Cet article explique comment visualiser la distribution de données dans R en utilisant des courbes de densité ridgeline. Le graphique de densité ridgeline [package ggridges] est une alternative à la fonction standard geom_density() [package ggplot2] qui peut être utile pour visualiser les changements dans les distributions, d’une variable continue, dans le temps ou dans l’espace. Les graphiques ridgeline sont des line plots qui se chevauchent partiellement et donnent l’impression d’une chaîne de montagnes.
Vous apprendrez à:
- Créer des graphiques ridgelines basiques
- Ajouter des couleurs de remplissage dégradées sous les courbes
- Ajouter des statistiques descriptives telles que des lignes de quantiles sur les graphiques de densité
- Ajouter des points de données originaux sur les courbes de densité
![]()
Sommaire:
- Prérequis
- Graphiques de densités ridgelines basiques
- Courbes de densité avec des couleurs de remplissage en gradient le long de l’axe des x
- Ajouter des lignes de statistiques descriptives
- Ajouter les points de données originaux sur les courbes de densité
- Créer des distributions d’histogrammes en utilisant ridgeline
- Changer de thème
- Conclusion
Prérequis
Charger les packages R requis:
library(ggplot2)
library(ggridges)
theme_set(theme_minimal())Fonctions R clés:
geom_density_ridges(): estime d’abord les densités de données et dessine ensuite celles ci en utilisant des ridgelines. Il dispose les graphiques à densité multiple de manière étagée.
Graphiques de densités ridgelines basiques
Fonctions R clés:
geom_density_ridges(): Estimes des densités de données, puis dessine celles-ci avec des ridglines. Il dispose les graphiques à densité multiple de manière étagée.
# Polygones ouverts
ggplot(iris, aes(x = Sepal.Length, y = Species, group = Species)) +
geom_density_ridges(fill = "#00AFBB")
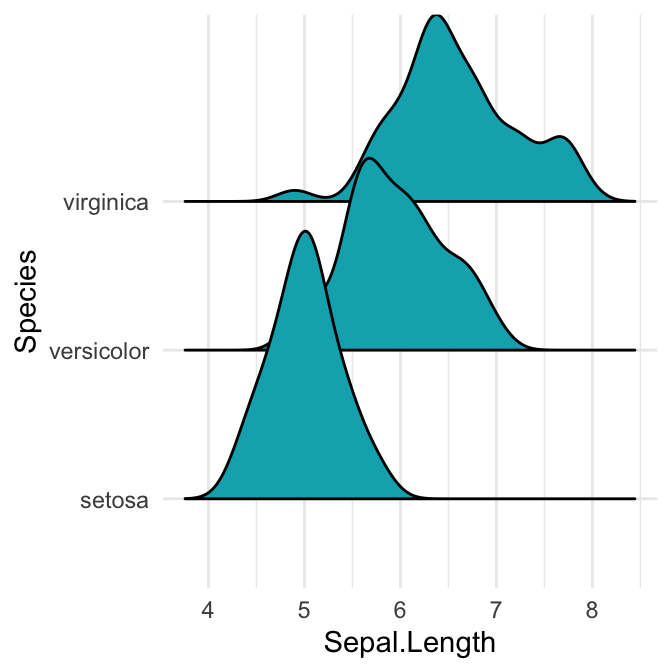
# Polygones fermés
ggplot(iris, aes(x = Sepal.Length, y = Species, group = Species)) +
geom_density_ridges2(fill = "#00AFBB")
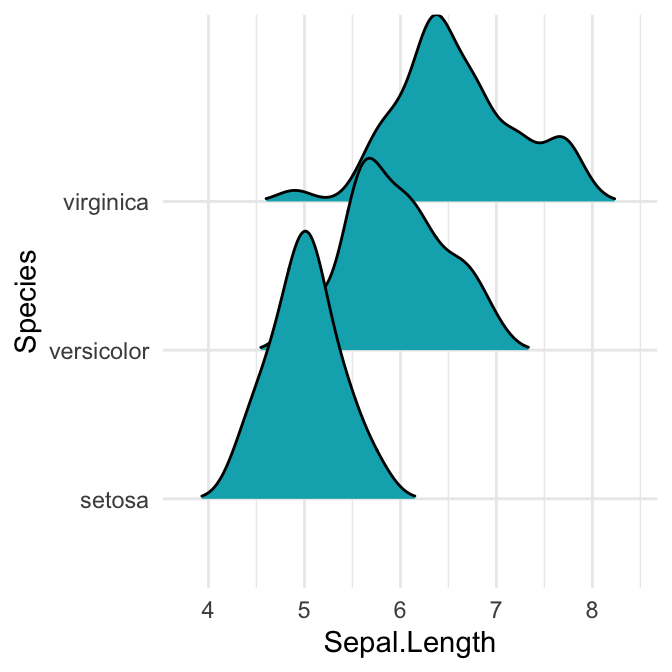
# Couper les queues.
# Précisez `rel_min_height` : un pourcentage de seuil de coupure
ggplot(iris, aes(x = Sepal.Length, y = Species)) +
geom_density_ridges(fill = "#00AFBB", rel_min_height = 0.01)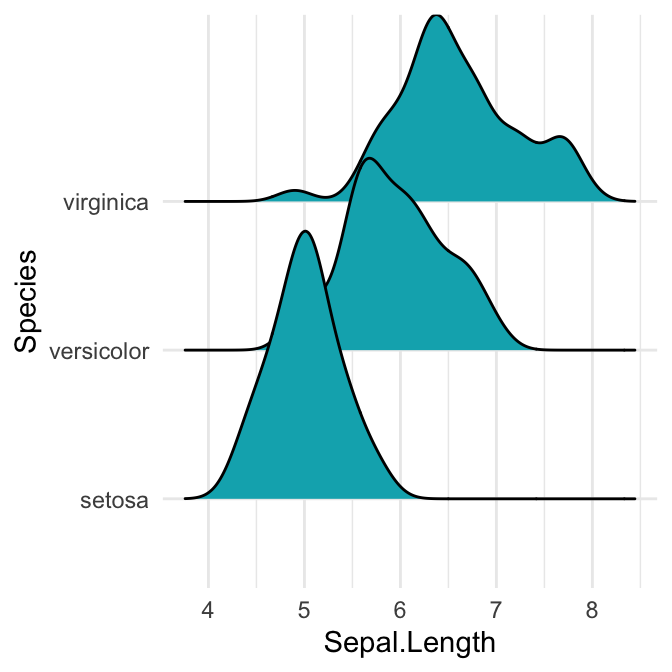
Notez que l’esthétique de regroupement n’a pas besoin d’être fournie si une variable catégorielle est placée sur l’axe des y, mais elle doit être fournie si la variable est numérique.
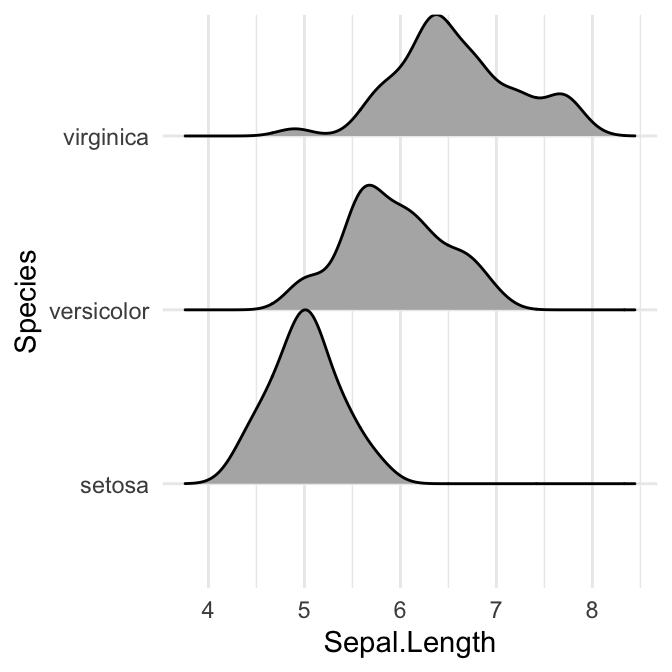
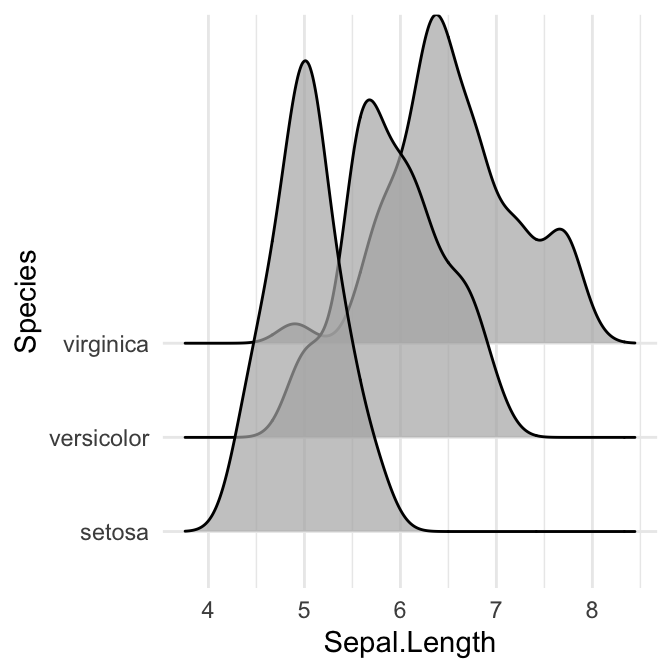
Contrôler la mesure dans laquelle les différentes densités se chevauchent. Vous pouvez contrôler le chevauchement entre les différentes courbes de densité en utilisant l’option scale. La valeur par défaut est de 1. Des valeurs plus petites créent une séparation entre les courbes, et des valeurs plus grandes créent plus de chevauchement.
# scale = 0,6, courbes séparées
ggplot(iris, aes(x = Sepal.Length, y = Species)) +
geom_density_ridges(scale = 0.6)
# scale = 1, courbes se touchant exactement
ggplot(iris, aes(x = Sepal.Length, y = Species)) +
geom_density_ridges(scale = 1)
# scale = 5, chevauchement important
ggplot(iris, aes(x = Sepal.Length, y = Species)) +
geom_density_ridges(scale = 5, alpha = 0.7)
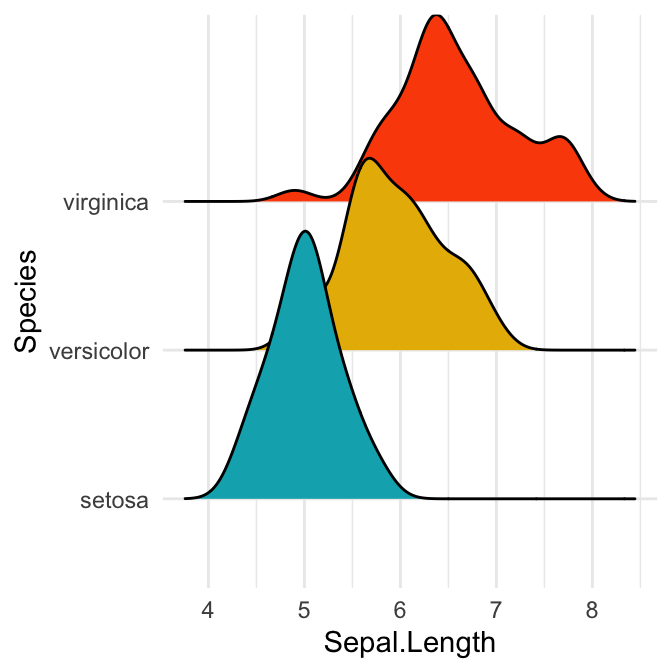
# Modifier les couleurs de remplissage de la zone de densité par groupes
ggplot(iris, aes(x = Sepal.Length, y = Species)) +
geom_density_ridges(aes(fill = Species)) +
scale_fill_manual(values = c("#00AFBB", "#E7B800", "#FC4E07")) +
theme(legend.position = "none")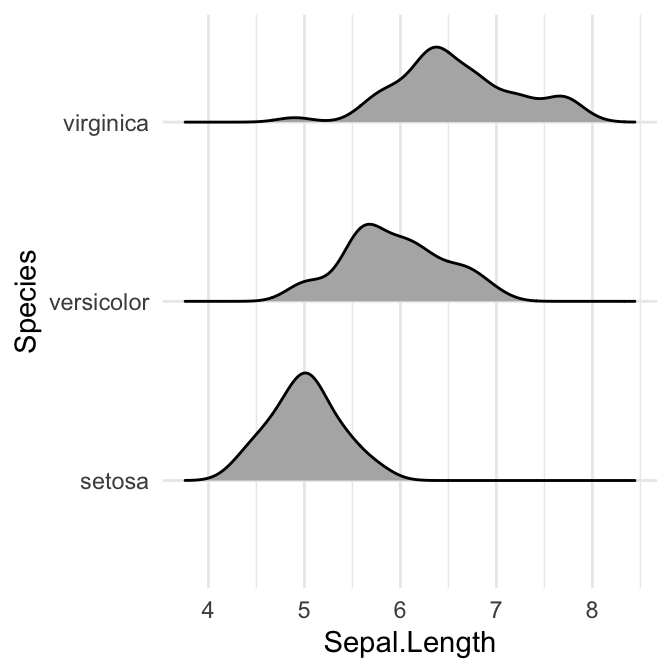
Courbes de densité avec des couleurs de remplissage en gradient le long de l’axe des x
Cet effet peut être obtenu avec la fonction geom_density_ridges_gradient(), qui fonctionne comme geom_density_ridges, sauf qu’elle permet de varier les couleurs de remplissage.
Notez que, pour des raisons techniques, geom_density_ridges_gradient() ne permet pas la transparence alpha dans le remplissage.
Visualiser les données météorologiques de Lincoln:
- Jeu de données :
lincoln_weather[dans ggridges]. Météo à Lincoln, Nebraska en 2016. - Créez les courbes de densité de
Mean Temperature( “température moyenne”) parMonth(“mois”) et changez la couleur de remplissage en fonction de la valeur de la température (sur l’axe des x).
ggplot(
lincoln_weather,
aes(x = `Mean Temperature [F]`, y = `Month`, fill = stat(x))
) +
geom_density_ridges_gradient(scale = 3, size = 0.3, rel_min_height = 0.01) +
scale_fill_viridis_c(name = "Temp. [F]", option = "C") +
labs(title = 'Temperatures in Lincoln NE') 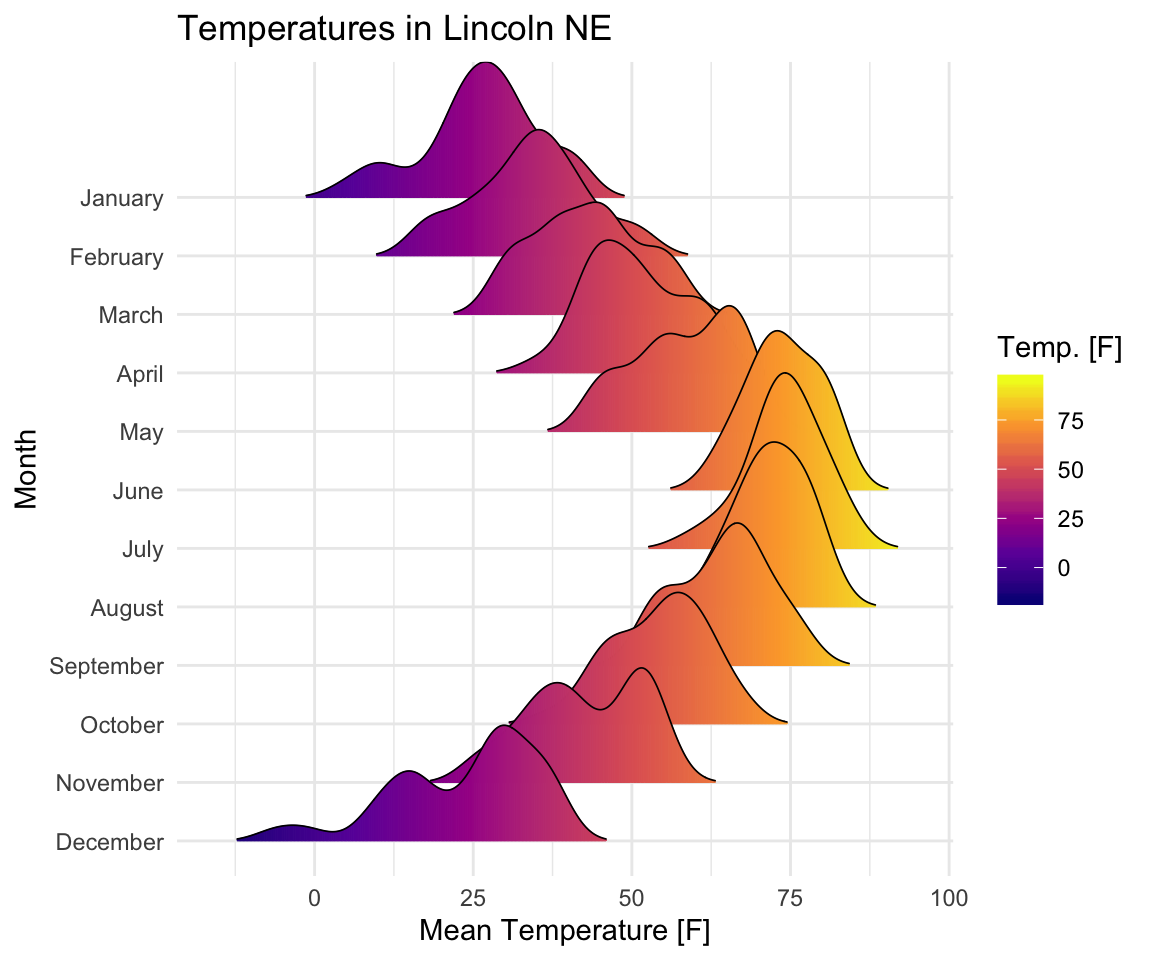
Ajouter des lignes de statistiques descriptives
Ajouter des lignes de quantile
Fonction R clé: stat_density_ridges(). Par défaut, trois lignes sont tracées, correspondant au premier, deuxième et troisième quartile.
# Ajouter les quantiles Q1, Q2 (médiane) et Q3
ggplot(iris, aes(x = Sepal.Length, y = Species)) +
stat_density_ridges(quantile_lines = TRUE)
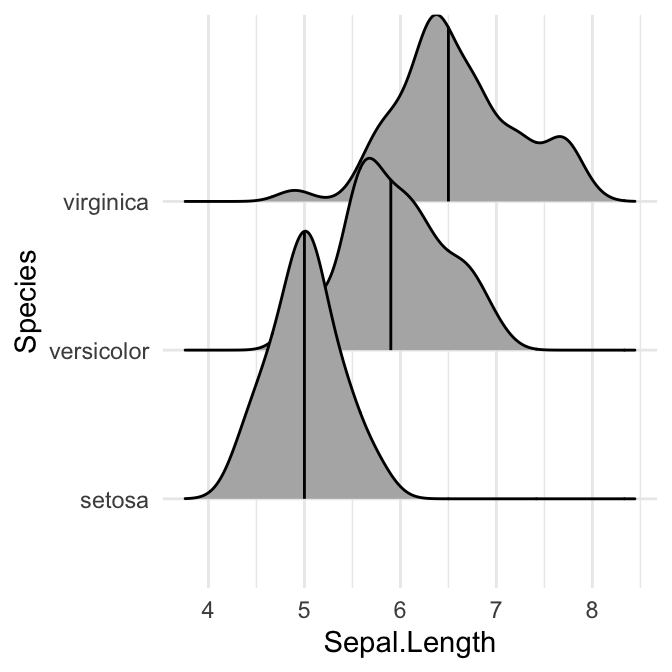
# Afficher uniquement la ligne médiane (50%)
# Utiliser quantiles = 2 (pour Q2) ou quantiles = 50/100
ggplot(iris, aes(x = Sepal.Length, y = Species)) +
stat_density_ridges(quantile_lines = TRUE, quantiles = 0.5)
# Indiquez les queues de 2,5 % et de 97,5%
ggplot(iris, aes(x = Sepal.Length, y = Species)) +
stat_density_ridges(quantile_lines = TRUE, quantiles = c(0.025, 0.975), alpha = 0.7)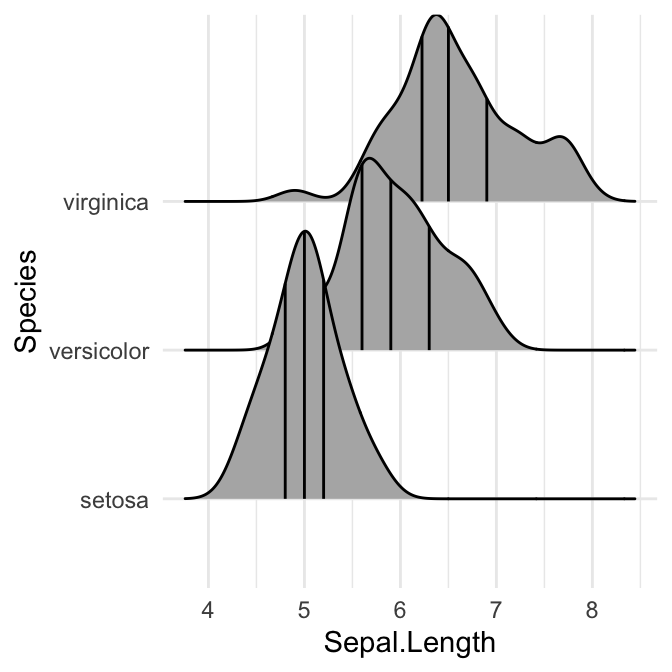
Colorer la zone de densité par des quantiles
Vous devez spécifier l’option calc_ecdf = TRUE requise pour le calcul des quantiles. L’ECDF représente la fonction de densité cumulative empirique de distribution.
# Colorer en fonction des quantiles
ggplot(iris, aes(x = Sepal.Length, y = Species, fill = factor(stat(quantile)))) +
stat_density_ridges(
geom = "density_ridges_gradient", calc_ecdf = TRUE,
quantiles = 4, quantile_lines = TRUE
) +
scale_fill_viridis_d(name = "Quartiles")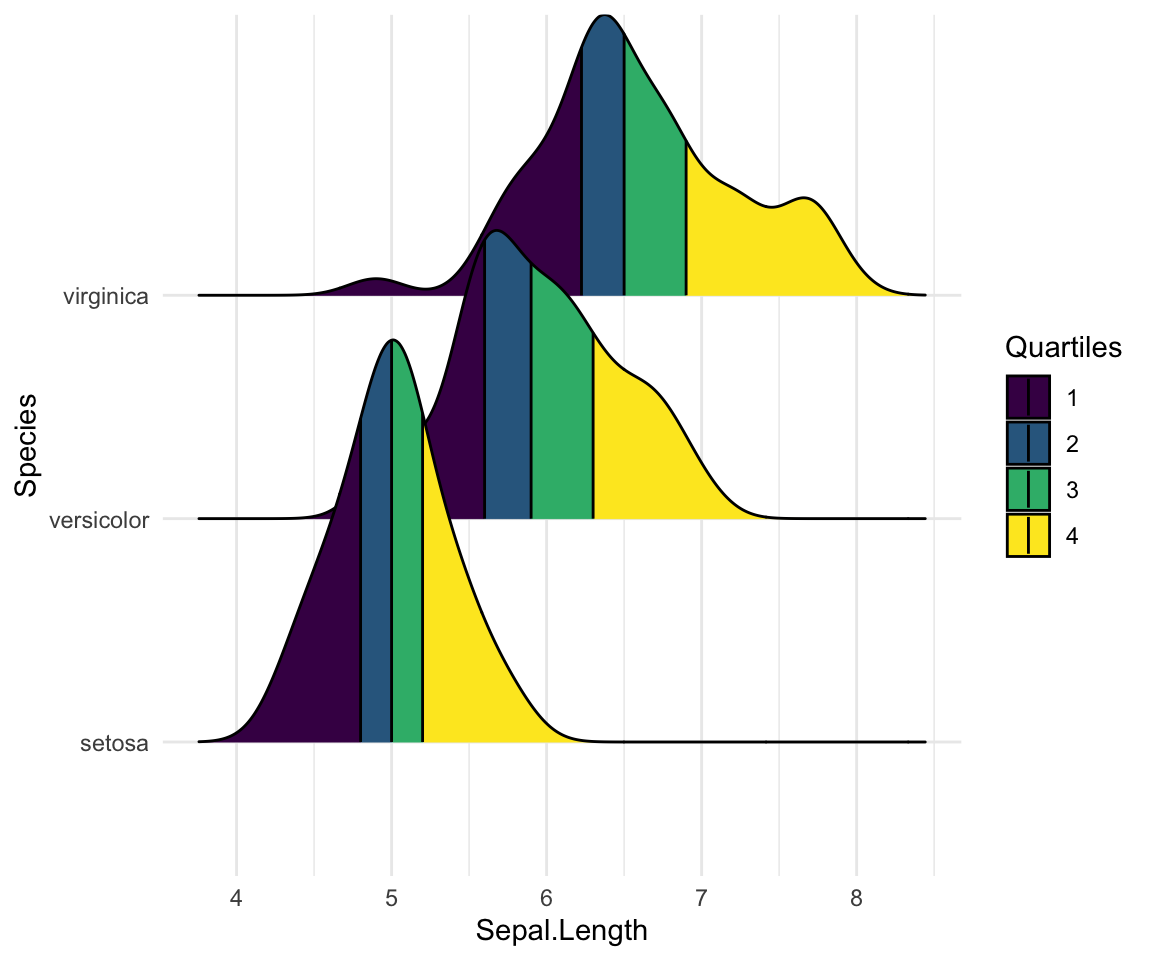
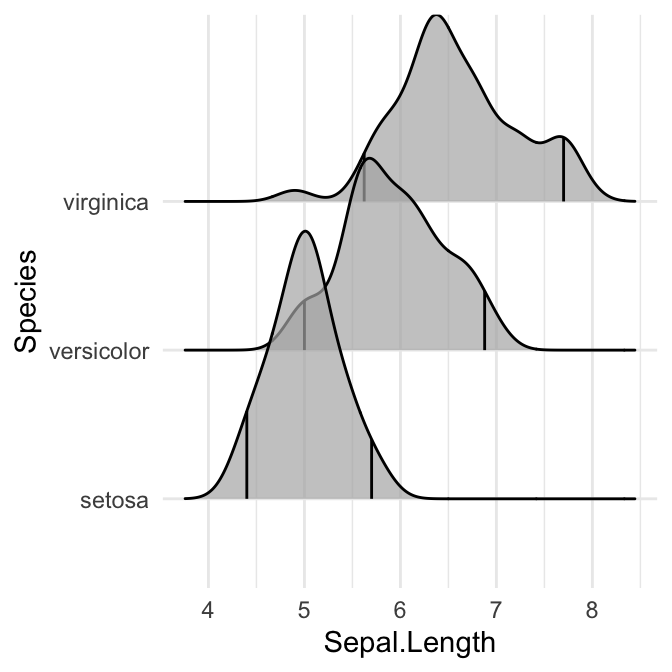
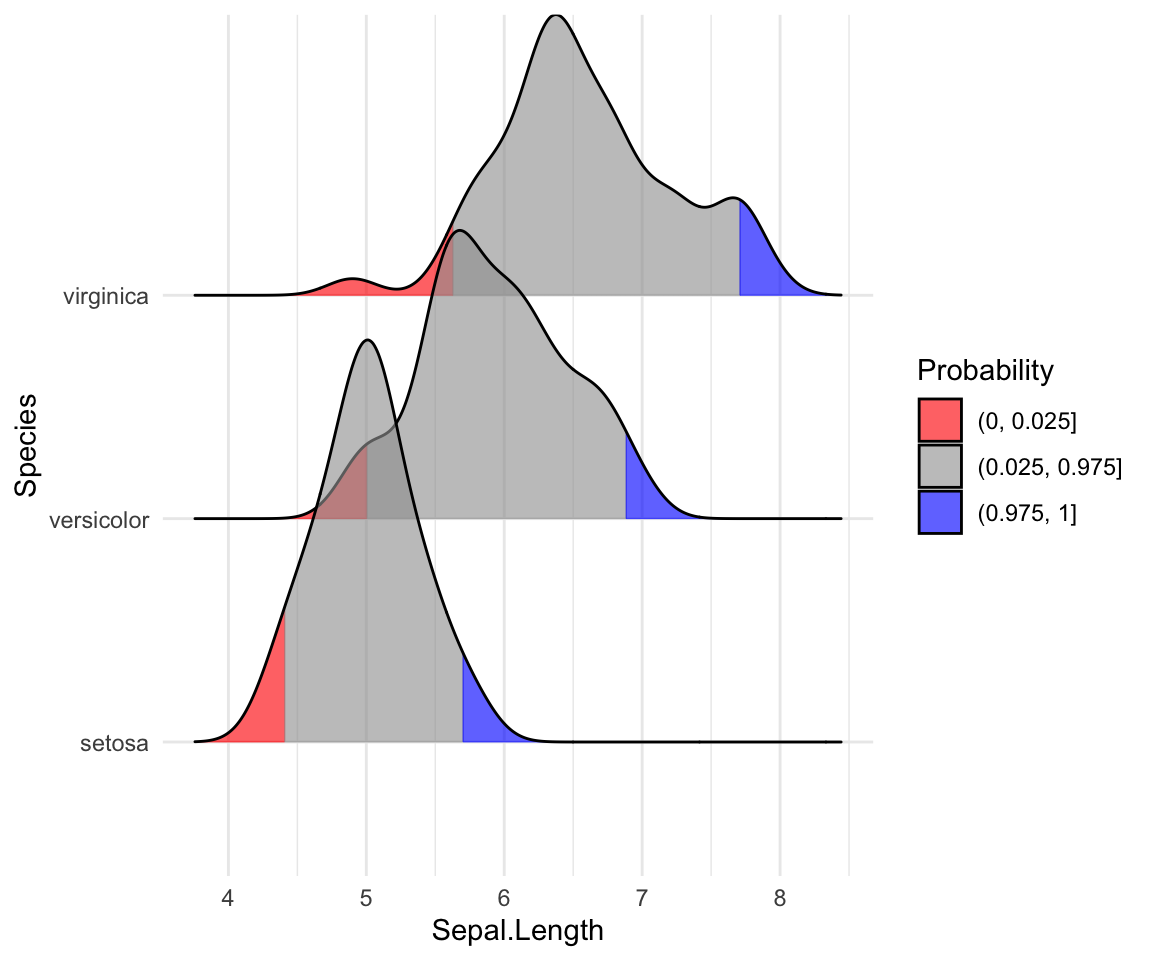
# Mettre en évidence les queues des distributions
ggplot(iris, aes(x = Sepal.Length, y = Species, fill = factor(stat(quantile)))) +
stat_density_ridges(
geom = "density_ridges_gradient",
calc_ecdf = TRUE,
quantiles = c(0.025, 0.975)
) +
scale_fill_manual(
name = "Probability", values = c("#FF0000A0", "#A0A0A0A0", "#0000FFA0"),
labels = c("(0, 0.025]", "(0.025, 0.975]", "(0.975, 1]")
)
Colorier les courbes de densité par des probabilités
Lorsque calc_ecdf = TRUE, nous avons également accès à un esthétique stat(ecdf) calculé, qui représente la fonction de densité cumulative empirique pour la distribution. Cela nous permet de mapper les probabilités directement sur la couleur.
ggplot(iris, aes(x = Sepal.Length, y = Species, fill = 0.5 - abs(0.5 - stat(ecdf)))) +
stat_density_ridges(geom = "density_ridges_gradient", calc_ecdf = TRUE) +
scale_fill_viridis_c(name = "Tail probability", direction = -1)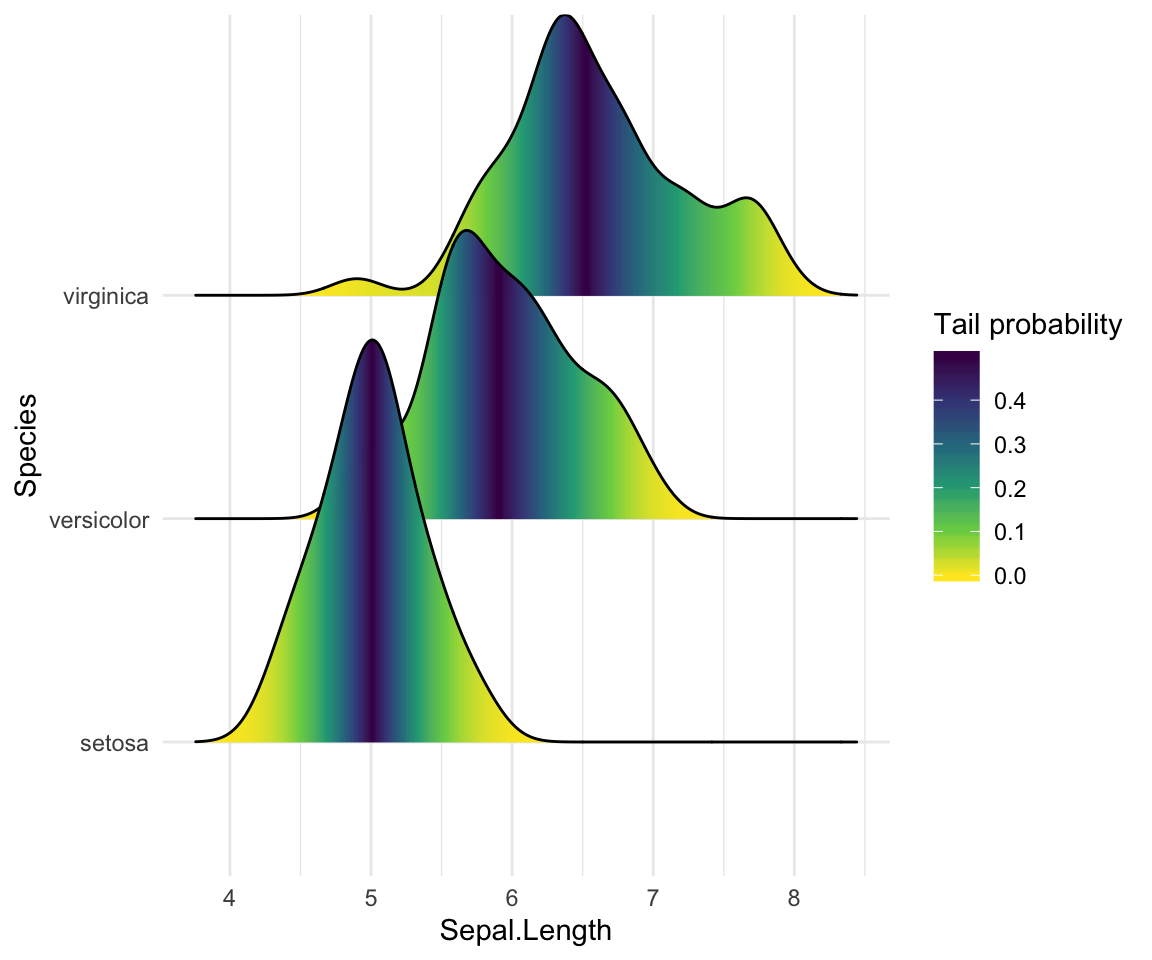
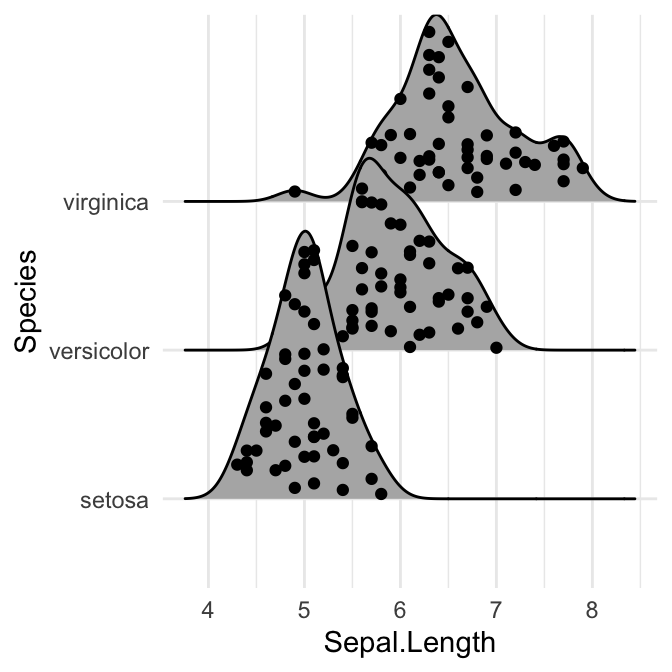
Ajouter les points de données originaux sur les courbes de densité
Cela peut être fait en définissant jittered_points = TRUE, soit dans stat_density_ridges soit dans geom_density_ridges.
La position des points de données peut être contrôlée en utilisant les options suivantes:
position = "sina": Répartit au hasard les points d’un graphique ridgeline entre la ligne de base et la ligne de crête. C’est l’option par défaut.position = "jitter": Distribue aléatoirement les points sur un graphique ridgeline. Les points sont disposés de manière aléatoire de haut en bas et/ou de gauche à droite.position = "raincloud": Crée un nuage de points aléatoirement distribués sous un graphique ridgeline.
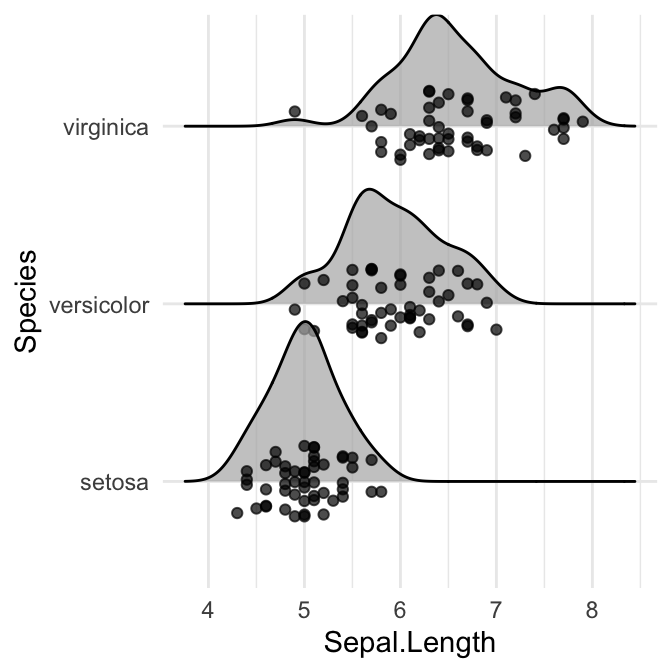
# Ajouter des points dispersés (jitter)
ggplot(iris, aes(x = Sepal.Length, y = Species)) +
geom_density_ridges(jittered_points = TRUE)
# Contrôler la position des points
# position = "raincloud"
ggplot(iris, aes(x = Sepal.Length, y = Species)) +
geom_density_ridges(
jittered_points = TRUE, position = "raincloud",
alpha = 0.7, scale = 0.9
)
# position = "points_jitter"
ggplot(iris, aes(x = Sepal.Length, y = Species)) +
geom_density_ridges(
jittered_points = TRUE, position = "points_jitter",
alpha = 0.7, scale = 0.9
)
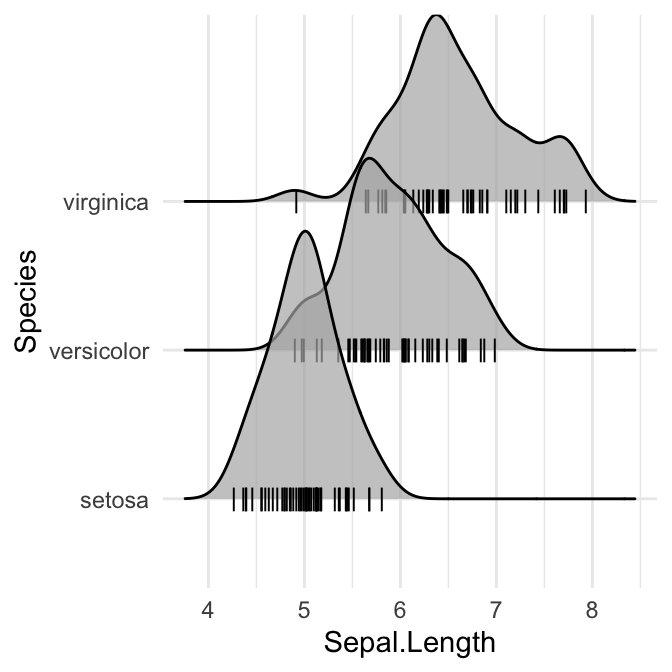
# Ajouter des rugs marginaux
ggplot(iris, aes(x = Sepal.Length, y = Species)) +
geom_density_ridges(
jittered_points = TRUE,
position = position_points_jitter(width = 0.05, height = 0),
point_shape = '|', point_size = 3, point_alpha = 1, alpha = 0.7,
)
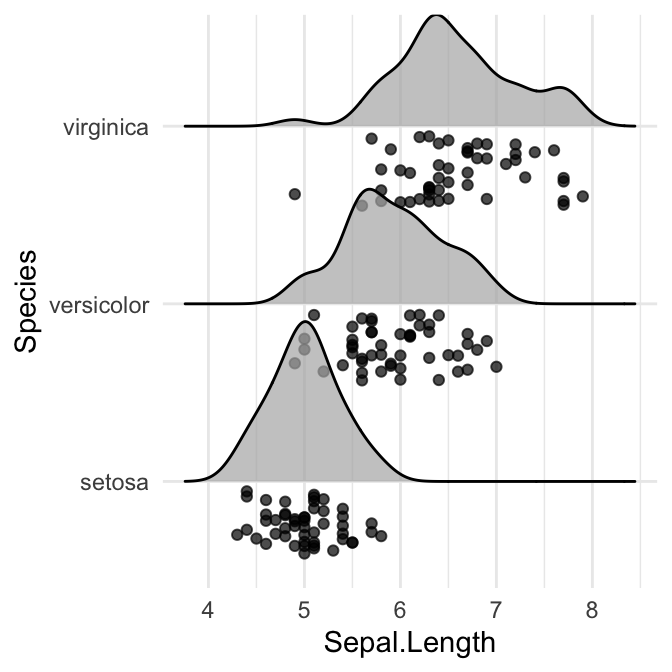
Styliser les points et ajouter des lignes de quantification.
# Personnalisation des points
ggplot(iris, aes(x = Sepal.Length, y = Species, fill = Species)) +
geom_density_ridges(
aes(point_color = Species, point_fill = Species, point_shape = Species),
alpha = .2, point_alpha = 1, jittered_points = TRUE
) +
scale_point_color_hue(l = 40) +
scale_discrete_manual(aesthetics = "point_shape", values = c(21, 22, 23))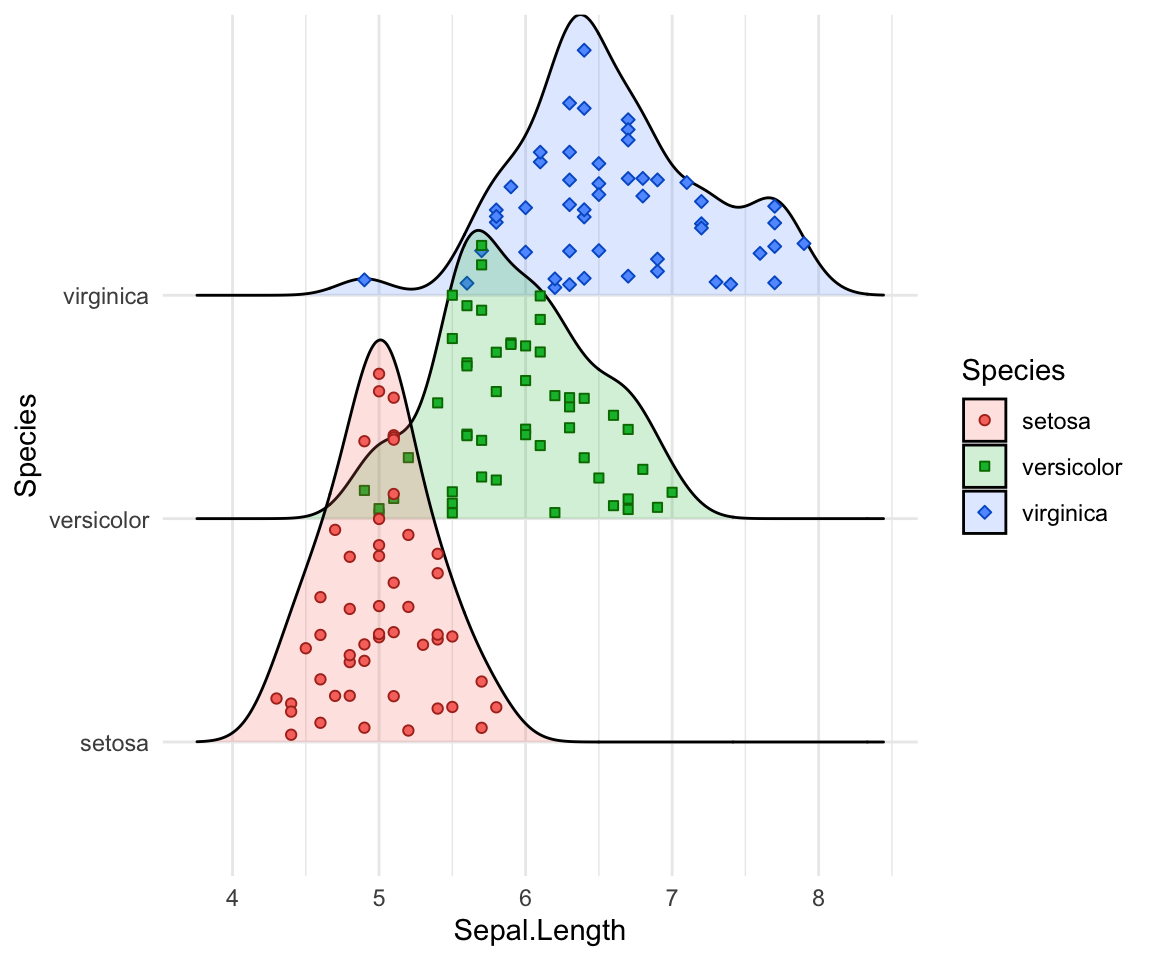
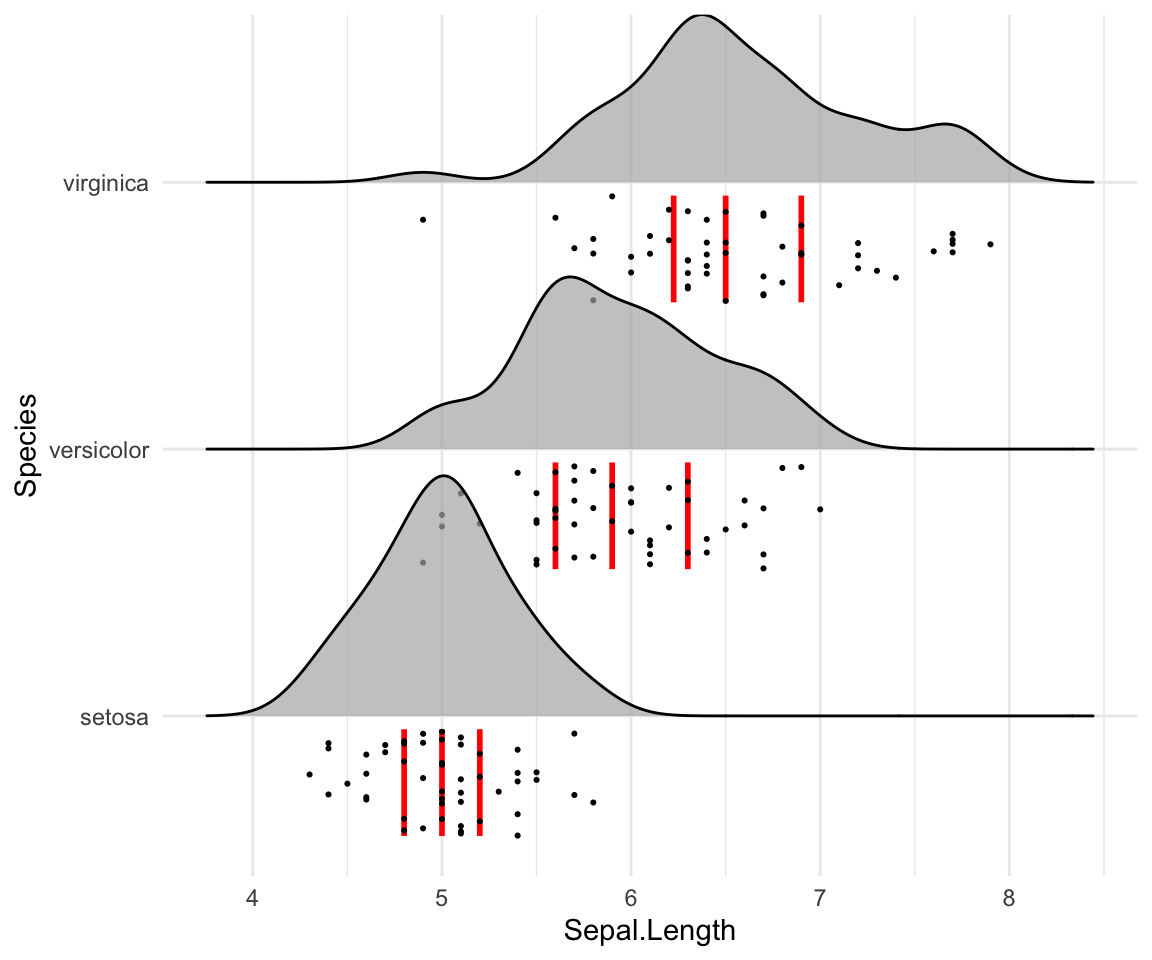
# Styliser les lignes de quantile verticales
ggplot(iris, aes(x = Sepal.Length, y = Species)) +
geom_density_ridges(
jittered_points = TRUE, quantile_lines = TRUE, scale = 0.9, alpha = 0.7,
vline_size = 1, vline_color = "red",
point_size = 0.4, point_alpha = 1,
position = position_raincloud(adjust_vlines = TRUE)
)
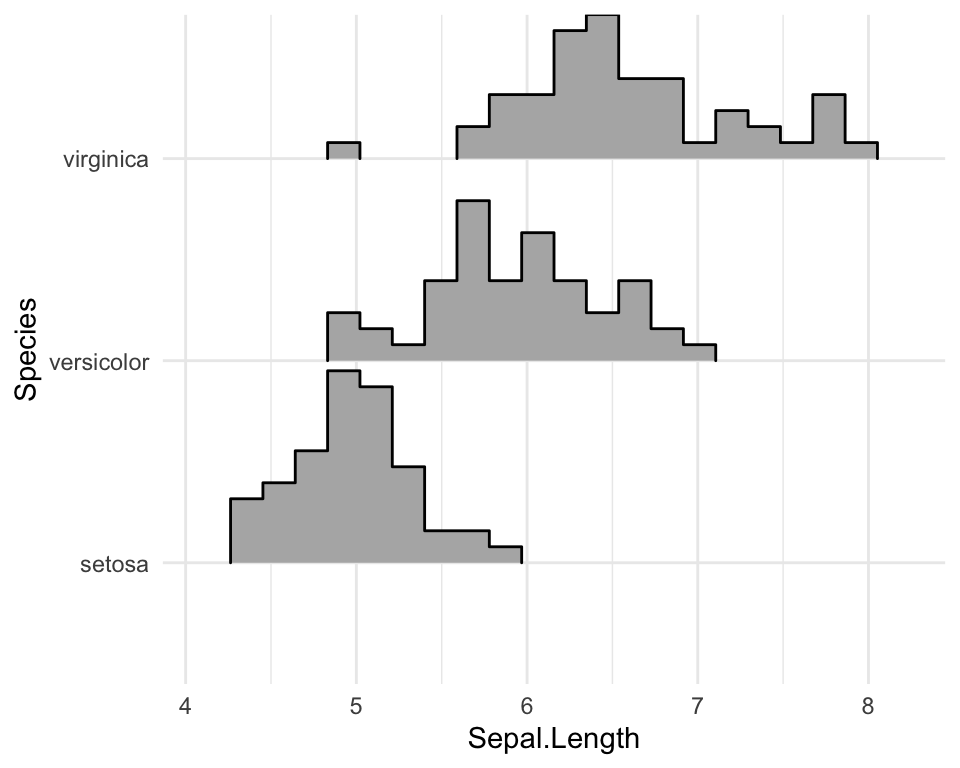
Créer des distributions d’histogrammes en utilisant ridgeline
Utilisez les options suivantes:
stat = "binline": Crée des histogrammesdraw_baseline = FALSE: Supprime les lignes de queue de chaque côté de l’histogramme. Pour les histogrammes, le paramètrerel_min_heightne fonctionne pas très bien.
ggplot(iris, aes(x = Sepal.Length, y = Species, height = stat(density))) +
geom_density_ridges(
stat = "binline", bins = 20, scale = 0.95,
draw_baseline = FALSE
)
Changer de thème
# Utilisez theme_ridges()
ggplot(iris, aes(x = Sepal.Length, y = Species)) +
geom_density_ridges() +
theme_ridges()
# Supprimer les grilles
ggplot(iris, aes(x = Sepal.Length, y = Species)) +
geom_density_ridges() +
theme_ridges(grid = FALSE, center_axis_labels = TRUE)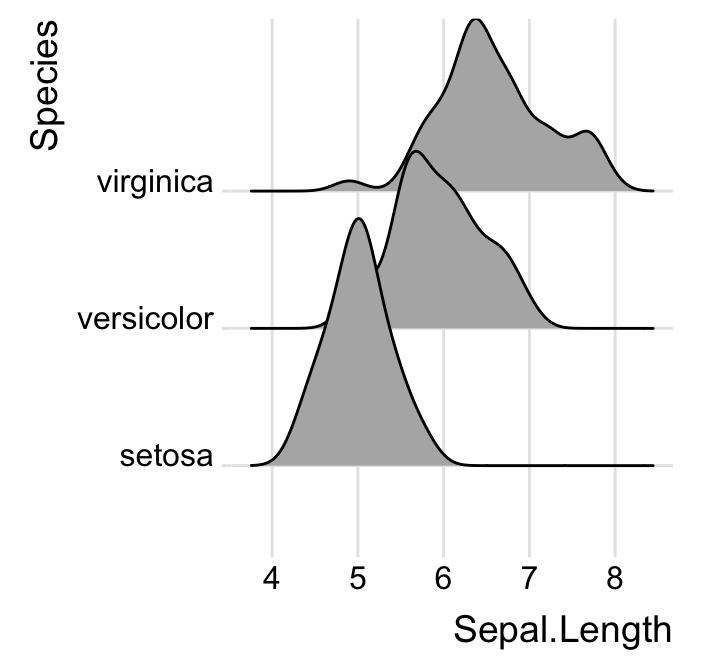
Conclusion
Cet article explique comment visualiser la distribution de données dans R en utilisant des courbes de densité ridgeline.
Version:
 English
English




No Comments