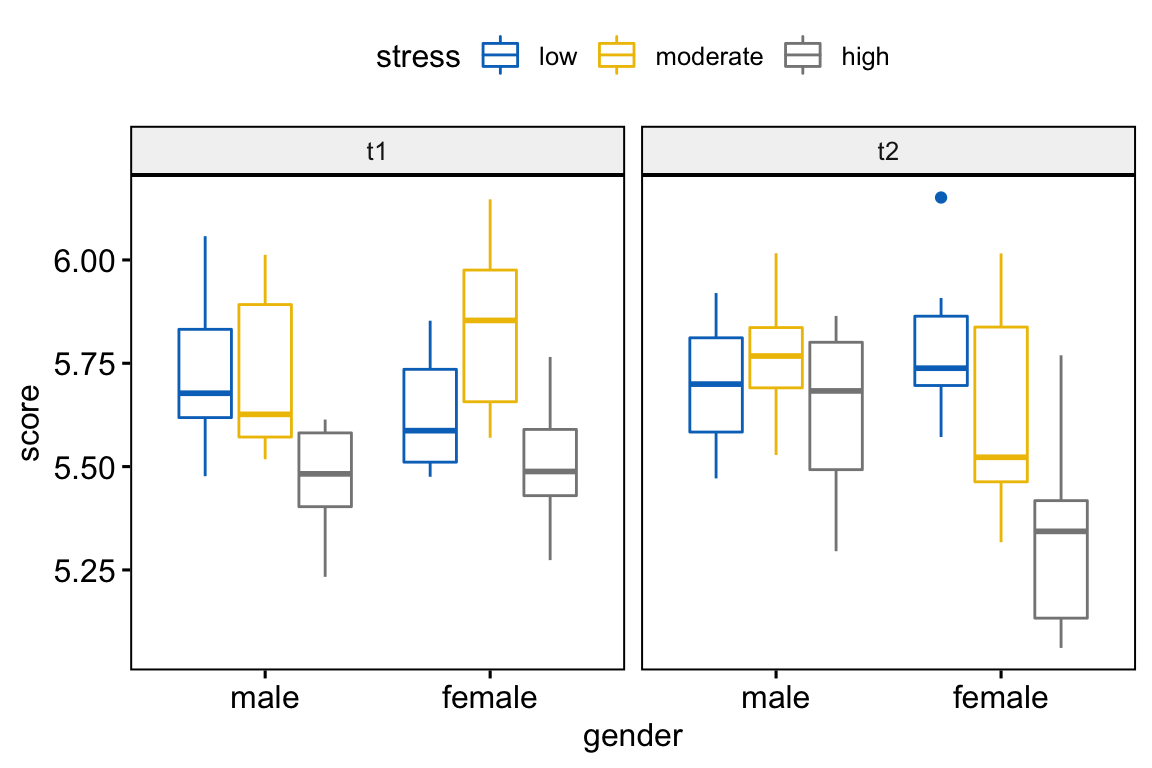
Vérifier les hypothèses
Valeurs aberrantes
performance %>%
group_by(gender, stress, time) %>%
identify_outliers(score)## # A tibble: 1 x 7
## gender stress time id score is.outlier is.extreme
## <fct> <fct> <fct> <fct> <dbl> <lgl> <lgl>
## 1 female low t2 36 6.15 TRUE FALSEIl n’y avait pas de valeurs extrêmes aberrantes.
Hypothèse de normalité
Calculer le test de Shapiro-Wilk pour chaque combinaison de niveaux des facteurs:
performance %>%
group_by(gender, stress, time ) %>%
shapiro_test(score)## # A tibble: 12 x 6
## gender stress time variable statistic p
## <fct> <fct> <fct> <chr> <dbl> <dbl>
## 1 male low t1 score 0.942 0.574
## 2 male low t2 score 0.966 0.849
## 3 male moderate t1 score 0.848 0.0547
## 4 male moderate t2 score 0.958 0.761
## 5 male high t1 score 0.915 0.319
## 6 male high t2 score 0.925 0.403
## # … with 6 more rowsLe score était normalement distribué (p > 0,05) pour chaque cellule, tel qu’évalué par le test de normalité de Shapiro-Wilk.
Créer un QQ plot pour chaque cellule du plan:
ggqqplot(performance, "score", ggtheme = theme_bw()) +
facet_grid(time ~ stress, labeller = "label_both")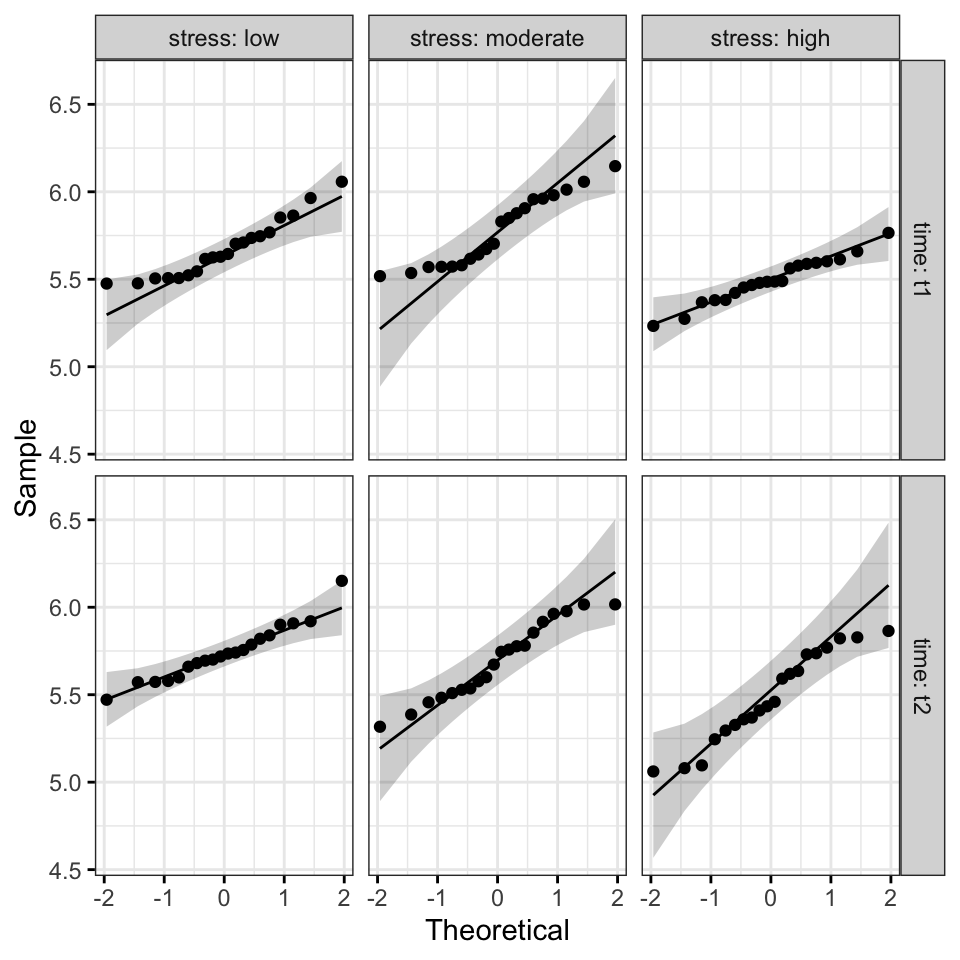
Tous les points se situent approximativement le long de la ligne de référence, pour chaque cellule. Nous pouvons donc supposer la normalité des données.
L’hypothèse d’homogénéité des variances
Calculez le test de Levene à chaque niveau du facteur intra-sujets, ici la variable time:
performance %>%
group_by(time) %>%
levene_test(score ~ gender*stress)## # A tibble: 2 x 5
## time df1 df2 statistic p
## <fct> <int> <int> <dbl> <dbl>
## 1 t1 5 54 0.974 0.442
## 2 t2 5 54 0.722 0.610Il y avait l’homogénéité des variances, telle qu’évaluée par le test d’homogénéité de la variance de Levene (p > .05).
Hypothèse de sphéricité
Comme mentionné dans la section ANOVA à deux facteurs mixtes, le test de sphéricité de Mauchly et les corrections de sphéricité sont effectués en interne en utilisant la fonction R anova_test() et get_anova_table() [paquet rstatix].
Calculs
res.aov <- anova_test(
data = performance, dv = score, wid = id,
within = time, between = c(gender, stress)
)
get_anova_table(res.aov)## ANOVA Table (type II tests)
##
## Effect DFn DFd F p p<.05 ges
## 1 gender 1 54 2.406 1.27e-01 0.023000
## 2 stress 2 54 21.166 1.63e-07 * 0.288000
## 3 time 1 54 0.063 8.03e-01 0.000564
## 4 gender:stress 2 54 1.554 2.21e-01 0.029000
## 5 gender:time 1 54 4.730 3.40e-02 * 0.041000
## 6 stress:time 2 54 1.821 1.72e-01 0.032000
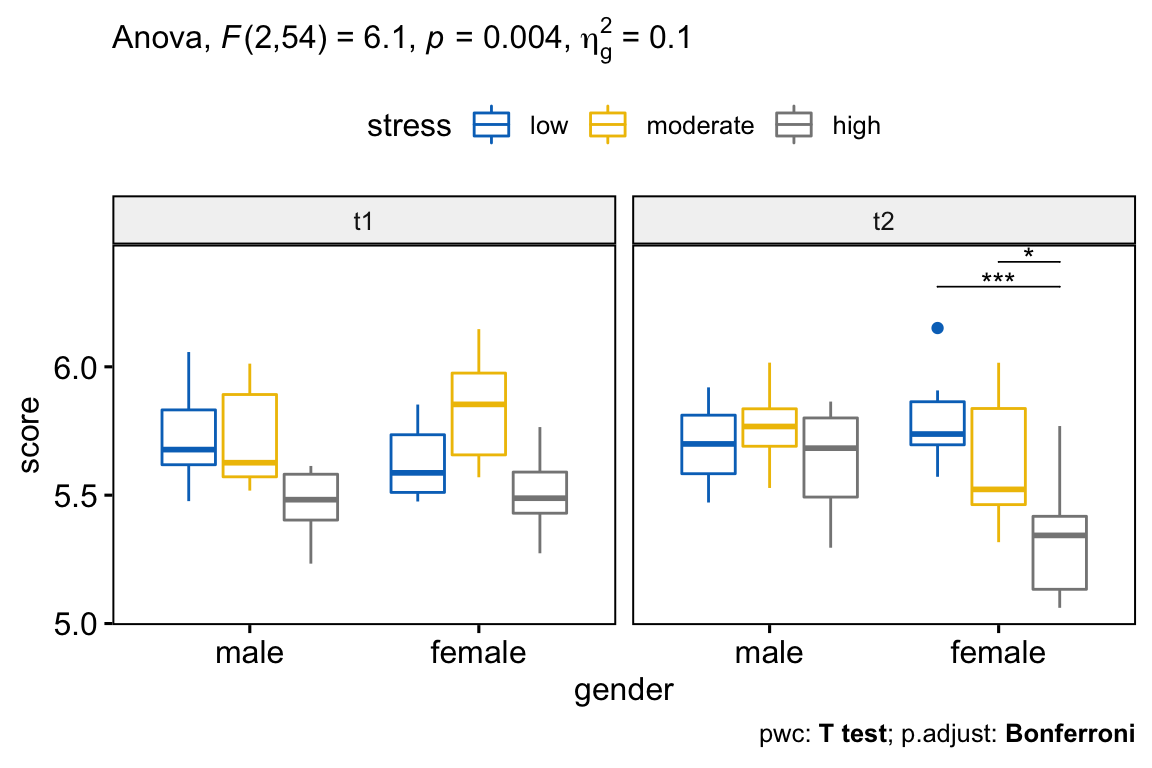
## 7 gender:stress:time 2 54 6.101 4.00e-03 * 0.098000Il y a une interaction statistiquement significative entre le temps, le sexe et le stress F(2, 54) = 6,10, p = 0,004.
Tests post-hoc
S’il y a un effet significatif d’interaction à trois facteurs, vous pouvez le décomposer en:
- Interaction à deux facteurs : exécuter l’interaction, à deux facteurs, à chaque niveau de la troisième variable,
- Effet principal : exécuter un modèle, à un facteur, à chaque niveau de la deuxième variable, et
- Comparaisons par paires : effectuer des comparaisons par paires ou d’autres comparaisons post-hoc si nécessaire.
Si vous n’avez pas d’interaction à trois facteurs statistiquement significative, vous devez déterminer si vous avez une interaction à deux facteurs statistiquement significative à partir du résultat de l’ANOVA. Une interaction significative, à deux facteurs, peut être suivie d’une analyse de l’effet principal, qui si elle est significative, peut être suivie de simples comparaisons par paires.
Dans cette section, nous décrirons la procédure à suivre pour une interaction significative à trois facteurs.
Calculer l’interaction à deux facteurs
Vous êtes libre de décider des deux variables qui formeront les interactions et de la variable qui servira de troisième variable.
Dans le code R suivant, nous avons considéré l’interaction à deux facteurs gender*stress à chaque niveau de time.
Regrouper les données par le temps (time, facteur intra-sujet) et analyser l’interaction entre le genre (gender) et le stress (stress), qui sont les facteurs inter-sujets.
# interaction à deux facteurs à chaque niveau de temps
two.way <- performance %>%
group_by(time) %>%
anova_test(dv = score, wid = id, between = c(gender, stress))
two.way## # A tibble: 6 x 8
## time Effect DFn DFd F p `p<.05` ges
## <fct> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl>
## 1 t1 gender 1 54 0.186 0.668 "" 0.003
## 2 t1 stress 2 54 14.9 0.00000723 * 0.355
## 3 t1 gender:stress 2 54 2.12 0.131 "" 0.073
## 4 t2 gender 1 54 5.97 0.018 * 0.1
## 5 t2 stress 2 54 9.60 0.000271 * 0.262
## 6 t2 gender:stress 2 54 4.95 0.011 * 0.155On a observé une interaction statistiquement significative entre le sexe et le stress à t2, F(2, 54) = 4,95, p = 0,011, mais pas à t1, F(2, 54) = 2,12, p = 0,13.
Il est à noter que la significativité statistique d’une interaction simple, à deux facteurs, a été acceptée à un niveau alpha ajusté de Bonferroni de 0,025. Cela correspond au niveau actuel auquel vous déclarez une significativité statistique (c.-à-d. p < 0,05) divisé par le nombre d’interactions à deux facteurs que vous analysées (c.-à-d. 2).
Calculer les effets principaux
Une interaction à deux facteurs statistiquement significative peut être suivie par une analyse des effets principaux.
Dans notre exemple, vous pourriez donc étudier l’effet du stress sur le score de performance à tous les niveaux de gender (genre) ou étudier l’effet de gender à tous les niveaux de stress.
Notez que vous n’aurez besoin de le faire que pour l’interaction, à deux facteurs, pour “t2” car c’était la seule interaction qui était statistiquement significative.
Regrouper les données par le temps et le sexe , et analyser l’effet principal simple du stress sur le score de performance:
stress.effect <- performance %>%
group_by(time, gender) %>%
anova_test(dv = score, wid = id, between = stress)
stress.effect %>% filter(time == "t2")## # A tibble: 2 x 9
## gender time Effect DFn DFd F p `p<.05` ges
## <fct> <fct> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl>
## 1 male t2 stress 2 27 1.57 0.227 "" 0.104
## 2 female t2 stress 2 27 10.5 0.000416 * 0.438
Dans le tableau ci-dessus, nous n’avons besoin des résultats que pour time = t2. Le seuil de significativité statistique d’un effet principal est de 0,25 après ajustement de Bonferroni, soit 0,05 divisé par le nombre d’effets principaux analysés (c’est-à-dire 2).
Il y avait un effet principal statistiquement significatif du stress sur le score de performance des femmes au temps t2, F(2, 27) = 10,5, p = 0,0004, mais pas pour les hommes, F(2, 27) = 1,57, p = 0,23.
Calculer les comparaisons entre groupes
Un effet principal statistiquement significatif peut être suivi de multiples comparaisons par paires pour déterminer quelles moyennes de groupe sont différentes.
Notez que vous n’aurez besoin de vous concentrer que sur les résultats de la comparaison par paires pour les femmes, car l’effet du stress était significatif pour les femmes seulement dans la section précédente.
Regroupez les données par time et gender, et effectuez des comparaisons par paires entre les niveaux de stress avec la correction de Bonferroni:
# Faire des comparaisons par paires
pwc <- performance %>%
group_by(time, gender) %>%
pairwise_t_test(score ~ stress, p.adjust.method = "bonferroni") %>%
select(-p, -p.signif) # Supprimer les détails
# Focus sur les résultats de `female` à t2
pwc %>% filter(time == "t2", gender == "female")## # A tibble: 3 x 9
## gender time .y. group1 group2 n1 n2 p.adj p.adj.signif
## <fct> <fct> <chr> <chr> <chr> <int> <int> <dbl> <chr>
## 1 female t2 score low moderate 10 10 0.323 ns
## 2 female t2 score low high 10 10 0.000318 ***
## 3 female t2 score moderate high 10 10 0.0235 *Chez les femmes, le score de performance moyen était statistiquement significativement différent entre les niveaux de stress faible et élevé (p < 0,001) et entre les niveaux de stress modéré et élevé (p = 0,023).
Il n’y avait pas de différence significative entre les groupes de stress faible et modéré (p = 0,32)
Rapporter
Une ANOVA à trois facteurs a été effectuée pour évaluer les effets du sexe, du stress et du temps sur le score de performance.
Il n’y avait pas de valeurs extrêmes aberrantes, telles qu’évaluées par la méthode des boxplots. Les données étaient normalement distribuées, telles qu’évaluées par le test de normalité de Shapiro-Wilk (p > 0,05). L’homogénéité des variances (p > 0,05) a été évaluée par le test d’homogénéité des variances de Levene.
Il y a une interaction statistiquement significative entre le sexe, le stress et le temps, F(2, 54) = 6,10, p = 0,004.
Pour les interactions, à deux facteurs, et les effets principaux, un ajustement de Bonferroni a été appliqué, résultant à un seuil d’acceptance de p < 0,025 pour la significativité statistique.
On a observé une interaction statistiquement significative entre le sexe et le stress au temps t2, F(2, 54) = 4,95, p = 0,011, mais pas à t1, F(2, 54) = 2,12, p = 0,13.
Il y avait un effet principal statistiquement significatif du stress sur le score de performance des femmes au temps t2, F(2, 27) = 10,5, p = 0,0004, mais pas pour les hommes, F(2, 27) = 1,57, p = 0,23.
Toutes les comparaisons par paires ont été effectuées entre les différents groupes de stress pour les femmes au temps t2. Un ajustement de Bonferroni a été appliqué.
Le score de performance moyen était statistiquement significativement différent entre les niveaux de stress faible et élevé (p < 0,001) et entre les niveaux de stress modéré et élevé (p = 0,024). Il n’y avait pas de différence significative entre les groupes de stress faible et modéré (p = 0,32).
# Visualisation : Boxplots avec p-values
pwc <- pwc %>% add_xy_position(x = "gender")
pwc.filtered <- pwc %>% filter(time == "t2", gender == "female")
bxp +
stat_pvalue_manual(pwc.filtered, tip.length = 0, hide.ns = TRUE) +
labs(
subtitle = get_test_label(res.aov, detailed = TRUE),
caption = get_pwc_label(pwc)
)
ANOVA mixte à trois facteurs : 1 facteur inter-sujets et 2 intra-sujets
Cette section décrit comment calculer l’ANOVA à trois facteurs, dans R, pour une situation où vous avez un facteur inter-sujets et deux facteurs intra-sujets. Par exemple, vous voudrez peut-être comprendre en quoi le score de perte de poids diffère selon que l’on fasse des exercices ou non (t1, t2, t3) en fonction du régime alimentaire des participants (diet:no et diet:yes).
Préparation des données
Nous utiliserons le jeu de données weightloss (perte de poids) disponible dans le package datarium. Cet jeu de données a été créé à l’origine pour l’ANOVA sur mesures répétées à trois facteurs. Cependant, pour notre exemple dans cet article, nous allons modifier légèrement les données pour qu’elles correspondent à un plan mixte à trois facteurs.
Un chercheur voulait évaluer l’effet du temps sur le score de perte de poids en fonction des programmes d’exercices et diet.
Le score de perte de poids a été mesuré dans deux groupes différents : un groupe de participants faisant des exercices (exercises:yes) et un autre groupe ne faisant pas d’exercices (excises:no).
Chaque participant a également été inscrit à deux essais cliniques : (1) pas de régime alimentaire et (2) régime alimentaire. L’ordre des essais a été contrebalancé et un délai suffisant a été respecté entre les essais pour que les effets des essais précédents puissent se dissiper.
Chaque essai a duré 9 semaines et le score de perte de poids a été mesuré au début de chaque essai (t1), au milieu de chaque essai (t2) et à la fin de chaque essai (t3).
Dans le cadre de cette étude, 24 personnes ont été impliquées. Sur ces 24 participants, 12 appartiennent au groupe exercises:no et 12 étaient dans le groupe exercises:yes. Les 24 participants ont été inclus dans deux essais successifs (diet:no et diet:yes) et le score de perte de poids a été mesuré à plusieurs reprises à trois temps différents.
Dans ce contexte, nous avons:
- une variable dépendante (ou variable-réponse):
score - Un facteur inter-sujets:
exercises - deux facteurs intra-sujets:
dietettime
L’ANOVA mixte à trois facteurs peut être effectuée afin de déterminer s’il y a une interaction significative entre les variables diet (régime alimentaire), exercises (exercices) et time (le temps) sur le score de perte de poids.
Charger les données et inspecter quelques lignes aléatoires par groupe:
# Charger les données d'origine
# Format large
data("weightloss", package = "datarium")
# Modifiez-le pour avoir un design mixte à trois facteurs
weightloss <- weightloss %>%
mutate(id = rep(1:24, 2)) # deux essais
# Afficher une ligne aléatoire par groupe
set.seed(123)
weightloss %>% sample_n_by(diet, exercises, size = 1)## # A tibble: 4 x 6
## id diet exercises t1 t2 t3
## <int> <fct> <fct> <dbl> <dbl> <dbl>
## 1 4 no no 11.1 9.5 11.1
## 2 22 no yes 10.2 11.8 17.4
## 3 5 yes no 11.6 13.4 13.9
## 4 23 yes yes 12.7 12.7 15.1# Rassemblez les colonnes t1, t2 et t3 en format long.
# Convertir l'identifiant et le temps en facteurs
weightloss <- weightloss %>%
gather(key = "time", value = "score", t1, t2, t3) %>%
convert_as_factor(id, time)
# Inspecter quelques lignes aléatoires des données par groupes
set.seed(123)
weightloss %>% sample_n_by(diet, exercises, time, size = 1)## # A tibble: 12 x 5
## id diet exercises time score
## <fct> <fct> <fct> <fct> <dbl>
## 1 4 no no t1 11.1
## 2 10 no no t2 10.7
## 3 5 no no t3 12.3
## 4 23 no yes t1 10.2
## 5 24 no yes t2 13.2
## 6 13 no yes t3 15.8
## # … with 6 more rowsStatistiques descriptives
Regroupez les données par exercises, diet et time, puis calculez quelques statistiques descriptives de la variable score: moyenne et sd (écart type)
weightloss %>%
group_by(exercises, diet, time) %>%
get_summary_stats(score, type = "mean_sd")## # A tibble: 12 x 7
## diet exercises time variable n mean sd
## <fct> <fct> <fct> <chr> <dbl> <dbl> <dbl>
## 1 no no t1 score 12 10.9 0.868
## 2 no no t2 score 12 11.6 1.30
## 3 no no t3 score 12 11.4 0.935
## 4 yes no t1 score 12 11.7 0.938
## 5 yes no t2 score 12 12.4 1.42
## 6 yes no t3 score 12 13.8 1.43
## # … with 6 more rowsVisualisation
Créez des boxplots de scores de perte de poids par groupes d’exercices, colorés par des points de temps et faire un facet en fonction du diète:
bxp <- ggboxplot(
weightloss, x = "exercises", y = "score",
color = "time", palette = "jco",
facet.by = "diet", short.panel.labs = FALSE
)
bxp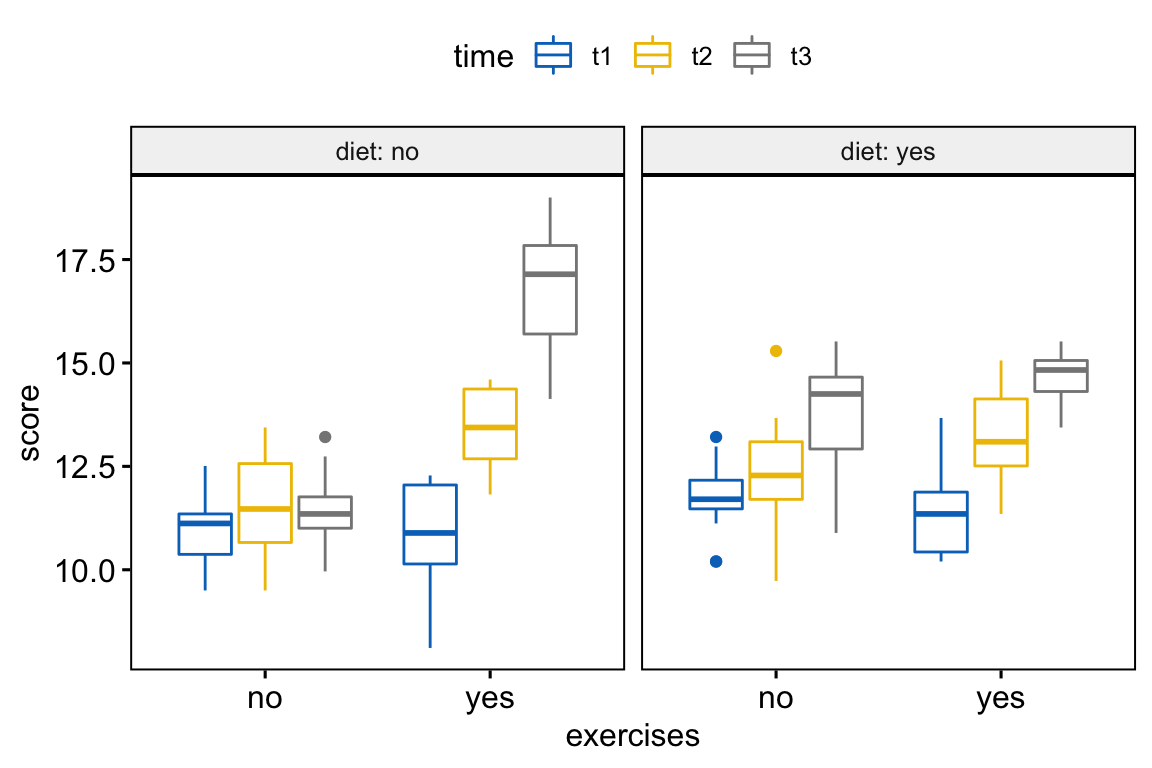
Vérifier les hypothèses
Valeurs aberrantes
weightloss %>%
group_by(diet, exercises, time) %>%
identify_outliers(score)## # A tibble: 5 x 7
## diet exercises time id score is.outlier is.extreme
## <fct> <fct> <fct> <fct> <dbl> <lgl> <lgl>
## 1 no no t3 2 13.2 TRUE FALSE
## 2 yes no t1 1 10.2 TRUE FALSE
## 3 yes no t1 3 13.2 TRUE FALSE
## 4 yes no t1 4 10.2 TRUE FALSE
## 5 yes no t2 10 15.3 TRUE FALSEIl n’y avait pas de valeurs extrêmes aberrantes.
Hypothèse de normalité
Calculer le test de Shapiro-Wilk pour chaque combinaison de niveaux des facteurs:
weightloss %>%
group_by(diet, exercises, time) %>%
shapiro_test(score)## # A tibble: 12 x 6
## diet exercises time variable statistic p
## <fct> <fct> <fct> <chr> <dbl> <dbl>
## 1 no no t1 score 0.917 0.264
## 2 no no t2 score 0.957 0.743
## 3 no no t3 score 0.965 0.851
## 4 no yes t1 score 0.922 0.306
## 5 no yes t2 score 0.912 0.229
## 6 no yes t3 score 0.953 0.674
## # … with 6 more rowsLe score de perte de poids était normalement distribué (p > 0,05), tel qu’évalué par le test de normalité de Shapiro-Wilk.
Créer un QQ plot pour chaque cellule du plan:
ggqqplot(weightloss, "score", ggtheme = theme_bw()) +
facet_grid(diet + exercises ~ time, labeller = "label_both")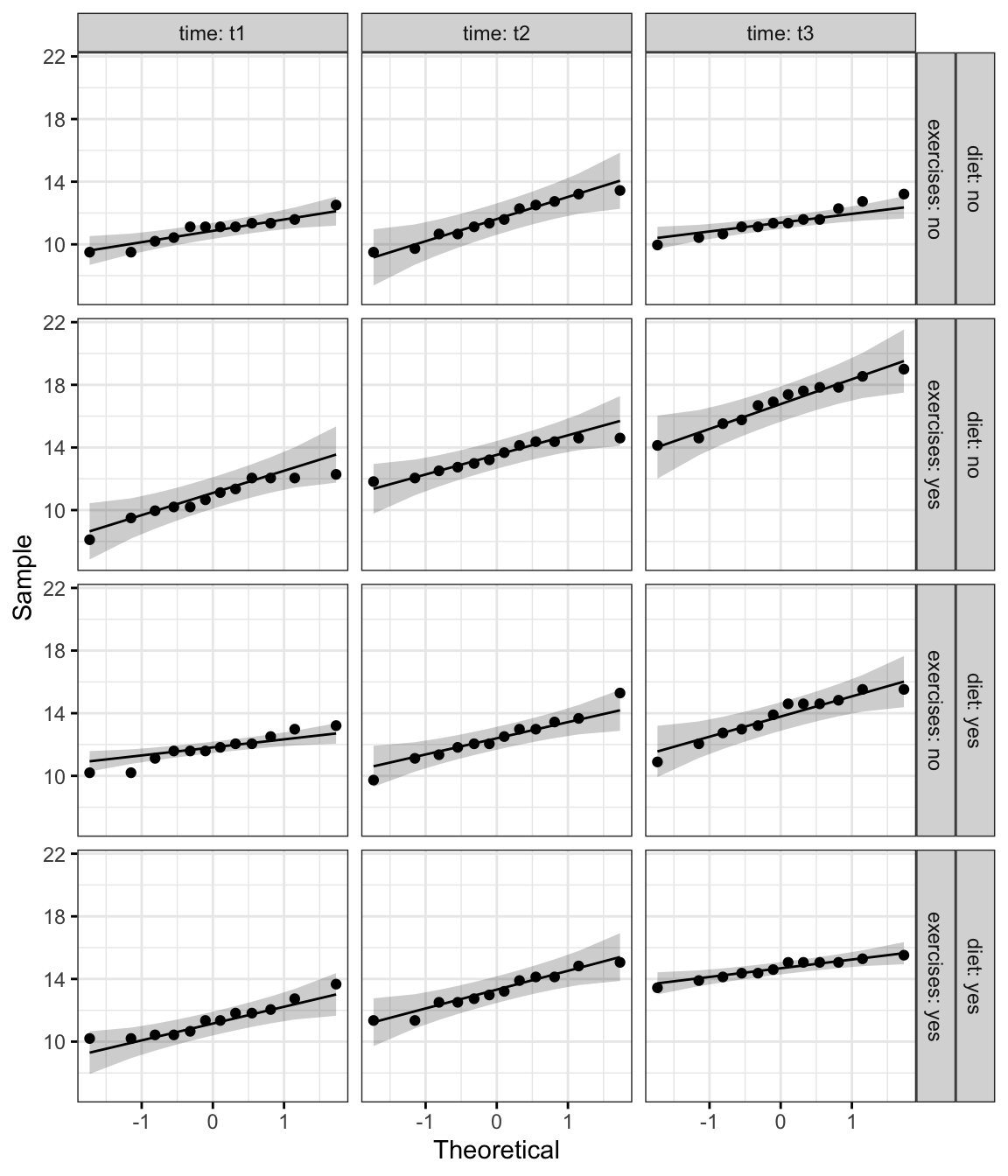
D’après le graphique ci-dessus, comme tous les points se situent approximativement le long de cette ligne de référence, nous pouvons supposer une normalité.
L’hypothèse d’homogénéité des variances
Calculer le test de Levene après avoir regroupé les données par catégories diet et time:
weightloss %>%
group_by(diet, time) %>%
levene_test(score ~ exercises)## # A tibble: 6 x 6
## diet time df1 df2 statistic p
## <fct> <fct> <int> <int> <dbl> <dbl>
## 1 no t1 1 22 2.44 0.132
## 2 no t2 1 22 0.691 0.415
## 3 no t3 1 22 2.87 0.105
## 4 yes t1 1 22 0.376 0.546
## 5 yes t2 1 22 0.0574 0.813
## 6 yes t3 1 22 5.14 0.0336
Les variances étaient homogènes pour toutes les cellules (p > 0,05), à l’exception de la condition avec régime diet:yes au temps t3 (p = 0,034), tel qu’évalué par le test d’homogénéité de la variance de Levene.
Notez que, si vous n’avez pas d’homogénéité des variances, vous pouvez essayer de transformer la variable-réponse (dépendante) pour corriger l’inégalité des variances.
Si la taille de l’échantillon des groupes est (approximativement) égale, exécutez quand même l’ANOVA, à trois facteurs mixtes, parce qu’elle est assez robuste à l’hétérogénéité de la variance dans ces circonstances.
Il est également possible d’effectuer un test ANOVA robuste à l’aide du package R WRS2.
Hypothèse de sphéricité
Comme mentionné dans la section ANOVA à deux facteurs mixtes, le test de sphéricité de Mauchly et les corrections de sphéricité sont effectués en interne en utilisant la fonction R anova_test() et get_anova_table() [paquet rstatix].
Calculs
res.aov <- anova_test(
data = weightloss, dv = score, wid = id,
between = exercises, within = c(diet, time)
)
get_anova_table(res.aov)## ANOVA Table (type II tests)
##
## Effect DFn DFd F p p<.05 ges
## 1 exercises 1 22 38.771 2.88e-06 * 0.284
## 2 diet 1 22 7.912 1.00e-02 * 0.028
## 3 time 2 44 82.199 1.38e-15 * 0.541
## 4 exercises:diet 1 22 51.698 3.31e-07 * 0.157
## 5 exercises:time 2 44 26.222 3.18e-08 * 0.274
## 6 diet:time 2 44 0.784 4.63e-01 0.013
## 7 exercises:diet:time 2 44 9.966 2.69e-04 * 0.147
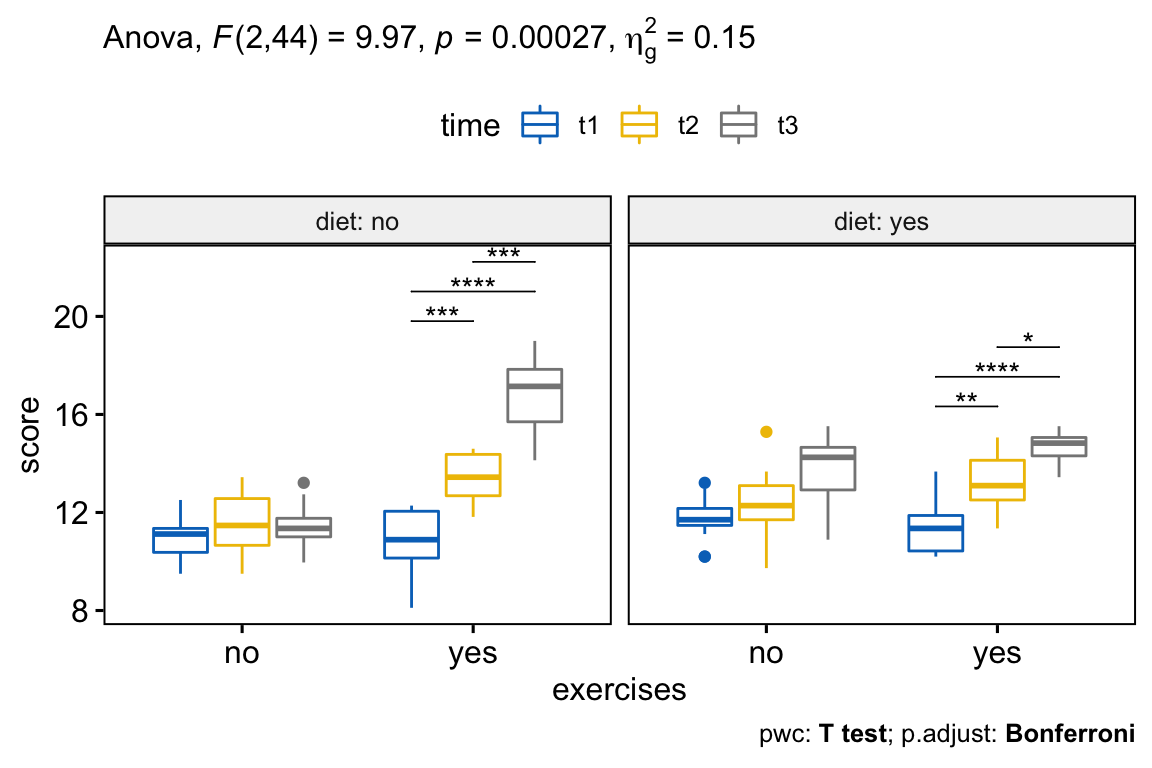
D’après les résultats ci-dessus, on peut voir qu’il existe des interactions statistiquement significatives entre les variables execises, diet et time, F(2, 44) = 9,96, p = 0,00027.
Notez que, si l’interaction à trois facteurs n’est pas statistiquement significative, vous devez consulter les interactions à deux facteurs dans le résultat.
Dans notre exemple, il y avait des interactions, à deux facteurs, statistiquement significative exercises:diet (p < 0,0001), et exercises:time (p < 0,0001). L’interaction diet*time n’était pas statistiquement significative (p = 0.46).
Tests post-hoc
S’il y a un effet significatif d’interaction à trois facteurs, vous pouvez le décomposer en:
- Interaction à deux facteurs : exécuter l’interaction, à deux facteurs, à chaque niveau de la troisième variable,
- Effet principal : exécuter un modèle, à un facteur, à chaque niveau de la deuxième variable, et
- Comparaisons par paires : effectuer des comparaisons par paires ou d’autres comparaisons post-hoc si nécessaire.
Si vous n’avez pas d’interaction à trois facteurs statistiquement significative, vous devez déterminer si vous avez une interaction à deux facteurs statistiquement significative à partir du résultat de l’ANOVA. Vous pouvez suivre une interaction significative à deux facteurs par des analyses simples des effets principaux et des comparaisons par paires entre les groupes si nécessaire.
Dans cette section, nous décrirons la procédure à suivre pour une interaction significative à trois facteurs.
Calculer l’interaction à deux facteurs
Dans cet exemple, nous allons considérer l’interaction diet*time à chaque niveau de exercises. Regroupez les données par exercises et analysez l’interaction entre diet et time:
# ANOVA à deux facteurs au niveau de chaque groupe d'exercices
two.way <- weightloss %>%
group_by(exercises) %>%
anova_test(dv = score, wid = id, within = c(diet, time))
two.way## # A tibble: 2 x 2
## exercises anova
## <fct> <list>
## 1 no <anov_tst>
## 2 yes <anov_tst># Extraire le tableau anova
get_anova_table(two.way)## # A tibble: 6 x 8
## exercises Effect DFn DFd F p `p<.05` ges
## <fct> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl>
## 1 no diet 1 11 56.4 1.18e- 5 * 0.262
## 2 no time 2 22 5.90 9.00e- 3 * 0.181
## 3 no diet:time 2 22 2.91 7.60e- 2 "" 0.09
## 4 yes diet 1 11 8.60 1.40e- 2 * 0.066
## 5 yes time 2 22 148. 1.73e-13 * 0.746
## 6 yes diet:time 2 22 7.81 3.00e- 3 * 0.216Il y avait une interaction statistiquement significative entre l’alimentation et le temps pour le groupe exercises:yes, F(2, 22) = 7,81, p = 0,0027, mais pas pour le groupe exercices:no, F(2, 22) = 2,91, p = 0,075.
Il est à noter que la significativité statistique d’une interaction simple, à deux facteurs, a été acceptée à un niveau alpha ajusté de Bonferroni de 0,025. Cela correspond au niveau actuel auquel vous déclarez une significativité statistique (c.-à-d. p < 0,05) divisé par le nombre d’interactions à deux facteurs que vous analysées (c.-à-d. 2).
Calculer l’effet principal
Une interaction à deux facteurs statistiquement significative peut être suivie par une analyse des effets principaux.
Dans notre exemple, vous pourriez donc étudier l’effet de time (temps) sur le score de perte de poids à chaque niveau de diet (régime) et/ou étudier l’effet de diet à chaque niveau de time.
Notez que vous n’aurez besoin de le faire que pour l’interaction à deux facteurs pour le groupe “exercises:yes”, car c’était la seule interaction statistiquement significative.
Regroupez les données par exercises et diet, et analysez l’effet principal de time:
time.effect <- weightloss %>%
group_by(exercises, diet) %>%
anova_test(dv = score, wid = id, within = time) %>%
get_anova_table()
time.effect %>% filter(exercises == "yes")## # A tibble: 2 x 9
## diet exercises Effect DFn DFd F p `p<.05` ges
## <fct> <fct> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl>
## 1 no yes time 2 22 78.8 9.30e-11 * 0.801
## 2 yes yes time 2 22 30.9 4.06e- 7 * 0.655
Dans le tableau ci-dessus, nous n’avons besoin des résultats que pour exercises = yes. Le seuil de significativité statistique d’un effet principal est de 0,25 après ajustement de Bonferroni, soit 0,05 divisé par le nombre d’effets principaux analysés (c’est-à-dire 2).
L’effet principal du temps sur le score de perte de poids était statistiquement significatif sous condition d’exercices pour les deux groupes diet:no (F(2,22) = 78,81, p < 0,0001) et diet:yes (F(2,22) = 30,92, p < 0,0001).
Calculer les comparaisons entre groupes
Un effet principal statistiquement significatif peut être suivi de multiples comparaisons par paires pour déterminer quelles moyennes de groupe sont différentes.
Rappelez-vous que vous n’aurez qu’à vous concentrer sur les résultats de la comparaison par paires pour exercises:yes.
Regroupez les données par exercisesetdiet, et effectuez des comparaisons par paires entre les points detime` en utilisant la correction de Bonferroni. Le t-test apparié est utilisé:
# calculer des comparaisons par paires
pwc <- weightloss %>%
group_by(exercises, diet) %>%
pairwise_t_test(
score ~ time, paired = TRUE,
p.adjust.method = "bonferroni"
) %>%
select(-statistic, -df) # Supprimer les détails
# Concentrez-vous sur les résultats du groupe `exercises:yes`
pwc %>% filter(exercises == "yes") %>%
select(-p) # Enlever la colonne p## # A tibble: 6 x 9
## diet exercises .y. group1 group2 n1 n2 p.adj p.adj.signif
## <fct> <fct> <chr> <chr> <chr> <int> <int> <dbl> <chr>
## 1 no yes score t1 t2 12 12 0.000741 ***
## 2 no yes score t1 t3 12 12 0.0000000121 ****
## 3 no yes score t2 t3 12 12 0.000257 ***
## 4 yes yes score t1 t2 12 12 0.01 **
## 5 yes yes score t1 t3 12 12 0.00000124 ****
## 6 yes yes score t2 t3 12 12 0.02 *
Toutes les comparaisons par paires ont été effectuées entre les différents temps dans des conditions d’exercices (c.-à-d. exercises:yes) pour les essais diet:no (pas de régime alimentaire) et diet:yes ( avec régime alimentaire). Un ajustement de Bonferroni a été appliqué.
Le score moyen de perte de poids était significativement différent dans toutes les comparaisons à tous les temps lorsque des exercices sont effectués (p < 0,05).
Rapporter
Une ANOVA mixte à trois facteurs a été effectuée pour évaluer les effets de l’alimentation, de l’exercice et du temps sur la perte de poids.
Il n’y avait pas de valeurs extrêmes aberrantes, telles qu’évaluées par la méthode des boxplots. Les données étaient normalement distribuées, telles qu’évaluées par le test de normalité de Shapiro-Wilk (p > 0,05). L’homogénéité des variances (p > 0,05) a été évaluée par le test d’homogénéité des variances de Levene. Pour l’effet d’interaction à trois facteurs, le test de sphéricité de Mauchly indique que l’hypothèse de sphéricité est respectée (p > 0,05).
Il y a une interaction statistiquement significative entre les exercices, le régime alimentaire et le temps F(2, 44) = 9,96, p < 0,001.
Pour les interactions, à deux facteurs, et les effets principaux, un ajustement de Bonferroni a été appliqué, résultant à un seuil d’acceptance de p < 0,025 pour la significativité statistique.
Il y avait une interaction statistiquement significative entre l’alimentation et le temps pour le groupe exercises:yes, F(2, 22) = 7,81, p = 0,0027, mais pas pour le groupe exercices:no, F(2, 22) = 2,91, p = 0,075.
L’effet principal du temps sur le score de perte de poids était statistiquement significatif sous condition d’exercices pour les deux groupes diet:no (F(2,22) = 78,81, p < 0,0001) et diet:yes (F(2,22) = 30,92, p < 0,0001).
Toutes les comparaisons par paires ont été effectuées entre les différents temps dans des conditions d’exercices (c.-à-d. exercises:yes) pour les essais diet:no (pas de régime alimentaire) et diet:yes ( avec régime alimentaire). Un ajustement de Bonferroni a été appliqué. Le score moyen de perte de poids était significativement différent dans toutes les comparaisons à tous les temps lorsque des exercices sont effectués (p < 0,05).
# Visualisation : Boxplots avec p-values
pwc <- pwc %>% add_xy_position(x = "exercises")
pwc.filtered <- pwc %>% filter(exercises == "yes")
bxp +
stat_pvalue_manual(pwc.filtered, tip.length = 0, hide.ns = TRUE) +
labs(
subtitle = get_test_label(res.aov, detailed = TRUE),
caption = get_pwc_label(pwc)
)
Résumé
Cet article décrit comment calculer et interpréter l’ANOVA mixte dans R. Nous expliquons également les hypothèses faites par les tests ANOVA mixtes et fournissons des exemples pratiques de codes R pour vérifier si les hypothèses des tests sont respectées.
Version:
 English
English

No Comments