The Fleiss kappa is an inter-rater agreement measure that extends the Cohen’s Kappa for evaluating the level of agreement between two or more raters, when the method of assessment is measured on a categorical scale. It expresses the degree to which the observed proportion of agreement among raters exceeds what would be expected if all raters made their ratings completely randomly.
For example, you could use the Fleiss kappa to assess the agreement between 3 clinical doctors in diagnosing the Psychiatric disorders of patients.
Note that, the Fleiss Kappa can be specially used when participants are rated by different sets of raters. This means that the raters responsible for rating one subject are not assumed to be the same as those responsible for rating another (Fleiss et al., 2003).
Contents:
Related Book
Inter-Rater Reliability Essentials: Practical Guide in RBasics
Formula
Briefly the kappa coefficient is an agreement measure that removes the expected agreement due to chance. It can be expressed as follow:
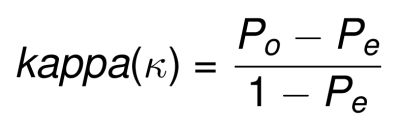
- Po is the observed agreement
- Pe is the expected agreement
Examples of formula to compute Po and Pe for Fleiss Kappa can be found in Joseph L. Fleiss (2003) and on wikipedia.
kappa can range form -1 (no agreement) to +1 (perfect agreement).
- when k = 0, the agreement is no better than what would be obtained by chance.
- when k is negative, the agreement is less than the agreement expected by chance.
- when k is positive, the rater agreement exceeds chance agreement.
Interpretation: Magnitude of the agreement
The interpretation of the magnitude of Fleiss kappa is like that of the classical Cohen’s kappa (Joseph L. Fleiss 2003). For most purposes,
- values greater than 0.75 or so may be taken to represent excellent agreement beyond chance,
- values below 0.40 or so may be taken to represent poor agreement beyond chance, and
- values between 0.40 and 0.75 may be taken to represent fair to good agreement beyond chance.
Read more on kappa interpretation at (Chapter @ref(cohen-s-kappa)).
Assumptions
Your data should met the following assumptions for computing Fleiss kappa.
- The outcome variables returned by raters should be categorical (either nominal or ordinal)
- The outcome variables should have exactly the same categories
- The raters are independent
Statistical hypotheses
- Null hypothesis (H0):
kappa = 0. The agreement is the same as chance agreement. - Alternative hypothesis (Ha):
kappa ≠ 0. The agreement is different from chance agreement.
Example of data
We’ll use the psychiatric diagnoses data provided by 6 raters. This data is available in the irr package. A total of 30 patients were enrolled and classified by each of the raters into 5 categories (Fleiss and others 1971): 1. Depression, 2. Personality Disorder, 3. Schizophrenia, 4. Neurosis, 5. Other.
# install.packages("irr")
library("irr")
data("diagnoses", package = "irr")
head(diagnoses[, 1:3])## rater1 rater2 rater3
## 1 4. Neurosis 4. Neurosis 4. Neurosis
## 2 2. Personality Disorder 2. Personality Disorder 2. Personality Disorder
## 3 2. Personality Disorder 3. Schizophrenia 3. Schizophrenia
## 4 5. Other 5. Other 5. Other
## 5 2. Personality Disorder 2. Personality Disorder 2. Personality Disorder
## 6 1. Depression 1. Depression 3. SchizophreniaComputing Fleiss Kappa
The R function kappam.fleiss() [irr package] can be used to compute Fleiss kappa as an index of inter-rater agreement between m raters on categorical data.
In the following example, we’ll compute the agreement between the first 3 raters:
library("irr")
# Select the irst three raters
mydata <- diagnoses[, 1:3]
# Compute kapa
kappam.fleiss(mydata)## Fleiss' Kappa for m Raters
##
## Subjects = 30
## Raters = 3
## Kappa = 0.534
##
## z = 9.89
## p-value = 0In our example, the Fleiss kappa (k) = 0.53, which represents fair agreement according to Fleiss classification (Fleiss et al. 2003). This is confirmed by the obtained p-value (p < 0.0001), indicating that our calculated kappa is significantly different from zero.
It’s also possible to compute the individual kappas, which are Fleiss Kappa computed for each of the categories separately against all other categories combined.
kappam.fleiss(mydata, detail = TRUE)## Fleiss' Kappa for m Raters
##
## Subjects = 30
## Raters = 3
## Kappa = 0.534
##
## z = 9.89
## p-value = 0
##
## Kappa z p.value
## 1. Depression 0.416 3.946 0.000
## 2. Personality Disorder 0.591 5.608 0.000
## 3. Schizophrenia 0.577 5.475 0.000
## 4. Neurosis 0.236 2.240 0.025
## 5. Other 1.000 9.487 0.000It can be seen that there is a fair to good agreement between raters in terms of rating participants as having “Depression”, “Personality Disorder”, “Schizophrenia” and “Other”; but there is a poor agreement in diagnosing “Neurosis”.
Report
Fleiss kappa was computed to assess the agreement between three doctors in diagnosing the psychiatric disorders in 30 patients. There was fair agreement between the three doctors, kappa = 0.53, p < 0.0001. Individual kappas for “Depression”, “Personality Disorder”, “Schizophrenia” “Neurosis” and “Other” was 0.42, 0.59, 0.58, 0.24 and 1.00, respectively.
Summary
This chapter explains the basics and the formula of the Fleiss kappa, which can be used to measure the agreement between multiple raters rating in categorical scales (either nominal or ordinal). We also show how to compute and interpret the kappa values using the R software. Note that, with Fleiss Kappa, you don’t necessarily need to have the same sets of raters for each participants (Joseph L. Fleiss 2003).
Another alternative to the Fleiss Kappa is the Light’s kappa for computing inter-rater agreement index between multiple raters on categorical data. Light’s kappa is just the average Cohen’s Kappa (Chapter @ref(cohen-s-kappa)) if using more than 2 raters.
References
Fleiss, J.L., and others. 1971. “Measuring Nominal Scale Agreement Among Many Raters.” Psychological Bulletin 76 (5): 378–82.
Joseph L. Fleiss, Myunghee Cho Paik, Bruce Levin. 2003. Statistical Methods for Rates and Proportions. 3rd ed. John Wiley; Sons, Inc.
Recommended for you
This section contains best data science and self-development resources to help you on your path.
Books - Data Science
Our Books
- Practical Guide to Cluster Analysis in R by A. Kassambara (Datanovia)
- Practical Guide To Principal Component Methods in R by A. Kassambara (Datanovia)
- Machine Learning Essentials: Practical Guide in R by A. Kassambara (Datanovia)
- R Graphics Essentials for Great Data Visualization by A. Kassambara (Datanovia)
- GGPlot2 Essentials for Great Data Visualization in R by A. Kassambara (Datanovia)
- Network Analysis and Visualization in R by A. Kassambara (Datanovia)
- Practical Statistics in R for Comparing Groups: Numerical Variables by A. Kassambara (Datanovia)
- Inter-Rater Reliability Essentials: Practical Guide in R by A. Kassambara (Datanovia)
Others
- R for Data Science: Import, Tidy, Transform, Visualize, and Model Data by Hadley Wickham & Garrett Grolemund
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems by Aurelien Géron
- Practical Statistics for Data Scientists: 50 Essential Concepts by Peter Bruce & Andrew Bruce
- Hands-On Programming with R: Write Your Own Functions And Simulations by Garrett Grolemund & Hadley Wickham
- An Introduction to Statistical Learning: with Applications in R by Gareth James et al.
- Deep Learning with R by François Chollet & J.J. Allaire
- Deep Learning with Python by François Chollet
Version:
 Français
Français

No Comments