Modélisation statistique avec lm() et glm() dans R
Construire, diagnostiquer et améliorer les modèles de régression
Apprenez à réaliser des modélisations linéaires et linéaires généralisées dans R à l’aide de lm() et glm(). Ce tutoriel élargi couvre l’ajustement des modèles, les diagnostics, l’interprétation et les techniques avancées telles que les termes d’interaction et la régression polynomiale.
Modélisation statistique en R, lm dans R, glm dans R, régression linéaire R, Régression logistique R, Diagnostics de modèles en R, régression avancée R
Introduction
La modélisation statistique est la pierre angulaire de l’analyse des données dans R. Ce didacticiel vous explique comment construire des modèles de régression en utilisant lm() pour la régression linéaire et glm() pour les modèles linéaires généralisés, tels que la régression logistique. Outre l’ajustement des modèles, nous aborderons les techniques de diagnostic des performances des modèles, l’interprétation des résultats et l’exploration de techniques de modélisation avancées telles que les termes d’interaction et la régression polynomiale.
1. Modélisation linéaire avec lm()
La fonction lm() ajuste un modèle linéaire en minimisant la somme des erreurs quadratiques. Nous commencerons par un exemple simple utilisant l’ensemble de données mtcars pour prédire les kilomètres par gallon (mpg) based on car weight (wt).
data("mtcars")lm_model <-lm(mpg ~ wt, data = mtcars)summary(lm_model)
Call:
lm(formula = mpg ~ wt, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-4.5432 -2.3647 -0.1252 1.4096 6.8727
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 37.2851 1.8776 19.858 < 2e-16 ***
wt -5.3445 0.5591 -9.559 1.29e-10 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.046 on 30 degrees of freedom
Multiple R-squared: 0.7528, Adjusted R-squared: 0.7446
F-statistic: 91.38 on 1 and 30 DF, p-value: 1.294e-10
Interprétation
Intercept et coefficient:
La sortie montre l’ordonnée à l’origine et la pente (coefficient pour wt). Pour chaque unité de poids supplémentaire, on s’attend à ce que mpg varie de la valeur du coefficient.
R-carré:
Indique dans quelle mesure la variabilité de mpg est expliquée par le modèle.
Valeurs P:
Évaluer la signification statistique des prédicteurs.
2. Modélisation linéaire généralisée avec glm()
La fonction glm() étend les modèles linéaires pour tenir compte des distributions d’erreur non normales. Une utilisation courante est la régression logistique pour les résultats binaires. Ici, nous prédisons le type de transmission (am, where 0 = automatic, 1 = manual) based on car weight (wt).
glm_model <-glm(am ~ wt, data = mtcars, family = binomial)summary(glm_model)
Call:
glm(formula = am ~ wt, family = binomial, data = mtcars)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 12.040 4.510 2.670 0.00759 **
wt -4.024 1.436 -2.801 0.00509 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 43.230 on 31 degrees of freedom
Residual deviance: 19.176 on 30 degrees of freedom
AIC: 23.176
Number of Fisher Scoring iterations: 6
Interprétation
Coefficients:
Représenter les log-odds. Utilisez exp(coef(glm_model)) pour obtenir des rapports de cotes.
Fonction de famille et de lien:
La famille binomiale avec un lien logit est utilisée pour les résultats binaires.
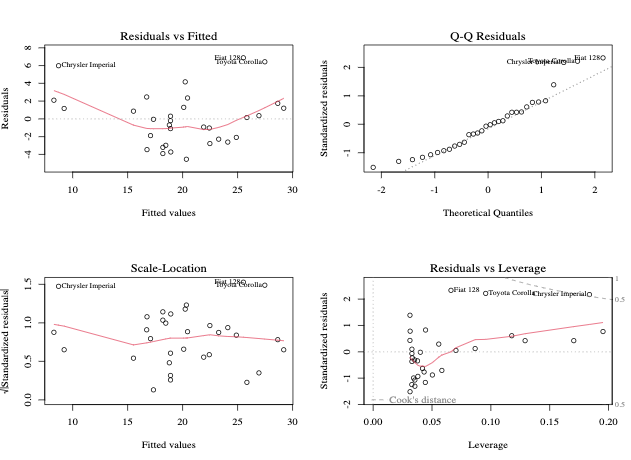
3. Diagnostic et validation des modèles
Après l’ajustement d’un modèle, il est essentiel de vérifier que les hypothèses du modèle sont valables.
Résidus vs. Effet de levier: Identifie les observations influentes.
Diagnostics pour glm()
Pour les modèles linéaires généralisés, vous pouvez utiliser:
Résidus de déviance: Vérifier l’adéquation du modèle.
Test d’Osmer-Lemeshow: Évaluer la qualité de l’ajustement (nécessite des paquets supplémentaires).
Courbe ROC: Évalue les performances de la classification.
4. Interprétation et visualisation des résultats des modèles
Il est essentiel de comprendre les résultats de votre modèle pour tirer des conclusions pertinentes.
Interprétation des résultats de lm()
Coefficients:
Déterminer la relation entre les prédicteurs et le résultat.
Intervalles de confiance:
Utilisez confint(lm_model) pour évaluer l’incertitude des estimations.
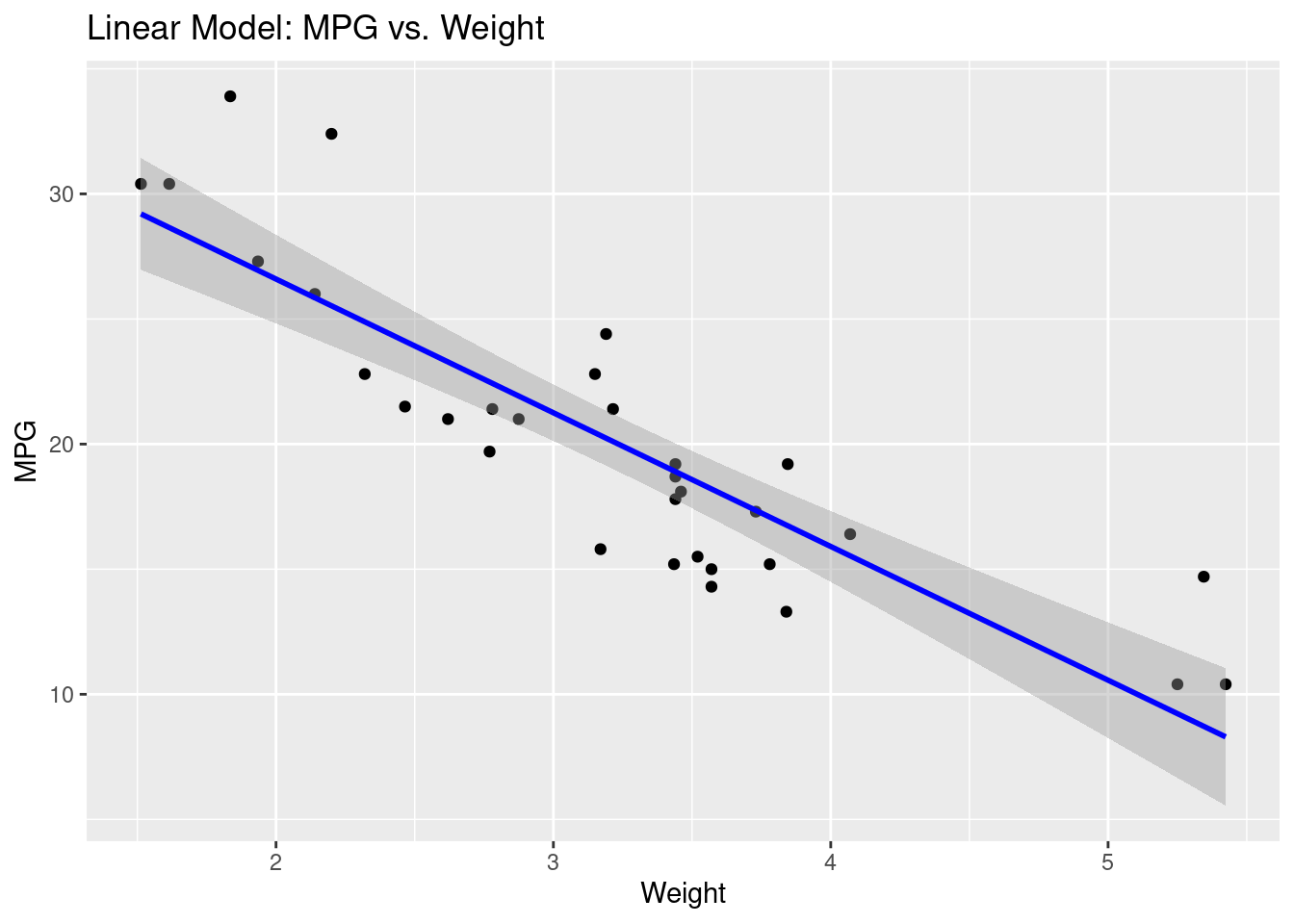
Visualisation des prédictions
library(ggplot2)ggplot(mtcars, aes(x = wt, y = mpg)) +geom_point() +geom_smooth(method ="lm", se =TRUE, color ="blue") +labs(title ="Linear Model: MPG vs. Weight", x ="Weight", y ="MPG")
Interprétation des résultats de glm()
Rapports de cotes:
Calculez en utilisant exp(coef(glm_model)) pour comprendre l’effet sur l’échelle de probabilité.
Probabilités prédites:
Utilisez predict(glm_model, type = 'response') pour obtenir des probabilités pour le résultat binaire.
5. Techniques de modélisation avancées
Améliorez vos modèles en incorporant des prédicteurs supplémentaires ou en transformant des variables.
Termes d’interaction
Inclure des interactions pour déterminer si l’effet d’un prédicteur dépend d’un autre.
interaction_model <-lm(mpg ~ wt * cyl, data = mtcars)summary(interaction_model)
Call:
lm(formula = mpg ~ wt * cyl, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-4.2288 -1.3495 -0.5042 1.4647 5.2344
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 54.3068 6.1275 8.863 1.29e-09 ***
wt -8.6556 2.3201 -3.731 0.000861 ***
cyl -3.8032 1.0050 -3.784 0.000747 ***
wt:cyl 0.8084 0.3273 2.470 0.019882 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.368 on 28 degrees of freedom
Multiple R-squared: 0.8606, Adjusted R-squared: 0.8457
F-statistic: 57.62 on 3 and 28 DF, p-value: 4.231e-12
Régression polynomiale
Modélisation des relations non linéaires par l’ajout de termes polynomiaux.
poly_model <-lm(mpg ~poly(wt, 2), data = mtcars)summary(poly_model)
Call:
lm(formula = mpg ~ poly(wt, 2), data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-3.483 -1.998 -0.773 1.462 6.238
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 20.0906 0.4686 42.877 < 2e-16 ***
poly(wt, 2)1 -29.1157 2.6506 -10.985 7.52e-12 ***
poly(wt, 2)2 8.6358 2.6506 3.258 0.00286 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.651 on 29 degrees of freedom
Multiple R-squared: 0.8191, Adjusted R-squared: 0.8066
F-statistic: 65.64 on 2 and 29 DF, p-value: 1.715e-11
Comparaison de modèles
Utiliser des critères tels que l’AIC (critère d’information d’Akaike) pour comparer différents modèles.
model1 <-lm(mpg ~ wt, data = mtcars)model2 <-lm(mpg ~ wt + cyl, data = mtcars)AIC(model1, model2)
df AIC
model1 3 166.0294
model2 4 156.0101
Conclusion
Ce tutoriel fournit une vue d’ensemble complète de la modélisation statistique dans R à l’aide de lm() et glm(). Vous avez appris à ajuster les modèles, à diagnostiquer les problèmes, à interpréter les résultats et à améliorer vos modèles à l’aide de techniques avancées. En intégrant ces méthodes, vous pouvez construire des modèles statistiques robustes qui produisent des résultats pertinents et fiables.
@online{kassambara2024,
author = {Kassambara, Alboukadel},
title = {Modélisation statistique avec lm() et glm() dans R},
date = {2024-02-10},
url = {https://www.datanovia.com/fr/learn/programming/r/data-science/statistical-modeling-with-lm-and-glm.html},
langid = {fr}
}