This article describes how to do a t-test in R (or in Rstudio). You will learn how to:
- Perform a t-test in R using the following functions :
t_test()[rstatix package]: a wrapper around the R base functiont.test(). The result is a data frame, which can be easily added to a plot using theggpubrR package.t.test()[stats package]: R base function to conduct a t-test.
- Interpret and report the t-test
- Add p-values and significance levels to a plot
- Calculate and report the t-test effect size using Cohen’s d. The
dstatistic redefines the difference in means as the number of standard deviations that separates those means. T-test conventional effect sizes, proposed by Cohen, are: 0.2 (small effect), 0.5 (moderate effect) and 0.8 (large effect) (Cohen 1998).
We will provide examples of R code to run the different types of t-test in R, including the:
- one-sample t-test
- two-sample t-test (also known as independent t-test or unpaired t-test)
- paired t-test (also known as dependent t-test or matched pairs t test)
Contents:
Related Book
Practical Statistics in R II - Comparing Groups: Numerical VariablesPrerequisites
Make sure you have installed the following R packages:
tidyversefor data manipulation and visualizationggpubrfor creating easily publication ready plotsrstatixprovides pipe-friendly R functions for easy statistical analyses.datarium: contains required data sets for this chapter.
Start by loading the following required packages:
library(tidyverse)
library(ggpubr)
library(rstatix)One-sample t-test
Demo data
Demo dataset: mice [in datarium package]. Contains the weight of 10 mice:
# Load and inspect the data
data(mice, package = "datarium")
head(mice, 3)## # A tibble: 3 x 2
## name weight
## <chr> <dbl>
## 1 M_1 18.9
## 2 M_2 19.5
## 3 M_3 23.1We want to know, whether the average weight of the mice differs from 25g (two-tailed test)?
Summary statistics
Compute some summary statistics: count (number of subjects), mean and sd (standard deviation)
mice %>% get_summary_stats(weight, type = "mean_sd")## # A tibble: 1 x 4
## variable n mean sd
## <chr> <dbl> <dbl> <dbl>
## 1 weight 10 20.1 1.90Calculation
Using the R base function
res <- t.test(mice$weight, mu = 25)
res##
## One Sample t-test
##
## data: mice$weight
## t = -8, df = 9, p-value = 2e-05
## alternative hypothesis: true mean is not equal to 25
## 95 percent confidence interval:
## 18.8 21.5
## sample estimates:
## mean of x
## 20.1In the result above :
tis the t-test statistic value (t = -8.105),dfis the degrees of freedom (df= 9),p-valueis the significance level of the t-test (p-value = 1.99510^{-5}).conf.intis the confidence interval of the mean at 95% (conf.int = [18.7835, 21.4965]);sample estimatesis the mean value of the sample (mean = 20.14).
Using the rstatix package
We’ll use the pipe-friendly t_test() function [rstatix package], a wrapper around the R base function t.test(). The results can be easily added to a plot using the ggpubr R package.
stat.test <- mice %>% t_test(weight ~ 1, mu = 25)
stat.test## # A tibble: 1 x 7
## .y. group1 group2 n statistic df p
## * <chr> <chr> <chr> <int> <dbl> <dbl> <dbl>
## 1 weight 1 null model 10 -8.10 9 0.00002The results above show the following components:
.y.: the outcome variable used in the test.group1,group2: generally, the compared groups in the pairwise tests. Here, we have null model (one-sample test).statistic: test statistic (t-value) used to compute the p-value.df: degrees of freedom.p: p-value.
You can obtain a detailed result by specifying the option detailed = TRUE in the function t_test().
mice %>% t_test(weight ~ 1, mu = 25, detailed = TRUE)## # A tibble: 1 x 12
## estimate .y. group1 group2 n statistic p df conf.low conf.high method alternative
## * <dbl> <chr> <chr> <chr> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
## 1 20.1 weight 1 null model 10 -8.10 0.00002 9 18.8 21.5 T-test two.sidedInterpretation
The p-value of the test is 210^{-5}, which is less than the significance level alpha = 0.05. We can conclude that the mean weight of the mice is significantly different from 25g with a p-value = 210^{-5}.
Effect size
To calculate an effect size, called Cohen's d, for the one-sample t-test you need to divide the mean difference by the standard deviation of the difference, as shown below. Note that, here: sd(x-mu) = sd(x).
Cohen’s d formula:
\[
d = \frac{m-\mu}{s}
\]
- \(m\) is the sample mean
- \(s\) is the sample standard deviation with \(n-1\) degrees of freedom
- \(\mu\) is the theoretical mean against which the mean of our sample is compared (default value is mu = 0).
Calculation:
mice %>% cohens_d(weight ~ 1, mu = 25)## # A tibble: 1 x 6
## .y. group1 group2 effsize n magnitude
## * <chr> <chr> <chr> <dbl> <int> <ord>
## 1 weight 1 null model 10.6 10 largeRecall that, t-test conventional effect sizes, proposed by Cohen J. (1998), are: 0.2 (small effect), 0.5 (moderate effect) and 0.8 (large effect) (Cohen 1998). As the effect size, d, is 2.56 you can conclude that there is a large effect.
Reporting
We could report the result as follow:
A one-sample t-test was computed to determine whether the recruited mice average weight was different to the population normal mean weight (25g).
The measured mice mean weight (20.14 +/- 1.94) was statistically significantly lower than the population normal mean weight 25 (t(9) = -8.1, p < 0.0001, d = 2.56); where t(9) is shorthand notation for a t-statistic that has 9 degrees of freedom.
The results can be visualized using either a box plot or a density plot.
Box Plot
Create a boxplot to visualize the distribution of mice weights. Add also jittered points to show individual observations. The big dot represents the mean point.
# Create the box-plot
bxp <- ggboxplot(
mice$weight, width = 0.5, add = c("mean", "jitter"),
ylab = "Weight (g)", xlab = FALSE
)
# Add significance levels
bxp + labs(subtitle = get_test_label(stat.test, detailed = TRUE))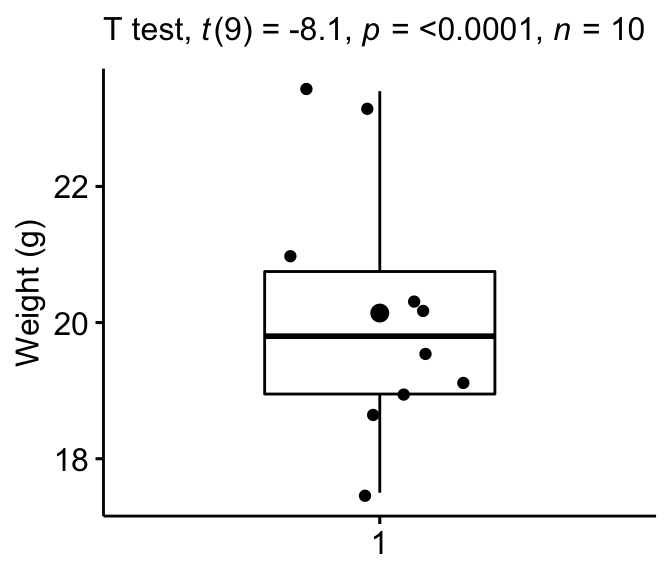
Density plot
Create a density plot with p-value:
- Red line corresponds to the observed mean
- Blue line corresponds to the theoretical mean
ggdensity(mice, x = "weight", rug = TRUE, fill = "lightgray") +
scale_x_continuous(limits = c(15, 27)) +
stat_central_tendency(type = "mean", color = "red", linetype = "dashed") +
geom_vline(xintercept = 25, color = "blue", linetype = "dashed") +
labs(subtitle = get_test_label(stat.test, detailed = TRUE))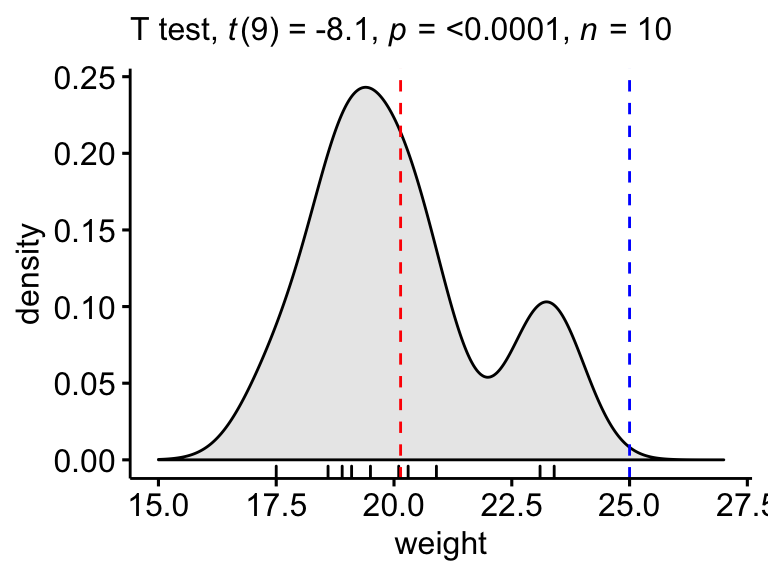
Two-sample t-test
The two-sample t-test is also known as the independent t-test. The independent samples t-test comes in two different forms:
- the standard Student’s t-test, which assumes that the variance of the two groups are equal.
- the Welch’s t-test, which is less restrictive compared to the original Student’s test. This is the test where you do not assume that the variance is the same in the two groups, which results in the fractional degrees of freedom.
The two methods give very similar results unless both the group sizes and the standard deviations are very different.
Demo data
Demo dataset: genderweight [in datarium package] containing the weight of 40 individuals (20 women and 20 men).
Load the data and show some random rows by groups:
# Load the data
data("genderweight", package = "datarium")
# Show a sample of the data by group
set.seed(123)
genderweight %>% sample_n_by(group, size = 2)## # A tibble: 4 x 3
## id group weight
## <fct> <fct> <dbl>
## 1 6 F 65.0
## 2 15 F 65.9
## 3 29 M 88.9
## 4 37 M 77.0We want to know, whether the average weights are different between groups.
Summary statistics
Compute some summary statistics by groups: mean and sd (standard deviation)
genderweight %>%
group_by(group) %>%
get_summary_stats(weight, type = "mean_sd")## # A tibble: 2 x 5
## group variable n mean sd
## <fct> <chr> <dbl> <dbl> <dbl>
## 1 F weight 20 63.5 2.03
## 2 M weight 20 85.8 4.35Calculation
Recall that, by default, R computes the Welch t-test, which is the safer one. This is the test where you do not assume that the variance is the same in the two groups, which results in the fractional degrees of freedom. If you want to assume the equality of variances (Student t-test), specify the option var.equal = TRUE.
Using the R base function
res <- t.test(weight ~ group, data = genderweight)
res##
## Welch Two Sample t-test
##
## data: weight by group
## t = -20, df = 30, p-value <2e-16
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -24.5 -20.1
## sample estimates:
## mean in group F mean in group M
## 63.5 85.8In the result above :
tis the t-test statistic value (t = -20.79),dfis the degrees of freedom (df= 26.872),p-valueis the significance level of the t-test (p-value = 4.29810^{-18}).conf.intis the confidence interval of the means difference at 95% (conf.int = [-24.5314, -20.1235]);sample estimatesis the mean value of the sample (mean = 63.499, 85.826).
Using the rstatix package
stat.test <- genderweight %>%
t_test(weight ~ group) %>%
add_significance()
stat.test## # A tibble: 1 x 9
## .y. group1 group2 n1 n2 statistic df p p.signif
## <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <chr>
## 1 weight F M 20 20 -20.8 26.9 4.30e-18 ****The results above show the following components:
.y.: the y variable used in the test.group1,group2: the compared groups in the pairwise tests.statistic: Test statistic used to compute the p-value.df: degrees of freedom.p: p-value.
Note that, you can obtain a detailed result by specifying the option detailed = TRUE.
genderweight %>%
t_test(weight ~ group, detailed = TRUE) %>%
add_significance()## # A tibble: 1 x 16
## estimate estimate1 estimate2 .y. group1 group2 n1 n2 statistic p df conf.low conf.high method alternative p.signif
## <dbl> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <chr> <chr> <chr>
## 1 -22.3 63.5 85.8 weight F M 20 20 -20.8 4.30e-18 26.9 -24.5 -20.1 T-test two.sided ****Interpretation
The p-value of the test is 4.310^{-18}, which is less than the significance level alpha = 0.05. We can conclude that men’s average weight is significantly different from women’s average weight with a p-value = 4.310^{-18}.
Effect size
Cohen’s d for Student t-test
There are multiple version of Cohen’s d for Student t-test. The most commonly used version of the Student t-test effect size, comparing two groups (\(A\) and \(B\)), is calculated by dividing the mean difference between the groups by the pooled standard deviation.
Cohen’s d formula:
\[
d = \frac{m_A - m_B}{SD_{pooled}}
\]
where,
- \(m_A\) and \(m_B\) represent the mean value of the group A and B, respectively.
- \(n_A\) and \(n_B\) represent the sizes of the group A and B, respectively.
- \(SD_{pooled}\) is an estimator of the pooled standard deviation of the two groups. It can be calculated as follow :
\[
SD_{pooled} = \sqrt{\frac{\sum{(x-m_A)^2}+\sum{(x-m_B)^2}}{n_A+n_B-2}}
\]
Calculation. If the option var.equal = TRUE, then the pooled SD is used when computing the Cohen’s d.
genderweight %>% cohens_d(weight ~ group, var.equal = TRUE)## # A tibble: 1 x 7
## .y. group1 group2 effsize n1 n2 magnitude
## * <chr> <chr> <chr> <dbl> <int> <int> <ord>
## 1 weight F M -6.57 20 20 largeThere is a large effect size, d = 6.57.
Note that, for small sample size (< 50), the Cohen’s d tends to over-inflate results. There exists a Hedge’s Corrected version of the Cohen’s d (Hedges and Olkin 1985), which reduces effect sizes for small samples by a few percentage points. The correction is introduced by multiplying the usual value of d by (N-3)/(N-2.25) (for unpaired t-test) and by (n1-2)/(n1-1.25) for paired t-test; where N is the total size of the two groups being compared (N = n1 + n2).
Cohen’s d for Welch t-test
The Welch test is a variant of t-test used when the equality of variance can’t be assumed. The effect size can be computed by dividing the mean difference between the groups by the “averaged” standard deviation.
Cohen’s d formula:
\[
d = \frac{m_A - m_B}{\sqrt{(Var_1 + Var_2)/2}}
\]
where,
- \(m_A\) and \(m_B\) represent the mean value of the group A and B, respectively.
- \(Var_1\) and \(Var_2\) are the variance of the two groups.
Calculation:
genderweight %>% cohens_d(weight ~ group, var.equal = FALSE)## # A tibble: 1 x 7
## .y. group1 group2 effsize n1 n2 magnitude
## * <chr> <chr> <chr> <dbl> <int> <int> <ord>
## 1 weight F M -6.57 20 20 largeNote that, when group sizes are equal and group variances are homogeneous, Cohen’s d for the standard Student and Welch t-tests are identical.
Report
We could report the result as follow:
The mean weight in female group was 63.5 (SD = 2.03), whereas the mean in male group was 85.8 (SD = 4.3). A Welch two-samples t-test showed that the difference was statistically significant, t(26.9) = -20.8, p < 0.0001, d = 6.57; where, t(26.9) is shorthand notation for a Welch t-statistic that has 26.9 degrees of freedom.
Visualize the results:
# Create a box-plot
bxp <- ggboxplot(
genderweight, x = "group", y = "weight",
ylab = "Weight", xlab = "Groups", add = "jitter"
)
# Add p-value and significance levels
stat.test <- stat.test %>% add_xy_position(x = "group")
bxp +
stat_pvalue_manual(stat.test, tip.length = 0) +
labs(subtitle = get_test_label(stat.test, detailed = TRUE))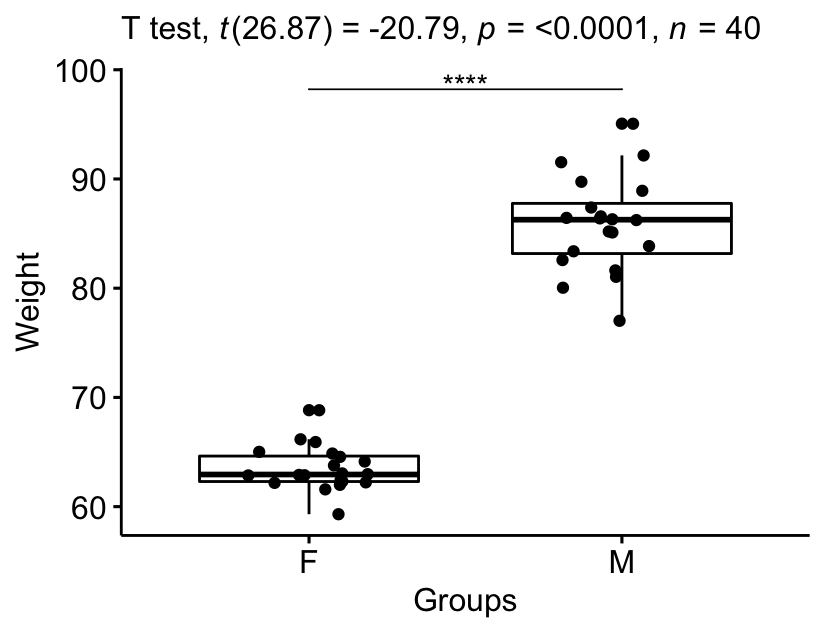
Paired t-test
Demo data
Here, we’ll use a demo dataset mice2 [datarium package], which contains the weight of 10 mice before and after the treatment.
# Wide format
data("mice2", package = "datarium")
head(mice2, 3)## id before after
## 1 1 187 430
## 2 2 194 404
## 3 3 232 406# Transform into long data:
# gather the before and after values in the same column
mice2.long <- mice2 %>%
gather(key = "group", value = "weight", before, after)
head(mice2.long, 3)## id group weight
## 1 1 before 187
## 2 2 before 194
## 3 3 before 232We want to know, if there is any significant difference in the mean weights after treatment?
Summary statistics
Compute some summary statistics (mean and sd) by groups:
mice2.long %>%
group_by(group) %>%
get_summary_stats(weight, type = "mean_sd")## # A tibble: 2 x 5
## group variable n mean sd
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 after weight 10 400. 30.1
## 2 before weight 10 201. 20.0Calculation
Using the R base function
res <- t.test(weight ~ group, data = mice2.long, paired = TRUE)
resIn the result above :
tis the t-test statistic value (t = -20.79),dfis the degrees of freedom (df= 26.872),p-valueis the significance level of the t-test (p-value = 4.29810^{-18}).conf.intis the confidence interval of the mean of the differences at 95% (conf.int = [-24.5314, -20.1235]);sample estimatesis the mean of the differences (mean = 63.499, 85.826).
Using the rstatix package
stat.test <- mice2.long %>%
t_test(weight ~ group, paired = TRUE) %>%
add_significance()
stat.test## # A tibble: 1 x 9
## .y. group1 group2 n1 n2 statistic df p p.signif
## <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <chr>
## 1 weight after before 10 10 25.5 9 0.00000000104 ****The results above show the following components:
.y.: the y variable used in the test.group1,group2: the compared groups in the pairwise tests.statistic: Test statistic used to compute the p-value.df: degrees of freedom.p: p-value.
Note that, you can obtain a detailed result by specifying the option detailed = TRUE.
mice2.long %>%
t_test(weight ~ group, paired = TRUE, detailed = TRUE) %>%
add_significance()## # A tibble: 1 x 14
## estimate .y. group1 group2 n1 n2 statistic p df conf.low conf.high method alternative p.signif
## <dbl> <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <chr> <chr> <chr>
## 1 199. weight after before 10 10 25.5 0.00000000104 9 182. 217. T-test two.sided ****Interpretation
The p-value of the test is 1.0410^{-9}, which is less than the significance level alpha = 0.05. We can then reject null hypothesis and conclude that the average weight of the mice before treatment is significantly different from the average weight after treatment with a p-value = 1.0410^{-9}.
Effect size
The effect size for a paired-samples t-test can be calculated by dividing the mean difference by the standard deviation of the difference, as shown below.
Cohen’s d formula:
\[
d = \frac{mean_D}{SD_D}
\]
Where D is the differences of the paired samples values.
Calculation:
mice2.long %>% cohens_d(weight ~ group, paired = TRUE)## # A tibble: 1 x 7
## .y. group1 group2 effsize n1 n2 magnitude
## * <chr> <chr> <chr> <dbl> <int> <int> <ord>
## 1 weight after before 8.08 10 10 largeThere is a large effect size, Cohen’s d = 8.07.
Report
We could report the result as follow: The average weight of mice was significantly increased after treatment, t(9) = 25.5, p < 0.0001, d = 8.07.
Visualize the results:
# Create a box plot
bxp <- ggpaired(mice2.long, x = "group", y = "weight",
order = c("before", "after"),
ylab = "Weight", xlab = "Groups")
# Add p-value and significance levels
stat.test <- stat.test %>% add_xy_position(x = "group")
bxp +
stat_pvalue_manual(stat.test, tip.length = 0) +
labs(subtitle = get_test_label(stat.test, detailed= TRUE))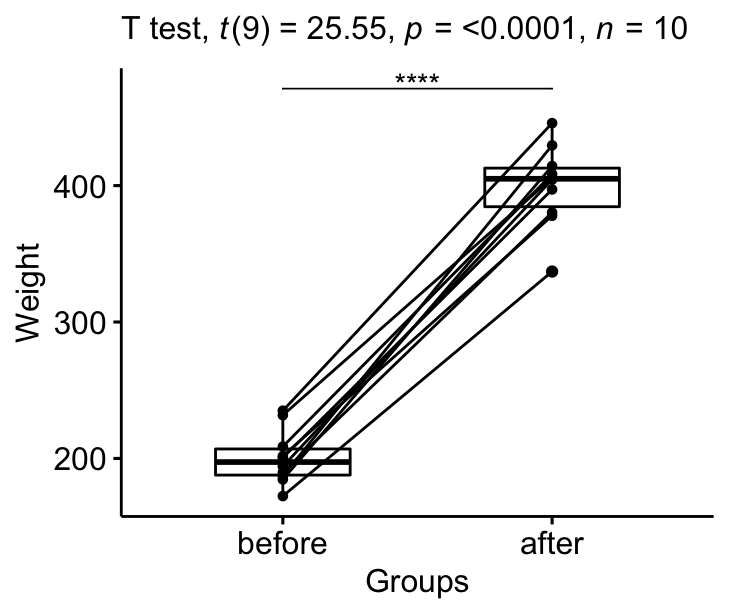
Summary
This article shows how to conduct a t-test in R/Rstudio using two different ways: the R base function t.test() and the t_test() function in the rstatix package. We also describe how to interpret and report the t-test results.
References
Cohen, J. 1998. Statistical Power Analysis for the Behavioral Sciences. 2nd ed. Hillsdale, NJ: Lawrence Erlbaum Associates.
Hedges, Larry, and Ingram Olkin. 1985. “Statistical Methods in Meta-Analysis.” In Stat Med. Vol. 20. doi:10.2307/1164953.
Recommended for you
This section contains best data science and self-development resources to help you on your path.
Books - Data Science
Our Books
- Practical Guide to Cluster Analysis in R by A. Kassambara (Datanovia)
- Practical Guide To Principal Component Methods in R by A. Kassambara (Datanovia)
- Machine Learning Essentials: Practical Guide in R by A. Kassambara (Datanovia)
- R Graphics Essentials for Great Data Visualization by A. Kassambara (Datanovia)
- GGPlot2 Essentials for Great Data Visualization in R by A. Kassambara (Datanovia)
- Network Analysis and Visualization in R by A. Kassambara (Datanovia)
- Practical Statistics in R for Comparing Groups: Numerical Variables by A. Kassambara (Datanovia)
- Inter-Rater Reliability Essentials: Practical Guide in R by A. Kassambara (Datanovia)
Others
- R for Data Science: Import, Tidy, Transform, Visualize, and Model Data by Hadley Wickham & Garrett Grolemund
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems by Aurelien Géron
- Practical Statistics for Data Scientists: 50 Essential Concepts by Peter Bruce & Andrew Bruce
- Hands-On Programming with R: Write Your Own Functions And Simulations by Garrett Grolemund & Hadley Wickham
- An Introduction to Statistical Learning: with Applications in R by Gareth James et al.
- Deep Learning with R by François Chollet & J.J. Allaire
- Deep Learning with Python by François Chollet
Version:
 Français
Français

No Comments