
Cluster analysis is one of the important data mining methods for discovering knowledge in multidimensional data. The goal of clustering is to identify pattern or groups of similar objects within a data set of interest.
Each group contains observations with similar profile according to a specific criteria. Similarity between observations is defined using some inter-observation distance measures including Euclidean and correlation-based distance measures.
In the literature, cluster analysis is referred as “pattern recognition” or “unsupervised machine learning” - “unsupervised” because we are not guided by a priori ideas of which variables or samples belong in which clusters. “Learning” because the machine algorithm “learns” how to cluster.
Cluster analysis is popular in many fields, including:
- In cancer research, for classifying patients into subgroups according their gene expression profile. This can be useful for identifying the molecular profile of patients with good or bad prognostic, as well as for understanding the disease.
- In marketing, for market segmentation by identifying subgroups of customers with similar profiles and who might be receptive to a particular form of advertising.
- In City-planning, for identifying groups of houses according to their type, value and location.
Note that, it’ possible to cluster both observations (i.e, samples or individuals) and features (i.e, variables). Observations can be clustered on the basis of variables and variables can be clustered on the basis of observations.
Here, we provide a practical guide to unsupervised machine learning or cluster analysis using R software.
Related Book
Practical Guide to Cluster Analysis in RHow this document is organized??
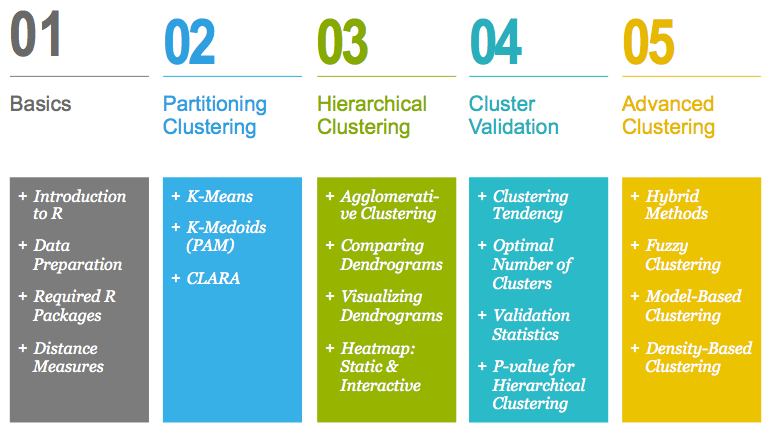
This document contains 5 parts.
Part I. Cluster Analysis Basics:
- Data Preparation and Essential R Packages for Cluster Analysis
- Clustering Distance Measures Essentials
Part II. Partitional Clustering methods:
- K-Means Clustering Essentials
- K-Medoids Essentials: PAM clustering
- CLARA - Clustering Large Applications
Part III. Hierarchical Clustering:
- Agglomerative Clustering
- Algorithm and steps
- Verify the cluster tree
- Cut the dendrogram into different groups
- Divisive Clustering
- Compare Dendrograms
- Visual comparison of two dendrograms
- Correlation matrix between a list of dendrograms
- Visualize Dendrograms
- Case of small data sets
- Case of dendrogram with large data sets: zoom, sub-tree, PDF
- Customize dendrograms using dendextend
- Heatmap: Static and Interactive
- R base heat maps
- Pretty heat maps
- Interactive heat maps
- Complex heatmap
- Real application: gene expression data
Part IV. Clustering Validation and Evaluation Strategies :
- Assessing Clustering Tendency
- Determining the Optimal Number of Clusters
- Cluster Validation Statistics
- Choosing the Best Clustering Algorithms
- Computing p-value for Hierarchical Clustering
- Hierarchical K-means Clustering
- Fuzzy Clustering
- Model-Based Clustering
- DBSCAN: Density-Based Clustering
Recommended for you
This section contains best data science and self-development resources to help you on your path.
Books - Data Science
Our Books
- Practical Guide to Cluster Analysis in R by A. Kassambara (Datanovia)
- Practical Guide To Principal Component Methods in R by A. Kassambara (Datanovia)
- Machine Learning Essentials: Practical Guide in R by A. Kassambara (Datanovia)
- R Graphics Essentials for Great Data Visualization by A. Kassambara (Datanovia)
- GGPlot2 Essentials for Great Data Visualization in R by A. Kassambara (Datanovia)
- Network Analysis and Visualization in R by A. Kassambara (Datanovia)
- Practical Statistics in R for Comparing Groups: Numerical Variables by A. Kassambara (Datanovia)
- Inter-Rater Reliability Essentials: Practical Guide in R by A. Kassambara (Datanovia)
Others
- R for Data Science: Import, Tidy, Transform, Visualize, and Model Data by Hadley Wickham & Garrett Grolemund
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems by Aurelien Géron
- Practical Statistics for Data Scientists: 50 Essential Concepts by Peter Bruce & Andrew Bruce
- Hands-On Programming with R: Write Your Own Functions And Simulations by Garrett Grolemund & Hadley Wickham
- An Introduction to Statistical Learning: with Applications in R by Gareth James et al.
- Deep Learning with R by François Chollet & J.J. Allaire
- Deep Learning with Python by François Chollet




how i can get this course ?
Hi, this website is just great. Thank you for putting all this together. I have a crucial question. Several codes do not work although I loaded the factoextra package. These are get_dist, fviz_dist, fviz_nbcluster and fviz_cluster. R keeps telling me it couldn’t find these functions when I want to use them. Any idea why that is? Thank you already in advance for your help!