

Description
Although there are several good books on principal component methods (PCMs) and related topics, we felt that many of them are either too theoretical or too advanced.
This book provides a solid practical guidance to summarize, visualize and interpret the most important information in a large multivariate data sets, using principal component methods in R.
The following figure illustrates the type of analysis to be performed depending on the type of variables contained in the data set.
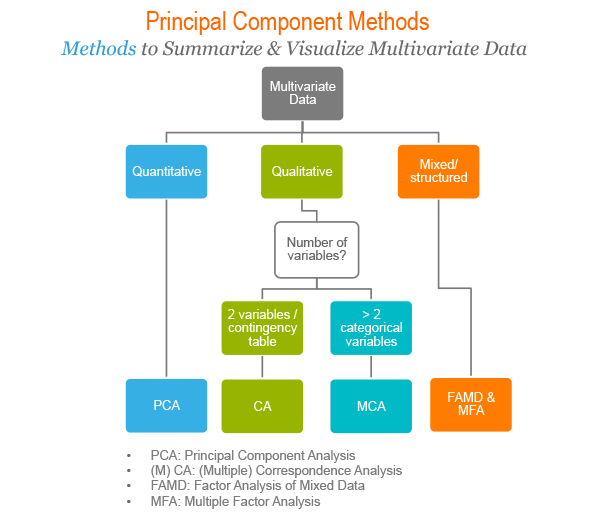
There are a number of R packages implementing principal component methods. These packages include: FactoMineR, ade4, stats, ca, MASS and ExPosition.
However, the result is presented differently depending on the used package.
To help in the interpretation and in the visualization of multivariate analysis - such as cluster analysis and principal component methods - we developed an easy-to-use R package named factoextra.
No matter which package you decide to use for computing principal component methods, the factoextra R package can help to extract easily, in a human readable data format, the analysis results from the different packages mentioned above. factoextra provides also convenient solutions to create ggplot2-based beautiful graphs.
Methods, which outputs can be visualized using the factoextra package are shown in the figure below:
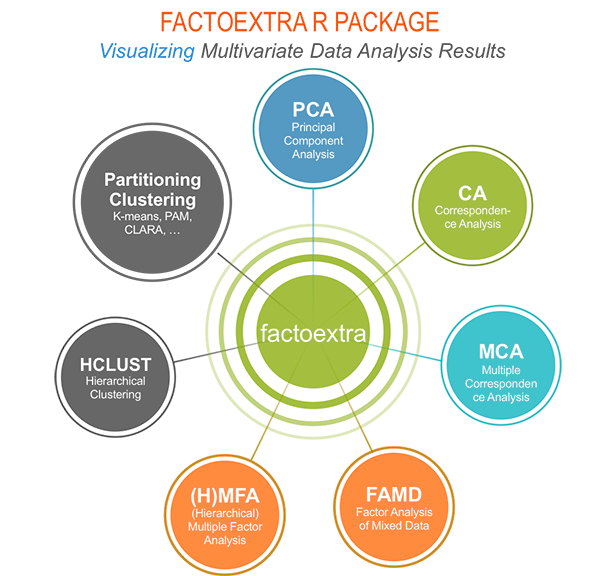
In this book, we’ll use mainly:
- the FactoMineR package to compute principal component methods;
- and the factoextra package for extracting, visualizing and interpreting the results.
The other packages - ade4, ExPosition, etc - will be also presented briefly.
How this book is organized
This book contains 4 parts.

Part I provides a quick introduction to R and presents the key features of FactoMineR and factoextra.
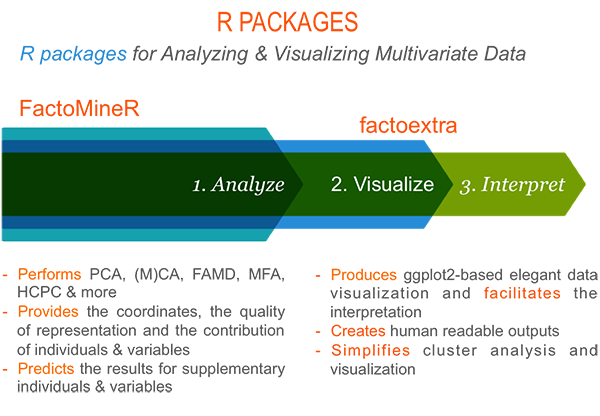
Part II describes classical principal component methods to analyze data sets containing, predominantly, either continuous or categorical variables. These methods include:
- Principal Component Analysis (PCA, for continuous variables),
- Simple correspondence analysis (CA, for large contingency tables formed by two categorical variables)
- Multiple correspondence analysis (MCA, for a data set with more than 2 categorical variables).
In Part III, you’ll learn advanced methods for analyzing a data set containing a mix of variables (continuous and categorical) structured or not into groups:
- Factor Analysis of Mixed Data (FAMD) and,
- Multiple Factor Analysis (MFA).
Part IV covers hierarchical clustering on principal components (HCPC), which is useful for performing clustering with a data set containing only categorical variables or with a mixed data of categorical and continuous variables
Key features of this book
This book presents the basic principles of the different methods and provide many examples in R. This book offers solid guidance in data mining for students and researchers.
Key features:
- Covers principal component methods and implementation in R
- Highlights the most important information in your data set using ggplot2-based elegant visualization
- Short, self-contained chapters with tested examples that allow for flexibility in designing a course and for easy reference
At the end of each chapter, we present R lab sections in which we systematically work through applications of the various methods discussed in that chapter. Additionally, we provide links to other resources and to our hand-curated list of videos on principal component methods for further learning.
Examples of plots
Some examples of plots generated in this book are shown hereafter. You’ll learn how to create, customize and interpret these plots.
- Eigenvalues/variances of principal components. Proportion of information retained by each principal component.
- PCA - Graph of variables:
- Control variable colors using their contributions to the principal components.
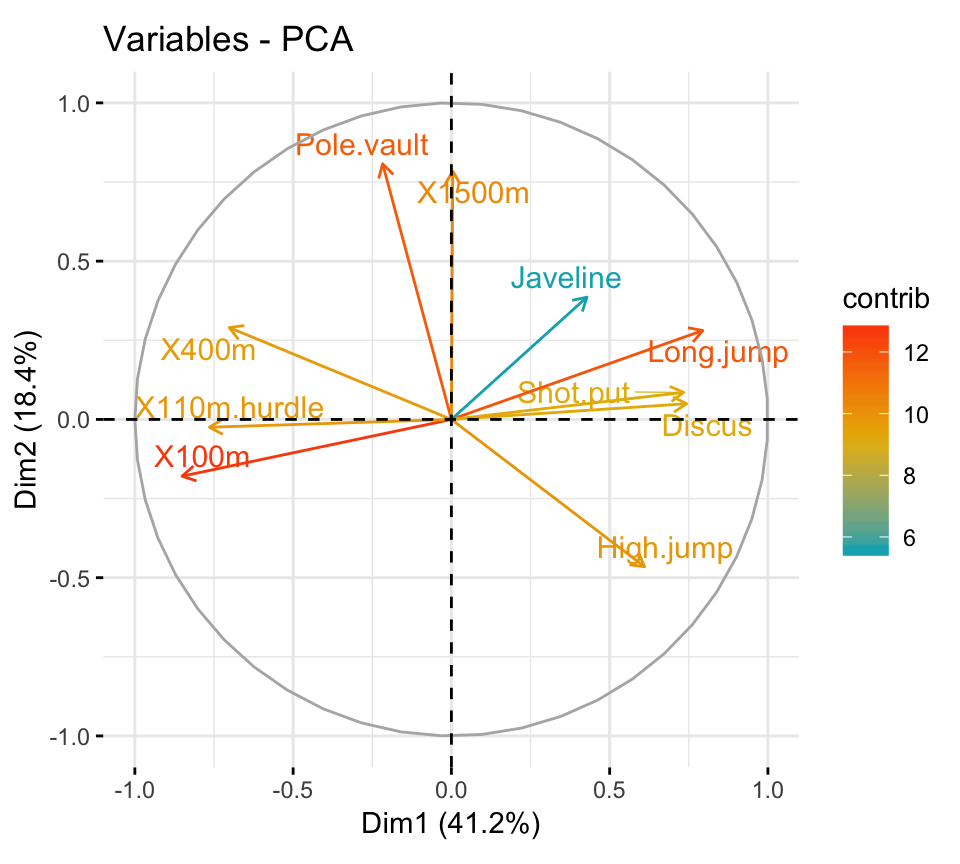
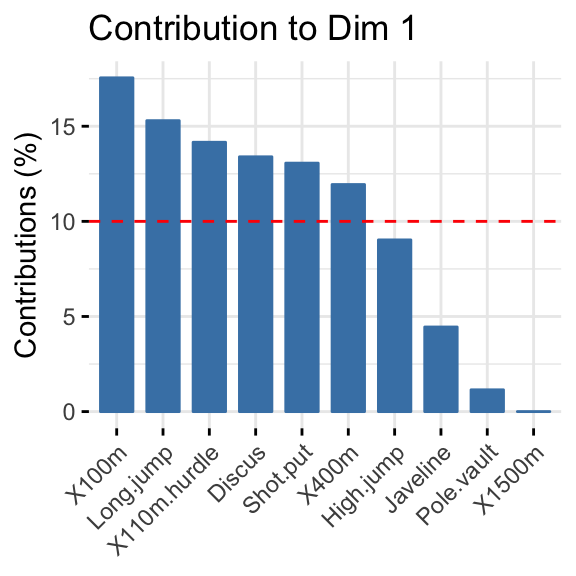
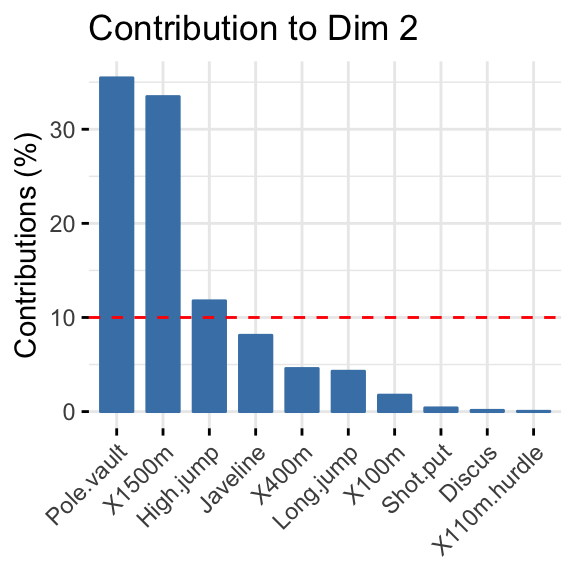
- Highlight the most contributing variables to each principal dimension:
- PCA - Graph of individuals:
- Control automatically the color of individuals using the cos2 (the quality of the individuals on the factor map)
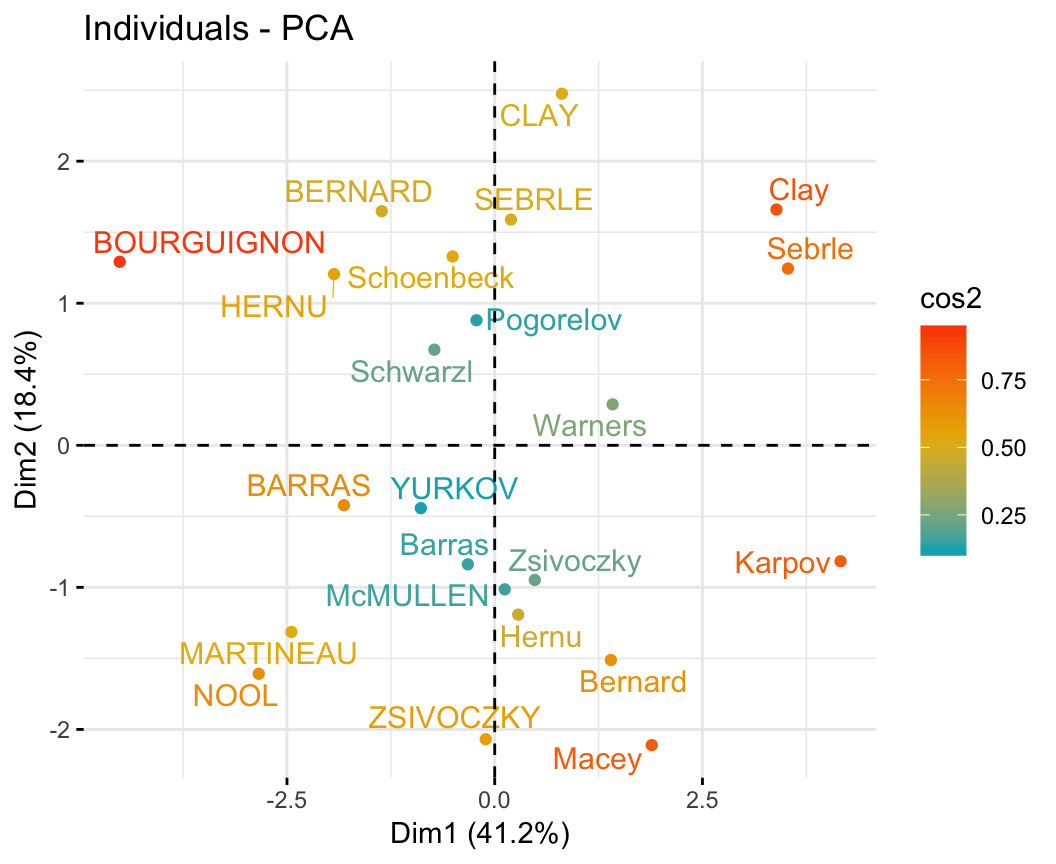
- Change the point size according to the cos2 of the corresponding individuals:
- PCA - Biplot of individuals and variables
- Correspondence analysis. Association between categorical variables.
- FAMD/MFA - Analyzing mixed and structured data
- Clustering on principal components
Recommended for you
This section contains best data science and self-development resources to help you on your path.
Coursera - Online Courses and Specialization
Data science
- Course: Machine Learning: Master the Fundamentals by Stanford
- Specialization: Data Science by Johns Hopkins University
- Specialization: Python for Everybody by University of Michigan
- Courses: Build Skills for a Top Job in any Industry by Coursera
- Specialization: Master Machine Learning Fundamentals by University of Washington
- Specialization: Statistics with R by Duke University
- Specialization: Software Development in R by Johns Hopkins University
- Specialization: Genomic Data Science by Johns Hopkins University
Popular Courses Launched in 2020
- Google IT Automation with Python by Google
- AI for Medicine by deeplearning.ai
- Epidemiology in Public Health Practice by Johns Hopkins University
- AWS Fundamentals by Amazon Web Services
Trending Courses
- The Science of Well-Being by Yale University
- Google IT Support Professional by Google
- Python for Everybody by University of Michigan
- IBM Data Science Professional Certificate by IBM
- Business Foundations by University of Pennsylvania
- Introduction to Psychology by Yale University
- Excel Skills for Business by Macquarie University
- Psychological First Aid by Johns Hopkins University
- Graphic Design by Cal Arts
Amazon FBA
Amazing Selling Machine
Books - Data Science
Our Books
- Practical Guide to Cluster Analysis in R by A. Kassambara (Datanovia)
- Practical Guide To Principal Component Methods in R by A. Kassambara (Datanovia)
- Machine Learning Essentials: Practical Guide in R by A. Kassambara (Datanovia)
- R Graphics Essentials for Great Data Visualization by A. Kassambara (Datanovia)
- GGPlot2 Essentials for Great Data Visualization in R by A. Kassambara (Datanovia)
- Network Analysis and Visualization in R by A. Kassambara (Datanovia)
- Practical Statistics in R for Comparing Groups: Numerical Variables by A. Kassambara (Datanovia)
- Inter-Rater Reliability Essentials: Practical Guide in R by A. Kassambara (Datanovia)
Others
- R for Data Science: Import, Tidy, Transform, Visualize, and Model Data by Hadley Wickham & Garrett Grolemund
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems by Aurelien Géron
- Practical Statistics for Data Scientists: 50 Essential Concepts by Peter Bruce & Andrew Bruce
- Hands-On Programming with R: Write Your Own Functions And Simulations by Garrett Grolemund & Hadley Wickham
- An Introduction to Statistical Learning: with Applications in R by Gareth James et al.
- Deep Learning with R by François Chollet & J.J. Allaire
- Deep Learning with Python by François Chollet
Version:
 Français
Français



Anonymous (verified owner) –
Eko Subagyo (verified owner) –
Christian Larsen (verified owner) –
Hamidou Sy (verified owner) –
Payot Didier (verified owner) –
Manuel Pellicer (verified owner) –
Johann (verified owner) –
PCA in bivariate space can appear quite intimidating to those learning the concepts. This book is well-written and explains the key concepts in easy-to-understand language. The author has done very well in conveying complicated concepts on a level which most people can understand and this book has become my standard reference for PCA in R. This book is aimed at the beginner and average user of PCA. Key concepts are well-explained, but if you are looking for detailed mathematical proofs, then this is not the book for you.
David Fiscus (verified owner) –
What happened to the book? Its not here, but this email is. Hmmmm?
José de França Bueno (verified owner) –
Rita L. (verified owner) –
Very good books
Pavel (verified owner) –
Very professional level, very helpfull book
juan manuel (verified owner) –
very practical and usefull
Thorsten Raff (verified owner) –
Very good book with good examples.
Andre S. (verified owner) –
Minh Huynh (verified owner) –
Good resource material with easy to follow instructions and and working code
Anonymous (verified owner) –
Vincent V. (verified owner) –
Excellent intro, wonderful learning tool, numerous clear examples
Karol L. (verified owner) –
Jean-Carlos Montero-Serrano (verified owner) –
Excellent book ! but help is missing to make triangle diagrams/boxplot with PCAs and cluster groups in the biplot.
Anonymous (verified owner) –
MUSADJI Neil Yohan (verified owner) –
the book is very interesting. it provides and clearly explains the steps to carry out the factor analyzes.
However, could you clearly mention the script for getting variable weights?
Diego Andres Chavarro Bohorquez (verified owner) –
It is an very good book. Clearly explained and with very relevant examples.
Etienne Ntumba (verified owner) –
Anonymous (verified owner) –
Highly recommended.
Erry Ika RHOFITA (verified owner) –
Sebastian Riquelme (verified owner) –
The book gives an easy way to learn about statistical methods very needed for my master thesis. Besides, it makes a good balance between theory and practice. 100% recommended.
Chandan Kumar (verified owner) –
The book is good but it is feely available
Gerardo Mariscal (verified owner) –
The book is written in a clear way and the results obtained performing the commands suggested are amazing
Anonymous (verified owner) –
Jose Rafael Herrera Herrera (verified owner) –
The book is very explicit and complete in all explanantions of the principal component methods. The purchase process on the Datanovia web page was secure and easy. Thank you!
Anonymous (verified owner) –
Sílvia Panzo (verified owner) –