Construindo, diagnosticando e aprimorando modelos de regressão
Aprenda a realizar modelagem linear e linear generalizada no R usando lm() e glm(). Este tutorial expandido abrange ajuste de modelos, diagnósticos, interpretação e técnicas avançadas, como termos de interação e regressão polinomial.
Modelagem estatística em R, lm no R, glm em R, Regressão linear R, Regressão logística em R, Diagnóstico de modelos em R, Regressão avançada em R
Introdução
A modelagem estatística é um dos pilares da análise de dados no R. Este tutorial irá guiá-lo através da construção de modelos de regressão usando lm() para regressão linear e glm() para modelos lineares generalizados, tais como regressão logística. Além do ajuste de modelos, abordaremos técnicas para diagnosticar o desempenho do modelo, interpretar resultados e explorar técnicas avançadas de modelagem, como termos de interação e regressão polinomial.
1. Modelagem linear com lm()
A função lm() ajusta um modelo linear minimizando a soma dos erros quadrados. Começaremos com um exemplo simples usando o conjunto de dados mtcars para prever milhas por galão (mpg) based on car weight (wt).
data("mtcars")lm_model <-lm(mpg ~ wt, data = mtcars)summary(lm_model)
Call:
lm(formula = mpg ~ wt, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-4.5432 -2.3647 -0.1252 1.4096 6.8727
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 37.2851 1.8776 19.858 < 2e-16 ***
wt -5.3445 0.5591 -9.559 1.29e-10 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.046 on 30 degrees of freedom
Multiple R-squared: 0.7528, Adjusted R-squared: 0.7446
F-statistic: 91.38 on 1 and 30 DF, p-value: 1.294e-10
Interpretação
Interceptação e coeficiente:
A saída mostra a interceptação e a inclinação (coeficiente para wt). Para cada unidade adicional de peso, espera-se que mpg mude pelo valor do coeficiente.
R-quadrado:
Indica quanto da variabilidade em mpg é explicada pelo modelo.
Valores P:
Avalie a significância estatística dos preditores.
2. Modelagem linear generalizada com glm()
A função glm() estende os modelos lineares para acomodar distribuições de erros não normais. Um uso comum é a regressão logística para resultados binários. Aqui, prevemos o tipo de transmissão (am, where 0 = automatic, 1 = manual) based on car weight (wt).
glm_model <-glm(am ~ wt, data = mtcars, family = binomial)summary(glm_model)
Call:
glm(formula = am ~ wt, family = binomial, data = mtcars)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 12.040 4.510 2.670 0.00759 **
wt -4.024 1.436 -2.801 0.00509 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 43.230 on 31 degrees of freedom
Residual deviance: 19.176 on 30 degrees of freedom
AIC: 23.176
Number of Fisher Scoring iterations: 6
Interpretação
Coeficientes:
Representar log-odds. Use exp(coef(glm_model)) para obter odds ratios.
Família e função de ligação:
A família binomial com um link logit é usada para resultados binários.
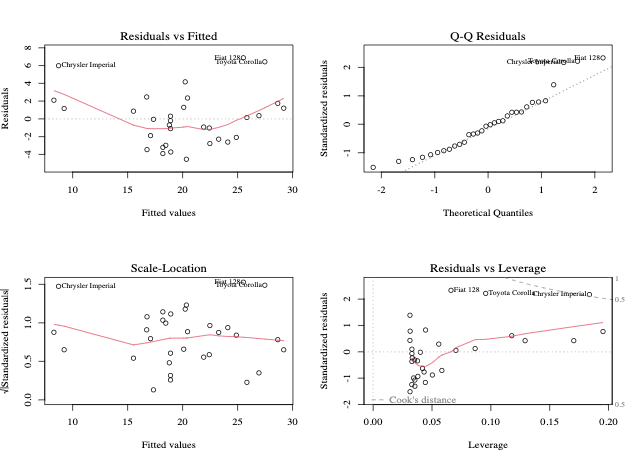
3. Diagnóstico e validação de modelos
Após ajustar um modelo, é essencial verificar se as premissas do modelo são válidas.
Resíduos vs. ajustados: Verifica a não linearidade.
Gráfico Q-Q normal: Avalia a normalidade dos resíduos.
Gráfico de escala-localização: Testa a homocedasticidade.
Resíduos vs. Alavancagem: Identifica observações influentes.
Diagnóstico para glm()
Para modelos lineares generalizados, você pode usar:
Resíduos de desvio: Verifique o ajuste do modelo.
Teste de Hosmer-Lemeshow: Avalie a adequação do ajuste (requer pacotes adicionais).
Curva ROC: Avalie o desempenho da classificação.
4. Interpretando e visualizando resultados do modelo
Entender a saída do seu modelo é fundamental para tirar conclusões significativas.
Interpretação dos resultados de lm()
Coeficientes:
Determine a relação entre os preditores e o resultado.
Intervalos de confiança:
Use confint(lm_model) para avaliar a incerteza nas estimativas.
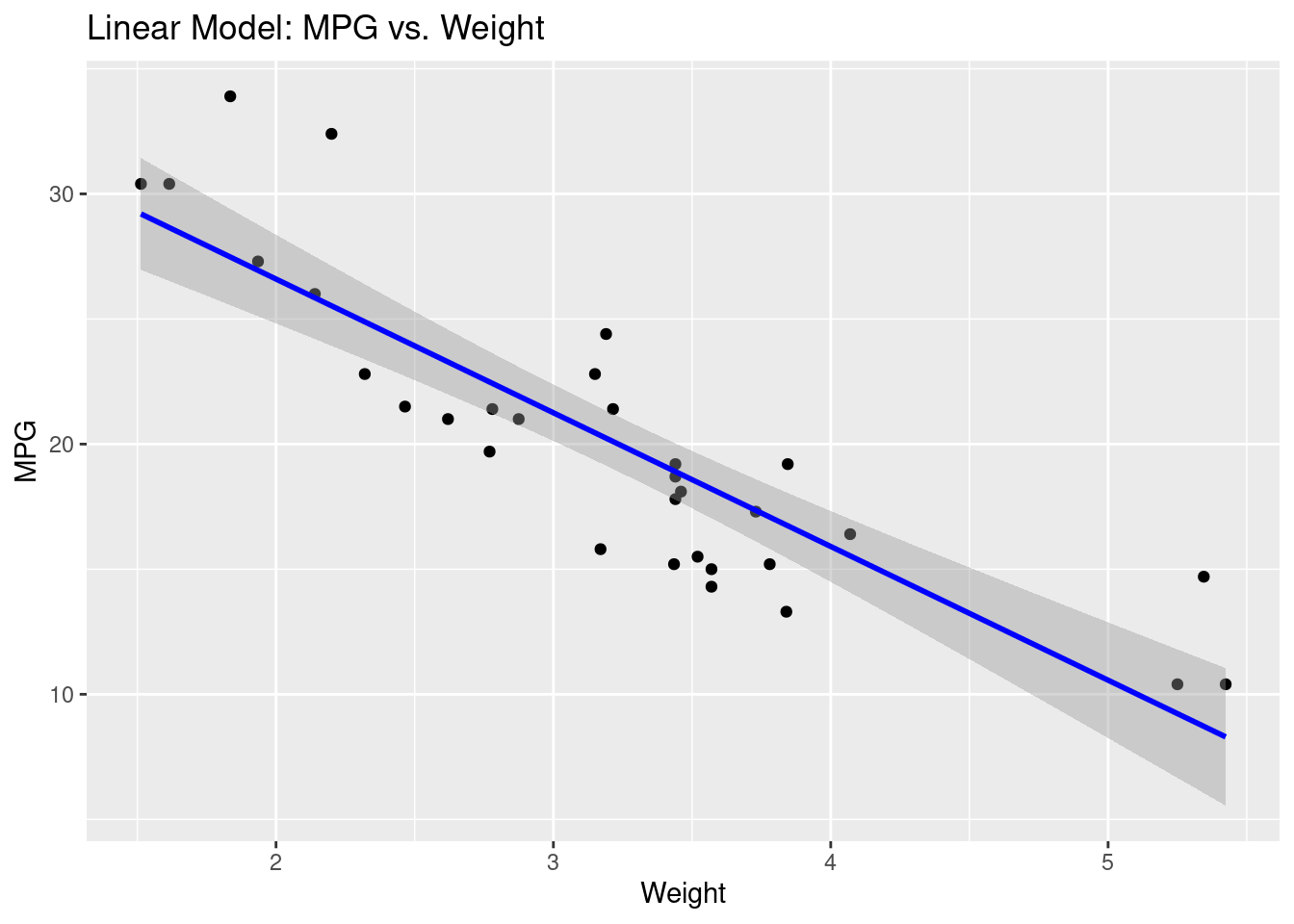
Visualização de previsões
library(ggplot2)ggplot(mtcars, aes(x = wt, y = mpg)) +geom_point() +geom_smooth(method ="lm", se =TRUE, color ="blue") +labs(title ="Linear Model: MPG vs. Weight", x ="Weight", y ="MPG")
Interpretação dos resultados de glm()
Razões de chances:
Calcule usando exp(coef(glm_model)) para entender o efeito na escala de probabilidade.
Probabilidades previstas:
Use predict(glm_model, type = 'response') para obter probabilidades para o resultado binário.
5. Técnicas avançadas de modelagem
Aprimore seus modelos incorporando preditores adicionais ou transformando variáveis.
Termos de interação
Inclua interações para explorar se o efeito de um preditor depende de outro.
interaction_model <-lm(mpg ~ wt * cyl, data = mtcars)summary(interaction_model)
Call:
lm(formula = mpg ~ wt * cyl, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-4.2288 -1.3495 -0.5042 1.4647 5.2344
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 54.3068 6.1275 8.863 1.29e-09 ***
wt -8.6556 2.3201 -3.731 0.000861 ***
cyl -3.8032 1.0050 -3.784 0.000747 ***
wt:cyl 0.8084 0.3273 2.470 0.019882 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.368 on 28 degrees of freedom
Multiple R-squared: 0.8606, Adjusted R-squared: 0.8457
F-statistic: 57.62 on 3 and 28 DF, p-value: 4.231e-12
Regressão polinomial
Modele relações não lineares adicionando termos polinomiais.
poly_model <-lm(mpg ~poly(wt, 2), data = mtcars)summary(poly_model)
Call:
lm(formula = mpg ~ poly(wt, 2), data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-3.483 -1.998 -0.773 1.462 6.238
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 20.0906 0.4686 42.877 < 2e-16 ***
poly(wt, 2)1 -29.1157 2.6506 -10.985 7.52e-12 ***
poly(wt, 2)2 8.6358 2.6506 3.258 0.00286 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.651 on 29 degrees of freedom
Multiple R-squared: 0.8191, Adjusted R-squared: 0.8066
F-statistic: 65.64 on 2 and 29 DF, p-value: 1.715e-11
Comparação de modelos
Use critérios como AIC (Critério de Informação de Akaike) para comparar diferentes modelos.
model1 <-lm(mpg ~ wt, data = mtcars)model2 <-lm(mpg ~ wt + cyl, data = mtcars)AIC(model1, model2)
df AIC
model1 3 166.0294
model2 4 156.0101
Conclusão
Este tutorial forneceu uma visão geral abrangente da modelagem estatística em R usando lm() e glm(). Você aprendeu como ajustar modelos, diagnosticar problemas, interpretar resultados e aprimorar seus modelos com técnicas avançadas. Ao integrar esses métodos, você pode criar modelos estatísticos robustos que geram resultados perspicazes e confiáveis.
@online{kassambara2024,
author = {Kassambara, Alboukadel},
title = {Modelagem estatística com lm() e glm() no R},
date = {2024-02-10},
url = {https://www.datanovia.com/pt/learn/programming/r/data-science/statistical-modeling-with-lm-and-glm.html},
langid = {pt}
}