Cet article décrit comment faire un t-test dans R (ou dans Rstudio). Vous apprendrez à:
- Exécuter un test t dans R en utilisant les fonctions suivantes :
t_test()[paquet rstatix] : une enveloppe autour de la fonction de base Rt.test(). Le résultat est une data frame, qui peut être facilement ajoutée à un graphique en utilisant le paquet Rggpubr.t.test()[paquet stats] : fonction R de base pour effectuer un test t.
- Interpréter et rapporter le test t
- Ajouter des p-values et des niveaux de significativité à un graphe
- Calculez et rapportez la taille de l’effet du test t en utilisant le d de Cohen. La statistique “d” redéfinit la différence de moyennes comme le nombre d’écarts-types qui sépare ces moyennes. Les tailles d’effet conventionnelles des tests T, proposées par Cohen, sont : 0,2 (petit effet), 0,5 (effet modéré) et 0,8 (effet important) (Cohen 1998).
Nous fournirons des exemples de code R pour exécuter les différents types de test t dans R, notamment le:
- test t à échantillon unique
- test t à deux échantillons (aussi appelé test t indépendant ou test t non apparié)
- test t apparié (aussi appelé test t dépendant ou test t apparié par paires)
Sommaire:
Livre Apparenté
Pratique des Statistiques dans R II - Comparaison de Groupes: Variables NumériquesPrérequis
Assurez-vous d’avoir installé les paquets R suivants:
tidyversepour la manipulation et la visualisation des donnéesggpubrpour créer facilement des graphiques prêts à la publicationrstatixcontient des fonctions R facilitant les analyses statistiques.datarium: contient les jeux de données requis pour ce chapitre.
Commencez par charger les packages requis suivants:
library(tidyverse)
library(ggpubr)
library(rstatix)Test t pour échantillon unique
Données de démonstration
Jeu de données de démonstration : mice [package datarium]. Contient le poids de 10 souris:
# Charger et inspecter les données
data(mice, package = "datarium")
head(mice, 3)## # A tibble: 3 x 2
## name weight
## <chr> <dbl>
## 1 M_1 18.9
## 2 M_2 19.5
## 3 M_3 23.1Nous voulons savoir si le poids moyen des souris diffère de 25 g (test bilatéral)
Statistiques descriptives
Calculer quelques statistiques sommaires : nombre de sujets, moyenne et sd (écart-type)
mice %>% get_summary_stats(weight, type = "mean_sd")## # A tibble: 1 x 4
## variable n mean sd
## <chr> <dbl> <dbl> <dbl>
## 1 weight 10 20.1 1.90Calculs
Utilisation de la fonction de base R
res <- t.test(mice$weight, mu = 25)
res##
## One Sample t-test
##
## data: mice$weight
## t = -8, df = 9, p-value = 2e-05
## alternative hypothesis: true mean is not equal to 25
## 95 percent confidence interval:
## 18.8 21.5
## sample estimates:
## mean of x
## 20.1Dans le résultat ci-dessus :
test la valeur de la statistique du test t (t = -8.105),dfest le degré de liberté (df= 9),p-valueest le niveau de significativité du test t (p-value = 1.99510^{-5}).conf.intest l’intervalle de confiance de la moyenne à 95% (conf.int = [18.7835, 21.4965]);sample estimatesest la valeur moyenne de l’échantillon (moyenne = 20.14).
Utilisation du paquet rstatix
Nous utiliserons le système pipe-compatible t_test() function [rstatix package], a wrapper around the R base function t.test(). Les résultats peuvent être facilement ajoutés à un graphique en utilisant le paquet Rggpubr.
stat.test <- mice %>% t_test(weight ~ 1, mu = 25)
stat.test## # A tibble: 1 x 7
## .y. group1 group2 n statistic df p
## * <chr> <chr> <chr> <int> <dbl> <dbl> <dbl>
## 1 weight 1 null model 10 -8.10 9 0.00002Les résultats ci-dessus montrent les composantes suivantes:
.y.: la variable-réponse utilisée dans le test.group1,group2: en général, les groupes comparés dans les tests par paires. Ici, nous avons le modèle nul (test pour échantillon unique).statistic: statistique du test (valeur t) utilisée pour calculer la p-value.df: degrés de liberté.p: p-value.
Vous pouvez obtenir un résultat détaillé en spécifiant l’option detailed = TRUE dans la fonction t_test().
mice %>% t_test(weight ~ 1, mu = 25, detailed = TRUE)## # A tibble: 1 x 12
## estimate .y. group1 group2 n statistic p df conf.low conf.high method alternative
## * <dbl> <chr> <chr> <chr> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
## 1 20.1 weight 1 null model 10 -8.10 0.00002 9 18.8 21.5 T-test two.sidedInterprétation
La p-value du test est 210^{-5}, ce qui est inférieure au seuil de significativité alpha = 0,05. Nous pouvons conclure que le poids moyen des souris est significativement différent de 25g avec une p-value = 210^{-5}.
Taille de l’effet
Pour calculer la taille de l’effet, appelée d de Cohen, du test t pour échantillon unique, vous devez diviser la différence moyenne par l’écart type de la différence, comme indiqué ci-dessous. Notez que, ici: sd(x-mu) = sd(x).
La formule du d de Cohen:
\[
d = \frac{m-\mu}{s}
\]
- \(m\) est la moyenne de l’échantillon
- \(s\) est l’écart-type de l’échantillon avec les degrés de liberté \(n-1\)
- \(\mu\) est la moyenne théorique à laquelle la moyenne de notre échantillon est comparée (la valeur par défaut est mu = 0).
Calculs:
mice %>% cohens_d(weight ~ 1, mu = 25)## # A tibble: 1 x 6
## .y. group1 group2 effsize n magnitude
## * <chr> <chr> <chr> <dbl> <int> <ord>
## 1 weight 1 null model -2.56 10 largeRappelons que les taille de l’effet conventionnelles du test t, proposé par Cohen J. (1998), sont : 0,2 (petit effet), 0,5 (effet modéré) et 0,8 (effet important) (Cohen 1998). Comme la taille de l’effet, d, est de 2,56, vous pouvez conclure qu’il y a un effet important.
Rapports
Nous pourrions rapporter le résultat comme suit:
Un test t pour échantillon unique a été calculé pour déterminer si le poids moyen des souris incluses était différent du poids moyen normal de la population (25 g).
Le poids moyen mesuré des souris (20,14 +/- 1,94) était statistiquement significativement inférieur au poids moyen normal de la population 25 (t(9) = -8,1, p < 0,0001, d = 2,56) ; où t(9) est une notation courte pour une statistique t qui a 9 degrés de liberté.
Les résultats peuvent être visualisés à l’aide d’un box plot ou d’un diagramme de densité.
Box Plot
Créer un boxplot pour visualiser la distribution du poids des souris. Ajoutez également des points jitter pour montrer les observations individuelles. Le gros point représente le point moyen.
# Créer le box-plot
bxp <- ggboxplot(
mice$weight, width = 0.5, add = c("mean", "jitter"),
ylab = "Weight (g)", xlab = FALSE
)
# Ajouter les niveaux de significativité
bxp + labs(subtitle = get_test_label(stat.test, detailed = TRUE))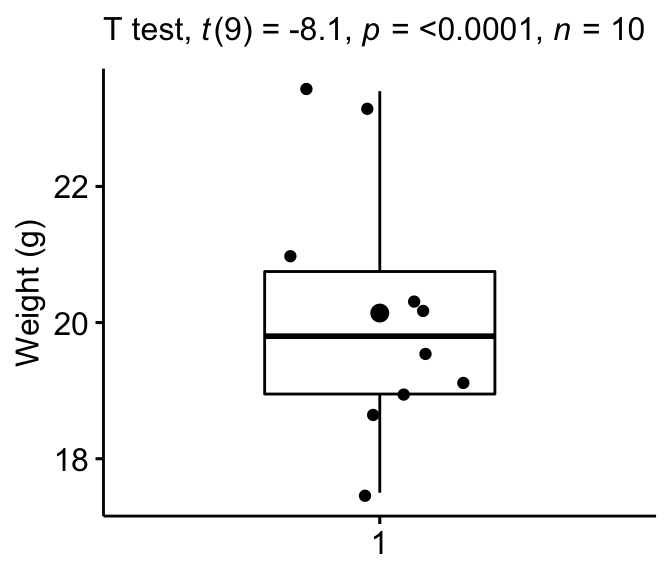
Diagramme de densité
Créer un graphe de densité avec p-value:
- La ligne rouge correspond à la moyenne observée
- La ligne bleue correspond à la moyenne théorique
ggdensity(mice, x = "weight", rug = TRUE, fill = "lightgray") +
scale_x_continuous(limits = c(15, 27)) +
stat_central_tendency(type = "mean", color = "red", linetype = "dashed") +
geom_vline(xintercept = 25, color = "blue", linetype = "dashed") +
labs(subtitle = get_test_label(stat.test, detailed = TRUE))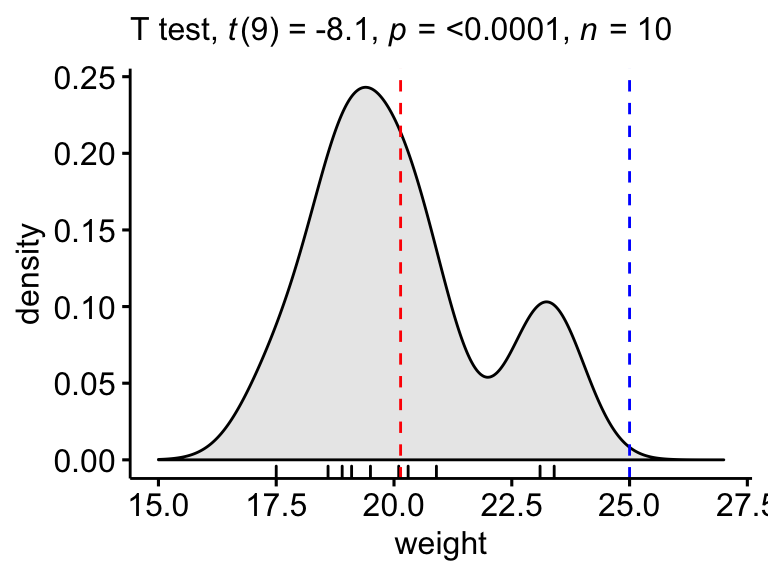
Test t à deux échantillons
Le test t à deux échantillons est également connu sous le nom de test t indépendant. Le t-test pour échantillons indépendants se présente sous deux formes différentes:
- le test t standard de Student, qui suppose que la variance des deux groupes est égale.
- le test t de Welch, qui est moins restrictif que le test original de Student. Il s’agit du test où vous ne présumez pas que la variance est la même dans les deux groupes, ce qui donne les degrés de liberté fractionnaires suivants.
Les deux méthodes donnent des résultats très semblables, à moins que la taille des groupes et les écarts-types ne soient très différents.
Données de démonstration
Jeu de données de démonstration : genderweight [package datarium] contenant le poids de 40 individus (20 femmes et 20 hommes).
Charger les données et afficher quelques lignes aléatoires par groupes:
# Charger les données
data("genderweight", package = "datarium")
# Afficher un échantillon des données par groupe
set.seed(123)
genderweight %>% sample_n_by(group, size = 2)## # A tibble: 4 x 3
## id group weight
## <fct> <fct> <dbl>
## 1 6 F 65.0
## 2 15 F 65.9
## 3 29 M 88.9
## 4 37 M 77.0Nous voulons savoir si les poids moyens sont différents d’un groupe à l’autre.
Statistiques descriptives
Calculer quelques statistiques descriptives par groupe : moyenne et sd (écart-type)
genderweight %>%
group_by(group) %>%
get_summary_stats(weight, type = "mean_sd")## # A tibble: 2 x 5
## group variable n mean sd
## <fct> <chr> <dbl> <dbl> <dbl>
## 1 F weight 20 63.5 2.03
## 2 M weight 20 85.8 4.35Calculs
Rappelons que, par défaut, R calcule le test t de Welch, qui est le plus prudent. Il s’agit du test où vous ne présumez pas que la variance est la même dans les deux groupes, ce qui donne les degrés de liberté fractionnaires suivants. Si vous voulez supposer l’égalité des variances (test t de Student), spécifiez l’option var.equal = TRUE.
Utilisation de la fonction de base R
res <- t.test(weight ~ group, data = genderweight)
res##
## Welch Two Sample t-test
##
## data: weight by group
## t = -20, df = 30, p-value <2e-16
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -24.5 -20.1
## sample estimates:
## mean in group F mean in group M
## 63.5 85.8Dans le résultat ci-dessus :
test la valeur de la statistique du test t (t = -20.79),dfest le degré de liberté (df= 26.872),p-valueest le niveau de significativité du test t (p-value = 4.29810^{-18}).conf.intest l’intervalle de confiance de la différence de moyennes à 95% (conf.int = [-24.5314, -20.1235]);sample estimatesest la valeur moyenne de l’échantillon (moyenne = 63.499, 85.826).
Utilisation du paquet rstatix
stat.test <- genderweight %>%
t_test(weight ~ group) %>%
add_significance()
stat.test## # A tibble: 1 x 9
## .y. group1 group2 n1 n2 statistic df p p.signif
## <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <chr>
## 1 weight F M 20 20 -20.8 26.9 4.30e-18 ****Les résultats ci-dessus montrent les composantes suivantes:
.y.: la variable y utilisée dans le test.group1,group2: les groupes comparés dans les tests par paires.statistic: Statistique de test utilisée pour calculer la p-value.df: degrés de liberté.p: p-value.
Notez que, vous pouvez obtenir un résultat détaillé en spécifiant l’option detailed = TRUE.
genderweight %>%
t_test(weight ~ group, detailed = TRUE) %>%
add_significance()## # A tibble: 1 x 16
## estimate estimate1 estimate2 .y. group1 group2 n1 n2 statistic p df conf.low conf.high method alternative p.signif
## <dbl> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <chr> <chr> <chr>
## 1 -22.3 63.5 85.8 weight F M 20 20 -20.8 4.30e-18 26.9 -24.5 -20.1 T-test two.sided ****Interprétation
La p-value du test est 4.310^{-18}, ce qui est inférieur au seuil de significativité alpha = 0,05. Nous pouvons conclure que le poids moyen des hommes est significativement différent de celui des femmes avec une p-value = 4.310^{-18}.
Taille de l’effet
d de Cohen pour le test t de Student
Il existe plusieurs versions du d de Cohen pour le test t de Student. La version la plus couramment utilisée de la taille de l’effet du test t de Student, qui compare deux groupes (\(A\) et \(B\)), est calculée en divisant la différence des moyennes des deux groupes par l’écart-type commun.
La formule du d de Cohen:
\[
d = \frac{m_A - m_B}{SD_{pooled}}
\]
où,
- \(m_A\) et \(m_B\) représentent la valeur moyenne des groupes A et B, respectivement.
- \(n_A\) et \(n_B\) représentent les tailles des groupes A et B, respectivement.
- \(SD_{pooled}\) est un estimateur de l’écart-type mis en commun des deux groupes. Il peut être calculé comme suit :
\[
SD_{pooled} = \sqrt{\frac{\sum{(x-m_A)^2}+\sum{(x-m_B)^2}}{n_A+n_B-2}}
\]
Calculs. Si l’option var.equal = TRUE, alors la SD groupée est utilisée lors du calcul du d de Cohen.
genderweight %>% cohens_d(weight ~ group, var.equal = TRUE)## # A tibble: 1 x 7
## .y. group1 group2 effsize n1 n2 magnitude
## * <chr> <chr> <chr> <dbl> <int> <int> <ord>
## 1 weight F M -6.57 20 20 largeL’ampleur de l’effet est importante, d = 6,57.
Notez que, pour un échantillon de petite taille (< 50), le d de Cohen a tendance à gonfler les résultats. Il existe une version corrigée de Hedge du d de Cohen (???), qui réduit la taille de l’effet pour les petits échantillons de quelques points de pourcentage. La correction est introduite en multipliant la valeur habituelle de d par (N-3)/(N-2.25) (pour le test t non apparié) et par (n1-2)/(n1-1.25) pour le test t apparié ; où N est la taille totale des deux groupes comparés (N = n1 + n2).
Le d de Cohen pour le test t de Welch
Le test de Welch est une variante du test t utilisé lorsque l’égalité de variance ne peut être présumée. La valeur de l’effet peut être calculée en divisant la différence moyenne entre les groupes par l’écart type “moyen”.
La formule du d de Cohen:
\[
d = \frac{m_A - m_B}{\sqrt{(Var_1 + Var_2)/2}}
\]
où,
- \(m_A\) et \(m_B\) représentent la valeur moyenne des groupes A et B, respectivement.
- \(Var_1\) et \(Var_2\) sont la variance des deux groupes.
Calculs:
genderweight %>% cohens_d(weight ~ group, var.equal = FALSE)## # A tibble: 1 x 7
## .y. group1 group2 effsize n1 n2 magnitude
## * <chr> <chr> <chr> <dbl> <int> <int> <ord>
## 1 weight F M -6.57 20 20 largeNotez que, lorsque la taille des groupes est égale et que les variances des groupes sont homogènes, le d de Cohen pour les tests t standard de Student et de Welch sont identiques.
Rapporter
Nous pourrions rapporter le résultat comme suit:
Le poids moyen dans le groupe des femmes était de 63,5 (SD = 2,03), alors que la moyenne dans le groupe des hommes était de 85,8 (SD = 4,3). Le test t de Welch a montré que la différence était statistiquement significative, t(26.9) = -20.8, p < 0.0001, d = 6.57 ; où, t(26.9) est une notation abrégée pour une statistique t de Welch qui a 26.9 degrés de liberté.
Visualiser les résultats:
# Créer un box-plot
bxp <- ggboxplot(
genderweight, x = "group", y = "weight",
ylab = "Weight", xlab = "Groups", add = "jitter"
)
# Ajouter la p-value et les niveaux de significativité
stat.test <- stat.test %>% add_xy_position(x = "group")
bxp +
stat_pvalue_manual(stat.test, tip.length = 0) +
labs(subtitle = get_test_label(stat.test, detailed = TRUE))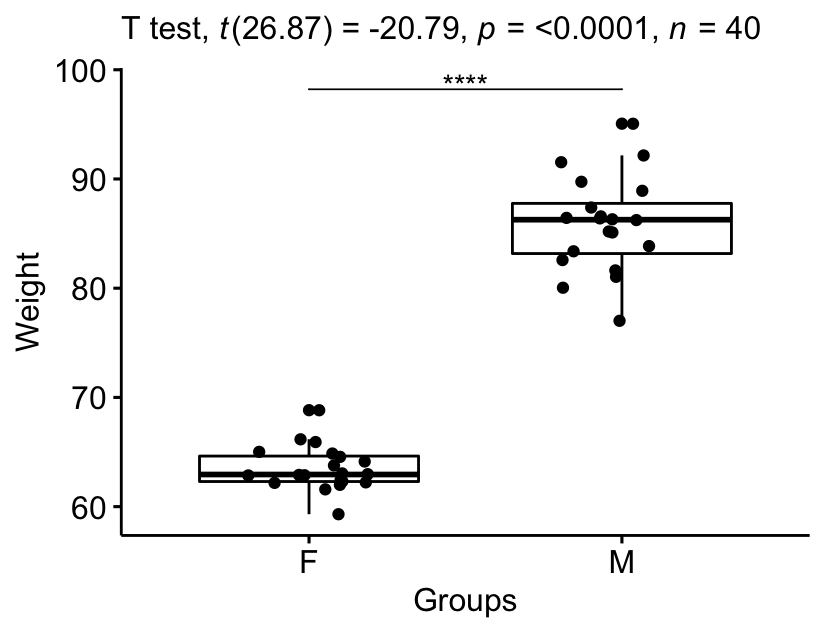
Test-t apparié
Données de démonstration
Ici, nous utiliserons un jeu de données de démonstration mice2 [package datarium], qui contient le poids de 10 souris avant et après le traitement.
# Format large
data("mice2", package = "datarium")
head(mice2, 3)## id before after
## 1 1 187 430
## 2 2 194 404
## 3 3 232 406# Transformez en données longues :
# rassembler les valeurs de `before` (avant) et `after` (après) dans la même colonne
mice2.long <- mice2 %>%
gather(key = "group", value = "weight", before, after)
head(mice2.long, 3)## id group weight
## 1 1 before 187
## 2 2 before 194
## 3 3 before 232Nous voulons savoir s’il y a une différence significative dans les poids moyens après le traitement ?
Statistiques descriptives
Calculer quelques statistiques descriptives (moyenne et sd) par groupe:
mice2.long %>%
group_by(group) %>%
get_summary_stats(weight, type = "mean_sd")## # A tibble: 2 x 5
## group variable n mean sd
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 after weight 10 400. 30.1
## 2 before weight 10 201. 20.0Calculs
Utilisation de la fonction de base R
res <- t.test(weight ~ group, data = mice2.long, paired = TRUE)
resDans le résultat ci-dessus :
test la valeur de la statistique du test t (t = -20.79),dfest le degré de liberté (df= 26.872),p-valueest le niveau de significativité du test t (p-value = 4.29810^{-18}).conf.intest l’intervalle de confiance de la moyenne des différences à 95% (conf.int = [-24.5314, -20.1235]);sample estimatesest la moyenne des différences (moyenne = 63.499, 85.826).
Utilisation du paquet rstatix
stat.test <- mice2.long %>%
t_test(weight ~ group, paired = TRUE) %>%
add_significance()
stat.test## # A tibble: 1 x 9
## .y. group1 group2 n1 n2 statistic df p p.signif
## <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <chr>
## 1 weight after before 10 10 25.5 9 0.00000000104 ****Les résultats ci-dessus montrent les composantes suivantes:
.y.: la variable y utilisée dans le test.group1,group2: les groupes comparés dans les tests par paires.statistic: Statistique de test utilisée pour calculer la p-value.df: degrés de liberté.p: p-value.
Notez que, vous pouvez obtenir un résultat détaillé en spécifiant l’option detailed = TRUE.
mice2.long %>%
t_test(weight ~ group, paired = TRUE, detailed = TRUE) %>%
add_significance()## # A tibble: 1 x 14
## estimate .y. group1 group2 n1 n2 statistic p df conf.low conf.high method alternative p.signif
## <dbl> <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <chr> <chr> <chr>
## 1 199. weight after before 10 10 25.5 0.00000000104 9 182. 217. T-test two.sided ****Interprétation
La p-value du test est 1.0410^{-9}, ce qui est inférieur au seuil de significativité alpha = 0,05. Nous pouvons alors rejeter l’hypothèse nulle et conclure que le poids moyen des souris avant traitement est significativement différent du poids moyen après traitement avec une p-value = 1.0410^{-9}.
Taille de l’effet
La taille de l’effet d’un test t pour échantillons appariés peut être calculée en divisant la différence moyenne par l’écart-type de la différence, comme indiqué ci-dessous.
La formule du d de Cohen:
\[
d = \frac{mean_D}{SD_D}
\]
Où D est la différence entre les valeurs des échantillons appariés.
Calculs:
mice2.long %>% cohens_d(weight ~ group, paired = TRUE)## # A tibble: 1 x 7
## .y. group1 group2 effsize n1 n2 magnitude
## * <chr> <chr> <chr> <dbl> <int> <int> <ord>
## 1 weight after before 8.08 10 10 largeLa taille de l’effet est importante, d de Cohen = 8,07.
Rapporter
Nous pourrions rapporter les résultats comme suit : Le poids moyen des souris a augmenté de façon significative après le traitement, t(9) = 25,5, p < 0,0001, d = 8,07.
Visualiser les résultats:
# Créer un box plot
bxp <- ggpaired(mice2.long, x = "group", y = "weight",
order = c("before", "after"),
ylab = "Weight", xlab = "Groups")
# Ajouter la p-value et les niveaux de significativité
stat.test <- stat.test %>% add_xy_position(x = "group")
bxp +
stat_pvalue_manual(stat.test, tip.length = 0) +
labs(subtitle = get_test_label(stat.test, detailed= TRUE))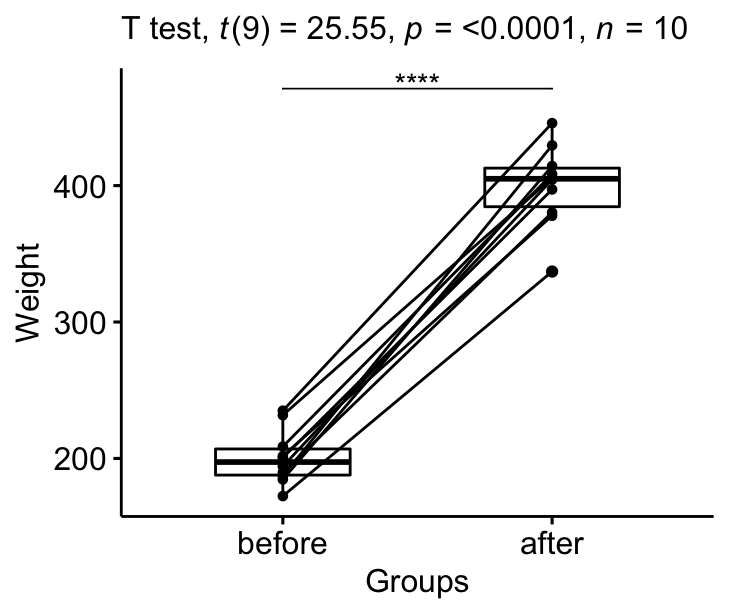
Résumé
Cet article montre comment conduire un t-test dans R/Rstudio en utilisant deux manières différentes : la fonction de base R t.test() et la fonction t_test() dans le paquet rstatix. Nous décrivons également comment interpréter et communiquer les résultats du test t.
References
Cohen, J. 1998. Statistical Power Analysis for the Behavioral Sciences. 2nd ed. Hillsdale, NJ: Lawrence Erlbaum Associates.
Version:
 English
English

No Comments