En recherche biomédicale, comportementale et dans bien d’autres domaines, il est souvent nécessaire qu’un groupe de participants soit noté ou classé en catégories par deux observateurs (ou évaluateurs, méthodes, etc). Par exemple, deux cliniciens qui classifient le stade de la maladie chez les patients. L’analyse de l’accord entre les deux observateurs peut être utilisée pour mesurer la fiabilité du système d’évaluation. Un accord élevé indiquerait un consensus sur le diagnostic et l’interchangeabilité des observateurs (Warrens 2013).
Dans un chapitre précédent (Chapitre @ref(cohen-s-kappa)), nous avons décrit le Kappa de Cohen, qui est une mesure populaire de fidelité inter-évaluateurs ou concordance inter-évaluateurs. Le Kappa de Cohen classique ne compte que les accords stricts, où la même catégorie est assignée par les deux évaluateurs (Friendly, Meyer, and Zeileis 2015). Il ne tient pas compte du degré de désaccord, tous les désaccords sont traités sur un pied d’égalité. Ceci est plus approprié lorsque vous avez des variables nominales. Pour l’échelle d’évaluation ordinale, il peut être préférable d’attribuer des pondérations différentes aux désaccords en fonction de leur ampleur.
Ce chapitre décrit le kappa pondéré, une variante du Kappa de Cohen, qui permet un accord partiel (J. Cohen 1968). En d’autres termes, le kappa pondéré permet d’utiliser des schémas de pondération pour tenir compte de la proximité de l’accord entre les catégories. Ceci ne convient que dans le cas où vous avez des variables ordinales ou classées.
Rappelons que les coefficients kappa éliminent l’accord dû au hasard, c’est à dire, la proportion de concordance que l’on s’attendrait à avoir si les deux évaluateurs ont fondé leur évaluation simplement sur la base du hasard.
Ici, vous apprendrez:
- Les bases et la formule du kappa pondéré
- Hypothèses et exigences pour le calcul de la kappa pondérée
- Exemples de code R pour le calcul du kappa pondéré
Contents:
Livre associé
Concordance Inter-Juges: L'Essentiel - Guide Pratique dans RPrérequis
Lire le chapitre sur le Kappa de Cohen (Chapitre @ref(cohen-s-kappa)).
Notions de base
Pour expliquer le concept de base du kappa pondéré, considerons que les catégories évaluées soient ordonnées comme suit : “fortement en désaccord”, “en désaccord”, “neutre”, “d’accord” et “fortement d’accord”.
Le coefficient kappa pondéré tient compte des différents niveaux de désaccord entre les catégories. Par exemple, si un évaluateur est “fortement en désaccord” et un autre “fortement d’accord”, cela doit être considéré comme un niveau de désaccord plus élevé que lorsqu’un évaluateur est “d’accord” et un autre “fortement d’accord” (Tang et al. 2015).
Formule
tableau de contingence kxk. Considérons le tableau de contingence k×k suivant, qui résume les évaluations attribuées par deux évaluateurs. k est le nombre de catégories. Les cellules du tableau contiennent les comptages des catégories interclassées. Ces comptes sont indiqués par la notation n11, n12, ...., n1K pour la ligne 1 ; n21, n22, ..., n2K pour la ligne 2, etc.
## rater2
## rater1 Level.1 Level.2 Level... Level.k Total
## Level.1 n11 n12 ... n1k n1+
## Level.2 n21 n22 ... n2k n2+
## Level... ... ... ... ... ...
## Level.k nk1 nk2 ... nkk nk+
## Total n+1 n+2 ... n+k NTerminologies:
- La colonne “Total” (
n1+, n2+, ...., nk+) indique la somme de chaque ligne, connue sous le nom de marges des lignes ou effectifs marginaux. Ici, la somme totale d’une ligne donnéeiest nomméeni+. - La ligne “Total” (
n+1, n+2, ...., n+k) indique la somme de chaque colonne, appelée marges des colonnes. Ici, la somme totale d’une colonne donnéeiest nomméen+i - N est la somme totale de toutes les cellules du tableau
- Pour une ligne/colonne donnée, la proportion marginale est la division de la marge ligne/colonne par N. C’est ce qu’on appelle aussi les fréquences ou probalités marginales. Pour une ligne
i, la proportion marginale estPi+ = ni+/N. De même, pour une colonne donnéei, la proportion marginale estP+i = n+i/N. - Pour chaque cellule du tableau, la proportion peut être calculée en divisant le nombre de cellules par N.
Proportions des cellules. La proportion dans chaque cellule est obtenue en divisant le nombre dans la cellule par le nombre total de N cas (somme de tous les nombres du tableau).
## rater2
## rater1 Level.1 Level.2 Level... Level.k Total
## Level.1 p11 p12 ... p1k p1+
## Level.2 p21 p22 ... p2k p2+
## Level... ... ... ... ... ...
## Level.k pk1 pk2 ... pkk pk+
## Total p+1 p+2 ... p+k 1Poids. Pour calculer un kappa pondéré, des poids sont attribués à chaque cellule du tableau de contingence. Les poids vont de 0 à 1, avec un poids = 1 attribué à toutes les cellules diagonales (correspondant à l’accord des deux évaluateurs)(Friendly, Meyer, and Zeileis 2015). Les types de pondérations couramment utilisés sont expliqués dans les sections suivantes.
La proportion de l’accord observé (Po) est la somme des proportions pondérées.
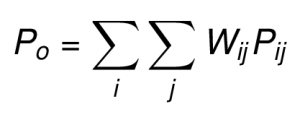
La proportion de l’accord aléatoire attendue (Pe) est la somme du produit pondéré des proportions marginales des lignes et des colonnes.
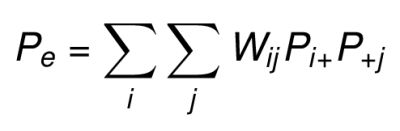
Le Kappa pondéré peut alors être calculée en introduisant ces Po et Pe pondérés dans la formule suivante:
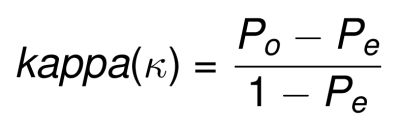
kappa peut varier de -1 (aucun accord) à +1 (accord parfait).
- lorsque k = 0, l’accord n’est pas meilleur que ce qui serait obtenu par hasard.
- lorsque k est négatif, l’accord est inférieur à l’accord attendu par hasard.
- lorsque k est positif, l’accord d’évaluation dépasse l’accord aléatoire.
Notez que pour le tableau 2x2 (évaluation binomiale), il n’y a pas de version pondérée de kappa, puisque kappa reste le même quel que soit le système de pondération utilisé.
Types de poids : Linéaire et quadratique
Il existe deux systèmes de pondération couramment utilisés dans la littérature:
- Les poids de Cicchetti-Allison(Cicchetti and Allison 1971) basés sur des poids d’espacement égaux. C’est ce qu’on appelle aussi les poids linéaires car ils sont proportionnels à l’écart entre deux évaluations d’un individu.
- Les poids de Fleiss-Cohen(Fleiss and Cohen 1973), basés sur un espacement carré-inverse. C’est ce qu’on appelle aussi les pondérations quadratiques car elles sont proportionnelles au carré de l’écart entre deux évaluations.
Pour une table de contingence RxR,
- le poids linéaire pour une cellule donnée est:
W_ij = 1-(|i-j|)/(R-1) - le poids quadratique pour une cellule donnée est:
W_ij = 1-(|i-j|)^2/(R-1)^2
où, |i-j| est la distance entre les catégories et R est le nombre de catégories.
Exemple de poids linéaires pour un tableau 4x4, où deux cliniciens spécialistes classent les patients en 4 groupes:
## Doctor2
## Doctor1 Stade I Stade II Stade III Stade IV
## Stade I 1 2/3 1/3 0
## Stade II 2/3 1 2/3 1/3
## Stade III 1/3 2/3 1 2/3
## Stade IV 0 1/3 2/3 1Exemple de poids quadratiques:
## Doctor2
## Doctor1 Stade I Stade II Stade III Stade IV
## Stade I 1 8/9 5/9 0
## Stade II 8/9 1 8/9 5/9
## Stade III 5/9 8/9 1 8/9
## Stade IV 0 5/9 8/9 1Notez que les pondérations quadratiques attachent plus d’importance aux désaccords proches. Par exemple, dans le cas où il y a une différence de catégorie entre le diagnostic des deux médecins, le poids linéaire est de 2/3 (0,66). Cela peut être considéré comme un accord de deux-tiers des médecins (ou bien un-tiers de désaccord).
Cependant, le poids quadratique correspondant est de 8/9 (0,89), ce qui est fortement plus élevé et donne presque tout le crédit (90%) lorsqu’il n’y a qu’une seule catégorie de désaccord entre les deux médecins pour évaluer le stade de la maladie.
Cependant, notez que le poids quadratique diminue rapidement lorsqu’il y a deux ou plusieurs différences de catégorie.
Le tableau ci-dessous compare les deux systèmes de pondération côte à côte pour le tableau 4x4:
| Différence | Linéaire | Quadratique |
|---|---|---|
| 0 | 1 | 1 |
| 1 | 0.66 | 0.89 |
| 2 | 0.33 | 0.55 |
| 3 | 0 | 0 |
Interprétation : Ampleur de l’accord
L’interprétation de la force du kappa pondéré est comme celle de kappa non pondéré(Joseph L. Fleiss 2003). Dans la plupart des cas,
- des valeurs supérieures à 0,75 ou plus peuvent être considérées comme un excellent accord au-delà du hasard,
- des valeurs inférieures à 0,40 environ peuvent être considérées comme un mauvais accord au-delà du hasard, et
- des valeurs comprises entre 0,40 et 0,75 peuvent être considérées comme représentatives d’un accord juste à bon au-delà du hasard.
Pour en savoir plus sur l’interprétation kappa, voir (Chapitre @ref(cohen-s-kappa)).
Hypothèses
Vos données doivent répondre aux hypothèses suivantes pour le calcul du kappa pondéré.
- Vous avez deux variables catégorielles de résultats, qui devraient être ordinales
- Les deux variables de résultats doivent avoir exactement les mêmes catégories
- Vous avez des observations appariées ; chaque sujet est classé deux fois par deux évaluateurs ou méthodes indépendants.
- Les mêmes deux évaluateurs sont utilisés pour tous les participants.
Hypothèses statistiques
- Hypothèse nulle (H0):
kappa = 0. L’accord est le même que l’accord aléatoire. - Hypothèse alternative (Ha):
kappa ≠ 0. L’accord est différent d’un accord aléatoire.
Exemple de données
Nous utiliserons le jeu de données de démo sur l’anxiété où deux médecins classent 50 personnes en 4 niveaux d’anxiété ordonnés : “normal” (pas d’anxiété), “modéré”, “élevé”, “très élevé”.
Les données sont organisées dans le tableau de contingence 3x3 suivant:
anxiety <- as.table(
rbind(
c(11, 3, 1, 0), c(1, 9, 0, 1),
c(0, 1, 10, 0 ), c(1, 2, 0, 10)
)
)
dimnames(anxiety) <- list(
Doctor1 = c("Normal", "Moderate", "High", "Very high"),
Doctor2 = c("Normal", "Moderate", "High", "Very high")
)
anxiety## Doctor2
## Doctor1 Normal Moderate High Very high
## Normal 11 3 1 0
## Moderate 1 9 0 1
## High 0 1 10 0
## Very high 1 2 0 10Notez que les niveaux des facteurs doivent être dans l’ordre correct, sinon les résultats seront erronés.
Calcul du kappa pondéré
La fonction R Kappa() [package vcd] peut être utilisée pour calculer le Kappa non pondéré et pondéré. Pour spécifier le type de pondération, utilisez l’argument weights, qui peut être “Equal-Spacing” ou “Fleiss-Cohen”.
Il est à noter que le Kappa non pondéré représente le Kappa standard de Cohen, qui ne devrait être prise en compte que pour les variables nominales. Vous pouvez en savoir plus dans le chapitre dédié.
library("vcd")
# Calculer kapa
res.k <- Kappa(anxiety)
res.k## value ASE z Pr(>|z|)
## Unweighted 0.733 0.0752 9.75 1.87e-22
## Weighted 0.747 0.0791 9.45 3.41e-21# Intervalles de confiance
confint(res.k)##
## Kappa lwr upr
## Unweighted 0.586 0.881
## Weighted 0.592 0.903# Résumé montrant les poids attribués à chaque cellule
summary(res.k)## value ASE z Pr(>|z|)
## Unweighted 0.733 0.0752 9.75 1.87e-22
## Weighted 0.747 0.0791 9.45 3.41e-21
##
## Weights:
## [,1] [,2] [,3] [,4]
## [1,] 1.000 0.667 0.333 0.000
## [2,] 0.667 1.000 0.667 0.333
## [3,] 0.333 0.667 1.000 0.667
## [4,] 0.000 0.333 0.667 1.000Notez que, dans les résultats ci-dessus, ASE est l’erreur type asymptotique de la valeur kappa.
Dans notre exemple, le kappa pondéré (k) = 0,73, ce qui représente un bon degré d’accord (p < 0,0001). En conclusion, il y avait un accord statistiquement significatif entre les deux médecins.
Rapporter
Le kappa pondéré (kw) avec un système linéaire (Cicchetti and Allison 1971) a été calculé pour évaluer s’il y avait accord entre deux médecins sur le diagnostic de la gravité de l’anxiété. 50 participants ont été inscrits et ont été classés par chacun des deux médecins en 4 niveaux d’anxiété ordonnés : “normal”, “modéré”, “élevé”, “très élevé”.
Il y avait un accord statistiquement significatif entre les deux médecins, kw = 0,75 (IC à 95 %, 0,59 à 0,90), p < 0,0001. La force de l’accord est classée comme bonne selon Fleiss et al. (2003).
Résumé
Ce chapitre explique les bases et la formule du kappa pondéré, qui est appropriée pour mesurer l’accord entre deux évaluateurs retournant des variables ordinales. Nous montrons également comment calculer et interpréter les valeurs kappa à l’aide du logiciel R. D’autres variantes de mesures de concordance inter-évaluateurs sont : le Kappa de Cohen (non pondéré) (chapitre @ref(cohen-s-kappa)), qui ne tient compte que des concordances stricts; le kappa de Fleiss pour les situations où vous avez plusieurs évaluateurs (deux ou plus) (chapitre @ref(fleiss-kappa))).
References
Cicchetti, Domenic V., and Truett Allison. 1971. “A New Procedure for Assessing Reliability of Scoring Eeg Sleep Recordings.” American Journal of EEG Technology 11 (3). Taylor; Francis: 101–10. doi:10.1080/00029238.1971.11080840.
Cohen, J. 1968. “Weighted Kappa: Nominal Scale Agreement with Provision for Scaled Disagreement or Partial Credit.” Psychological Bulletin 70 (4): 213—220. doi:10.1037/h0026256.
Fleiss, Joseph L., and Jacob Cohen. 1973. “The Equivalence of Weighted Kappa and the Intraclass Correlation Coefficient as Measures of Reliability.” Educational and Psychological Measurement 33 (3): 613–19. doi:10.1177/001316447303300309.
Friendly, Michael, D. Meyer, and A. Zeileis. 2015. Discrete Data Analysis with R: Visualization and Modeling Techniques for Categorical and Count Data. 1st ed. Chapman; Hall/CRC.
Joseph L. Fleiss, Myunghee Cho Paik, Bruce Levin. 2003. Statistical Methods for Rates and Proportions. 3rd ed. John Wiley; Sons, Inc.
Tang, Wan, Jun Hu, Hui Zhang, Pan Wu, and Hua He. 2015. “Kappa Coefficient: A Popular Measure of Rater Agreement.” Shanghai Archives of Psychiatry 27 (February): 62–67. doi:10.11919/j.issn.1002-0829.215010.
Warrens, Matthijs J. 2013. “Weighted Kappas for 3x3 Tables.” Journal of Probability and Statistics. doi:https://doi.org/10.1155/2013/325831.
Version:
 English
English

Comment choisir les systèmes de pondération kappa ?
Si vous considérez chaque différence de catégorie comme également importante, vous devriez choisir des poids linéaires (c.-à-d. des poids d’espacement égaux).
En d’autres termes: