Le kappa de Cohen(Jacob Cohen 1960, J Cohen (1968)) sert à mesurer l’accord entre deux évaluateurs (c.-à-d. “juges”, “observateurs”) ou entre deux méthodes de classification. Ce processus mesurant le dégré de concordance entre évaluateurs s’appelle la fidélité inter-évaluateur.
Traditionnellement, la fiabilité entre les évaluateurs était mesurée comme un simple pourcentage global de concordance, calculé comme étant le nombre de cas où les deux évaluateurs sont d’accord divisé par le nombre total de cas considérés.
Ce pourcentage de concordance est critiqué en raison de son incapacité à prendre en compte la concordance aléatoire ou attendue par hasard, qui est la proportion de concordance que l’on s’attendrait à avoir si les deux évaluateurs ont basée leur évaluation simplement sur le hasard.
Le kappa de Cohen est une mesure de concordance couramment utilisée qui élimine cet accord aléatoire lié au hasard. En d’autres termes, il tient compte de la possibilité que les évaluateurs devinent au moins certaines variables en raison de l’incertitude.
Il y a beaucoup de situations où vous pouvez calculer le Kappa de Cohen. Par exemple, vous pourriez utiliser le kappa de Cohen pour déterminer l’accord entre deux médecins pour diagnostiquer les patients en groupe pronostic “bon”, “intermédiaire” et “mauvais”.
Le kappa de Cohen peut être utilisé pour deux variables catégorielles, qui peuvent être soit deux variables nominales soit deux variables ordinales. D’autres variantes existent, notamment:
- Le Kappa pondéré à utiliser uniquement pour les variables ordinales.
- Le Kappa de Light, qui n’est que la moyenne de toutes les Kappa de Cohen possibles lorsqu’il y a plus de deux variables catégorielles (Conger 1980).
- Le kappa de Fleiss, qui est une adaptation du kappa de Cohen pour n évaluateurs, où n peut être 2 ou plus.
Ce chapitre décrit comment mesurer l’accord inter-évaluateurs à l’aide du kappa de Cohen et du Kappa de Light.
Vous apprendrez:
- Les bases, formule et explication étape par étape du calcul manuel
- Exemples de code R pour calculer le kappa de Cohen pour deux évaluateurs
- Comment calculer le kappa de Light pour plus de deux évaluateurs
- Interprétation du coefficient kappa
Contents:
Livre associé
Concordance Inter-Juges: L'Essentiel - Guide Pratique dans RBases et calculs manuels
Formule
La formule du Kappa de Cohen est définie comme suit:
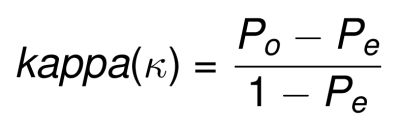
- Po : proportion de l’accord observé
- Pe : proportion d’un accord aléatoire
kappa peut varier de -1 (aucun accord) à +1 (accord parfait).
- lorsque k = 0, l’accord n’est pas meilleur que ce qui serait obtenu par hasard.
- lorsque k est négatif, l’accord est inférieur à l’accord attendu par hasard.
- lorsque k est positif, l’accord d’évaluation dépasse l’accord aléatoire.
Kappa pour 2x2 tables
Pour expliquer comment calculer la concordence observée et attendue, considérons le tableau de contingence suivant. On a demandé à deux psychologues cliniciens de diagnostiquer si 70 personnes souffrent de dépression ou non.
Structure des données:
## Doctor2
## Doctor1 Yes No Total
## Yes a b R1
## No c d R2
## Total C1 C2 NOù:
- a, b, c et d sont les nombre d’individus observés (O);
- N = a + b + c + c + d, c’est-à-dire le total du tableau;
- R1 et R2 sont le total des lignes 1 et 2, respectivement. Celles-ci représentent les marges de la ligne dans le jargon statistique.
- C1 et C2 sont le total des colonnes 1 et 2, respectivement. Ce sont les marges des colonne.
Exemple de données:
## doctor2
## doctor1 yes no Sum
## yes 25 10 35
## no 15 20 35
## Sum 40 30 70Proportion de l’accord observé. Le nombre total d’accords observés est la somme des entrées diagonales. La proportion d’accord observé est : somme(valeurs.diagonales)/N, où N est le total des comptes du tableau.
- 25 participants ont été diagnostiqués oui par les deux médecins
- 20 participants ont été diagnostiqués non par les deux
donc, Po = (a + d)/N = (25 + 20)/70 = 0.643
Proportion d’accords par chance. La proportion attendue de l’accord est calculée comme suit.
Étape 1 : Déterminer la probabilité que les deux médecins disent oui au hasard:
- Le Docteur 1 dit oui à 35/70 (0,5) participants. Cela représente la proportion marginale de la ligne 1, qui est
row1.sum/N. - Le Docteur 2 dit oui à 40/70 (0,57) participants. Cela représente la proportion marginale de la colonne 1, qui est la suivante
column1.sum/N. - Probabilité totale que les deux médecins disent oui au hasard est
0.5*0.57 = 0.285. Il s’agit du produit des proportions marginales de la ligne 1 et de la colonne 1.
Étape 2. Déterminer la probabilité que les deux médecins disent Non au hasard :
- Le Docteur 1 dit non à 35/70 (0,5) participants. Il s’agit de la proportion marginale de la ligne 2:
row2.sum/N. - Le Docteur 2 dit non à 30/70 (0,428) participants. Il s’agit de la proportion marginale de la colonne 2:
column2.sum/N. - Probabilité totale que les deux médecins disent non au hasard est
0.5*0.428 = 0.214. Il s’agit du produit des proportions marginales de la ligne 2 et de la colonne 2.
donc, la probabilité totale prévue par hasard est la suivante Pe = 0.285+0.214 = 0.499. Techniquement, cela peut être considéré comme la somme du produit des proportions marginales des lignes et des colonnes: Pe = sum(rows.marginal.proportions x columns.marginal.proportions).
Le kappa de Cohen. Enfin, le kappa de Cohen est (0.643 - 0.499)/(1-0.499) = 0.28.
Kappa pour deux variables catégorielles à niveaux multiples
Dans la section précédente, nous avons montré comment calculer manuellement la valeur de kappa pour une table 2x2 (variables binomiales : oui vs non). Ceci peut être généralisé aux variables catégorielles à catégories multiples comme suit.
Les évaluations des deux évaluateurs peuvent être résumées dans un tableau de contingence k×k, où k est le nombre de catégories.
Exemple de tableau de contingence de kxk pour évaluer l’accord sur k catégories par deux évaluateurs différents:
## rater2
## rater1 Level.1 Level.2 Level... Level.k Total
## Level.1 n11 n12 ... n1k n1+
## Level.2 n21 n22 ... n2k n2+
## Level... ... ... ... ... ...
## Level.k nk1 nk2 ... nkk nk+
## Total n+1 n+2 ... n+k NTerminologies:
- La colonne “Total” (
n1+, n2+, ...., nk+) indique la somme de chaque ligne, connue sous le nom de marges des lignes ou effectifs marginaux. Ici, la somme totale d’une ligne donnéeiest noméeni+. - La ligne “Total” (
n+1, n+2, ...., n+k) indique la somme de chaque colonne, appelée marges des colonnes. Ici, la somme totale d’une colonne donnéeiest noméen+i - N est la somme totale de toutes les cellules du tableau
- Pour une ligne/colonne donnée, la proportion marginale est la division de la marge ligne/colonne par N. C’est ce qu’on appelle aussi les fréquences ou probalités marginales. Pour une ligne
i, la proportion marginale estPi+ = ni+/N. De même, pour une colonne donnéei, la proportion marginale estP+i = n+i/N. - Pour chaque cellule du tableau, la proportion peut être calculée en divisant le nombre de cellules par N.
La proportion de concordance observée (Po) est la somme des proportions diagonales, ce qui correspond à la proportion de cas où les deux évaluateurs ont assigné les mêmse catégories.

La proportion d’un accord aléatoire (Pe) est la somme des produits des proportions marginales des lignes et des colonnes:pe = sum(row.marginal.proportions x column.marginal.proportions)
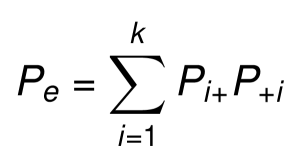
Ainsi, le kappa de Cohen’s peut être calculé en introduisant Po et Pe dans la formule: k = (Po - Pe)/(1 - Pe).
Intervalles de confiance Kappa. Pour un échantillon de grande taille, l’erreur type (SE) de kappa peut être calculée comme suit (J. L. Fleiss and Cohen 1973, J. L. Fleiss, Cohen, and Everitt (1969), Friendly, Meyer, and Zeileis (2015)):
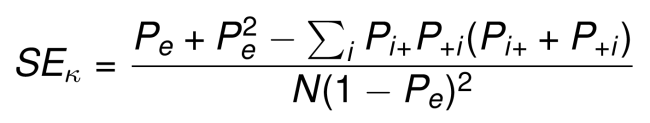
Une fois que SE(k) est calculé, un intervalle de confiance de 100(1 - alpha)% pour kappa peut être calculé en utilisant la distribution normale standard comme suit:
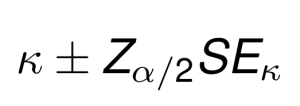
Par exemple, la formule de l’intervalle de confiance à 95 % est la suivante: k +/- 1.96 x SE.
R pour calculer pas à pas le kappa de Cohen:
# Tableau de contingence
xtab <- as.table(rbind(c(25, 10), c(15, 20)))
# Statistiques descriptives
diagonal.counts <- diag(xtab)
N <- sum(xtab)
row.marginal.props <- rowSums(xtab)/N
col.marginal.props <- colSums(xtab)/N
# Calculer kappa (k)
Po <- sum(diagonal.counts)/N
Pe <- sum(row.marginal.props*col.marginal.props)
k <- (Po - Pe)/(1 - Pe)
kDans les sections suivantes, vous apprendrez une fonction R en une seule ligne de commande pour calculer Kappa.
Interprétation : Ampleur de l’accord
Dans la plupart des applications, on s’intéresse généralement davantage à l’ampleur du coefficient kappa plutôt qu’à la significativité statistique de kappa. Les classifications suivantes ont été suggérées pour interpréter la force de l’accord en fonction de la valeur Kappa de Cohen(Altman 1999, Landis JR (1977)).
| Valeur de k | Force de l’accord |
|---|---|
| < 0 | Médiocre |
| 0,01 - 0,20 | Léger |
| 0,21-0,40 | Passable |
| 0,41-0,60 | Modéré |
| 0,61-0,80 | Substantiel |
| 0,81 - 1,00 | Presque parfait |
Toutefois, cette interprétation permet de dire que très peu d’accord entre les évaluateurs est “substantiel”. D’après le tableau, 61 % de concordance est considéré comme bon, mais cela peut immédiatement être considéré comme problématique selon le domaine. Près de 40 % des données représentent des données erronées. Dans le domaine de la recherche en soins de santé, cela pourrait déboucher sur des recommandations visant à modifier la pratique sur la base de preuves erronées. Pour un laboratoire clinique, avoir 40% d’évaluations d’échantillons erronées serait un problème de qualité extrêmement sérieux(McHugh 2012).
C’est la raison pour laquelle de nombreux textes recommandent un accord de 80 % comme minimum acceptable de l’accord inter-évaluateurs. Tout kappa inférieur à 0,60 indique un accord inadéquat entre les évaluateurs et un manque de confiance dans les résultats de l’étude.
Fleiss et al. (2003) ont déclaré ceci pour la plupart des applications,
- des valeurs supérieures à 0,75 ou plus peuvent être considérées comme un excellent accord au-delà du hasard,
- des valeurs inférieures à 0,40 environ peuvent être considérées comme un mauvais accord au-delà du hasard, et
- des valeurs comprises entre 0,40 et 0,75 peuvent être considérées comme représentatives d’un accord juste à bon au-delà du hasard.
Une autre interprétation logique de kappa de (McHugh 2012) est suggérée dans le tableau ci-dessous:
| Valeur de k | Niveau d’accord | % de données fiables |
|---|---|---|
| 0 - 0,20 | Aucun | 0 - 4‰ |
| 0,21 - 0,39 | Minimal | 4 - 15% |
| 0,40 - 0,59 | Faible | 15 - 35% |
| 0,60 - 0,79 | Modéré | 35 - 63% |
| 0,80 - 0,90 | Fort | 64 - 81% |
| Au-dessus de 0,90 | Presque parfait | 82 - 100% |
Dans le tableau ci-dessus, la colonne “% de données fiables” correspond à kappa au carré, équivalent du coefficient de corrélation au carré (R^2), qui est directement interprétable.
Hypothèses et exigences
Vos données doivent répondre aux hypothèses suivantes pour le calcul du Kappa de Cohen.
- Vous avez deux variables catégorielles de résultats, qui peuvent être ordinales ou nominales.
- Les deux variables de résultats doivent avoir exactement les mêmes catégories
- Vous avez des observations appariées ; chaque sujet est classé deux fois par deux évaluateurs ou méthodes indépendants.
- Les mêmes deux évaluateurs sont utilisés pour tous les participants.
Hypothèses statistiques
- Hypothèse nulle (H0):
kappa = 0. L’accord est le même que l’accord aléatoire. - Hypothèse alternative (Ha):
kappa ≠ 0. L’accord est différent d’un accord aléatoire.
Exemple de données
Nous utiliserons les données sur les diagnostics psychiatriques fournies par deux médecins cliniciens. 30 patients ont été inscrits et classés par chacun des deux médecins en 5 catégories(J. Fleiss and others 1971) : 1. Dépression, 2. Trouble de la personnalité, 3. Schizophrénie, 4. Névrose, 5. Autre.
Les données sont organisées dans le tableau de contingence 5x5 suivant:
# Données de démonstration
diagnoses <- as.table(rbind(
c(7, 1, 2, 3, 0), c(0, 8, 1, 1, 0),
c(0, 0, 2, 0, 0), c(0, 0, 0, 1, 0),
c(0, 0, 0, 0, 4)
))
categories <- c("Depression", "Personality Disorder",
"Schizophrenia", "Neurosis", "Autre")
dimnames(diagnoses) <- list(Doctor1 = categories, Doctor2 = categories)
diagnoses## Doctor2
## Doctor1 Depression Personality Disorder Schizophrenia Neurosis Autre
## Depression 7 1 2 3 0
## Personality Disorder 0 8 1 1 0
## Schizophrenia 0 0 2 0 0
## Neurosis 0 0 0 1 0
## Autre 0 0 0 0 4Calcul de Kappa
Kappa pour deux évaluateurs
La fonction R Kappa() [package vcd] peut être utilisée pour calculer le Kappa non pondéré et pondéré. La version non pondérée correspond au Kappa de Cohen, qui fait l’objet de ce chapitre. Les Kappa pondérés ne doivent être considérés que pour les variables ordinales et sont largement décrits au chapitre @ref(weighted-kappa).
# install.packages("vcd")
library("vcd")
# Calculer kapa
res.k <- Kappa(diagnoses)
res.k## value ASE z Pr(>|z|)
## Unweighted 0.651 0.0997 6.53 6.47e-11
## Weighted 0.633 0.1194 5.30 1.14e-07# Intervalles de confiance
confint(res.k)##
## Kappa lwr upr
## Unweighted 0.456 0.847
## Weighted 0.399 0.867Notez que, dans les résultats ci-dessus, ASE est l’erreur type asymptotique de la valeur kappa.
Dans notre exemple, le kappa de Cohen (k) = 0,65, ce qui représente un degré d’accord moyen à bon selon la classification de Fleiss et al. (2003). Ceci est confirmé par la p-value obtenue (p < 0,05), indiquant que notre kappa calculée est significativement différent de zéro.
Kappa pour plus de deux évaluateurs
S’il y a plus de 2 évaluateurs, alors la moyenne de tous les kappa possibles est connue sous le nom de kappa de Light (Conger 1980). Vous pouvez le calculer en utilisant la fonction kappam.light() [package irr], qui prend une matrice en entrée. Les colonnes de la matrice sont des évaluateurs et les lignes sont des individus.
# install.packages("irr")
library(irr)
# Charger et inspecter les données de démo
data("diagnoses", package = "irr")
head(diagnoses[, 1:3], 4)## Doctor2
## Doctor1 Depression Personality Disorder Schizophrenia
## Depression 7 1 2
## Personality Disorder 0 8 1
## Schizophrenia 0 0 2
## Neurosis 0 0 0# Calculez la kappa de Light entre les 3 premiers évaluateurs
kappam.light(diagnoses[, 1:3])## Light's Kappa for m Raters
##
## Subjects = 5
## Raters = 3
## Kappa = 0.172
##
## z = 0.69
## p-value = 0.49Rapporter
Le kappa de Cohen a été calculé pour évaluer l’accord entre deux médecins dans le diagnostic des troubles psychiatriques chez 30 patients. Il y avait un bon accord entre les deux médecins, kappa = 0,65 (IC à 95 %, 0,46 à 0,84), p < 0,0001.
Résumé
Ce chapitre décrit les bases et la formule du kappa de Cohen. De plus, nous montrons comment calculer et interpréter le coefficient kappa dans R. Nous fournissons également des exemples de codes R pour le calcul du Kappa de Light, qui est la moyenne de toutes les kappa possibles entre deux évaluateurs lorsque vous avez plus de deux évaluateurs.
D’autres variantes du kappa de Cohen comprennent : le kappa pondéré (pour deux variables ordinales, chapitre @ref(weighted-kappa)) et le kappa de Fleiss (pour deux variables ou plus, chapitre @ref(weighted-kappa)).
References
Altman, Douglas G. 1999. Practical Statistics for Medical Research. Chapman; Hall/CRC Press.
Cohen, J. 1968. “Weighted Kappa: Nominal Scale Agreement with Provision for Scaled Disagreement or Partial Credit.” Psychological Bulletin 70 (4): 213—220. doi:10.1037/h0026256.
Cohen, Jacob. 1960. “A Coefficient of Agreement for Nominal Scales.” Educational and Psychological Measurement 20 (1): 37–46. doi:10.1177/001316446002000104.
Conger, A. J. 1980. “Integration and Generalization of Kappas for Multiple Raters.” Psychological Bulletin 88 (2): 322–28.
Fleiss, J.L., and others. 1971. “Measuring Nominal Scale Agreement Among Many Raters.” Psychological Bulletin 76 (5): 378–82.
Fleiss, Joseph L., and Jacob Cohen. 1973. “The Equivalence of Weighted Kappa and the Intraclass Correlation Coefficient as Measures of Reliability.” Educational and Psychological Measurement 33 (3): 613–19. doi:10.1177/001316447303300309.
Fleiss, Joseph L., Jacob Willem Cohen, and Brian Everitt. 1969. “Large Sample Standard Errors of Kappa and Weighted Kappa.” Psychological Bulletin 72: 332–27.
Friendly, Michael, D. Meyer, and A. Zeileis. 2015. Discrete Data Analysis with R: Visualization and Modeling Techniques for Categorical and Count Data. 1st ed. Chapman; Hall/CRC.
Landis JR, Koch GG. 1977. “The Measurement of Observer Agreement for Categorical Data” 1 (33). Biometrics: 159–74.
McHugh, Mary. 2012. “Interrater Reliability: The Kappa Statistic.” Biochemia Medica : Časopis Hrvatskoga Društva Medicinskih Biokemičara / HDMB 22 (October): 276–82. doi:10.11613/BM.2012.031.
Version:
 English
English

No Comments