Creación, diagnóstico y mejora de modelos de regresión
Aprenda a realizar modelos lineales y lineales generalizados en R utilizando lm() y glm(). Este tutorial ampliado cubre el ajuste de modelos, el diagnóstico, la interpretación y técnicas avanzadas como los términos de interacción y la regresión polinómica.
Modelado estadístico con R, lm en R, glm en R, regresión lineal R, regresión logística R, Diagnósticos de modelos en R, regresión avanzada R
Introducción
El modelado estadístico es una piedra angular del análisis de datos en R. Este tutorial le mostrará cómo construir modelos de regresión utilizando lm() para la regresión lineal y glm() para los modelos lineales generalizados, como la regresión logística. Además del ajuste del modelo, cubriremos técnicas para diagnosticar el rendimiento del modelo, interpretar los resultados y explorar técnicas avanzadas de modelado como términos de interacción y regresión polinómica.
1. Modelización lineal con lm()
La función lm() ajusta un modelo lineal minimizando la suma de errores al cuadrado. Comenzaremos con un ejemplo sencillo utilizando el conjunto de datos mtcars para predecir las millas por galón (mpg) based on car weight (wt).
data("mtcars")lm_model <-lm(mpg ~ wt, data = mtcars)summary(lm_model)
Call:
lm(formula = mpg ~ wt, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-4.5432 -2.3647 -0.1252 1.4096 6.8727
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 37.2851 1.8776 19.858 < 2e-16 ***
wt -5.3445 0.5591 -9.559 1.29e-10 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.046 on 30 degrees of freedom
Multiple R-squared: 0.7528, Adjusted R-squared: 0.7446
F-statistic: 91.38 on 1 and 30 DF, p-value: 1.294e-10
Interpretación
Intercepto y coeficiente:
La salida muestra el intercepto y la pendiente (coeficiente para wt). Por cada unidad adicional de peso, se espera que mpg cambie en el valor del coeficiente.
R-cuadrado:
Indica qué parte de la variabilidad de mpg es explicada por el modelo.
Valores P:
Evalúa la significación estadística de los predictores.
2. Modelización lineal generalizada con glm()
La función glm() amplía los modelos lineales para dar cabida a distribuciones de error no normales. Un uso común es la regresión logística para resultados binarios. Aquí predecimos el tipo de transmisión (am, where 0 = automatic, 1 = manual) based on car weight (wt).
glm_model <-glm(am ~ wt, data = mtcars, family = binomial)summary(glm_model)
Call:
glm(formula = am ~ wt, family = binomial, data = mtcars)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 12.040 4.510 2.670 0.00759 **
wt -4.024 1.436 -2.801 0.00509 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 43.230 on 31 degrees of freedom
Residual deviance: 19.176 on 30 degrees of freedom
AIC: 23.176
Number of Fisher Scoring iterations: 6
Interpretación
Coeficientes:
Representar log-odds. Utilice exp(coef(glm_model)) para obtener odds ratios.
Familia y función de enlace:
La familia binomial con un enlace logit se utiliza para resultados binarios.
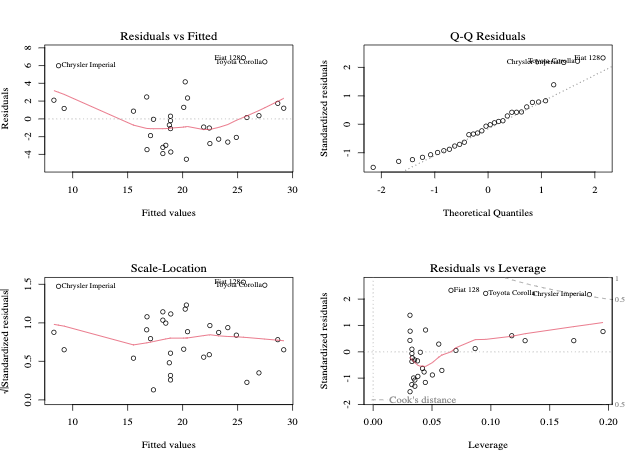
3. Diagnóstico y validación de modelos
Después de ajustar un modelo, es esencial verificar que se cumplen los supuestos del modelo.
Residuales frente a ajustados:Comprobación de no linealidad.
Ploteo Q-Q normal: Evalúa la normalidad de los residuos.
Plot de escala-localización:Pruebas de homocedasticidad.
Residuos frente a apalancamiento: Identifica las observaciones influyentes.
Diagnósticos para glm()
Para los modelos lineales generalizados, puede utilizar:
Residuos de desviación: Comprobar el ajuste del modelo.
Prueba de Hosmer-Lemeshow: Evalúa la bondad del ajuste (requiere paquetes adicionales).
Curva ROC: Evalúa el rendimiento de la clasificación.
4. Interpretación y visualización de los resultados del modelo
Comprender el resultado de su modelo es fundamental para extraer conclusiones significativas.
Interpretación de los resultados de lm()
Coeficientes:
Determina la relación entre los predictores y el resultado.
Intervalos de confianza:
Utilice confint(lm_model) para evaluar la incertidumbre en las estimaciones.
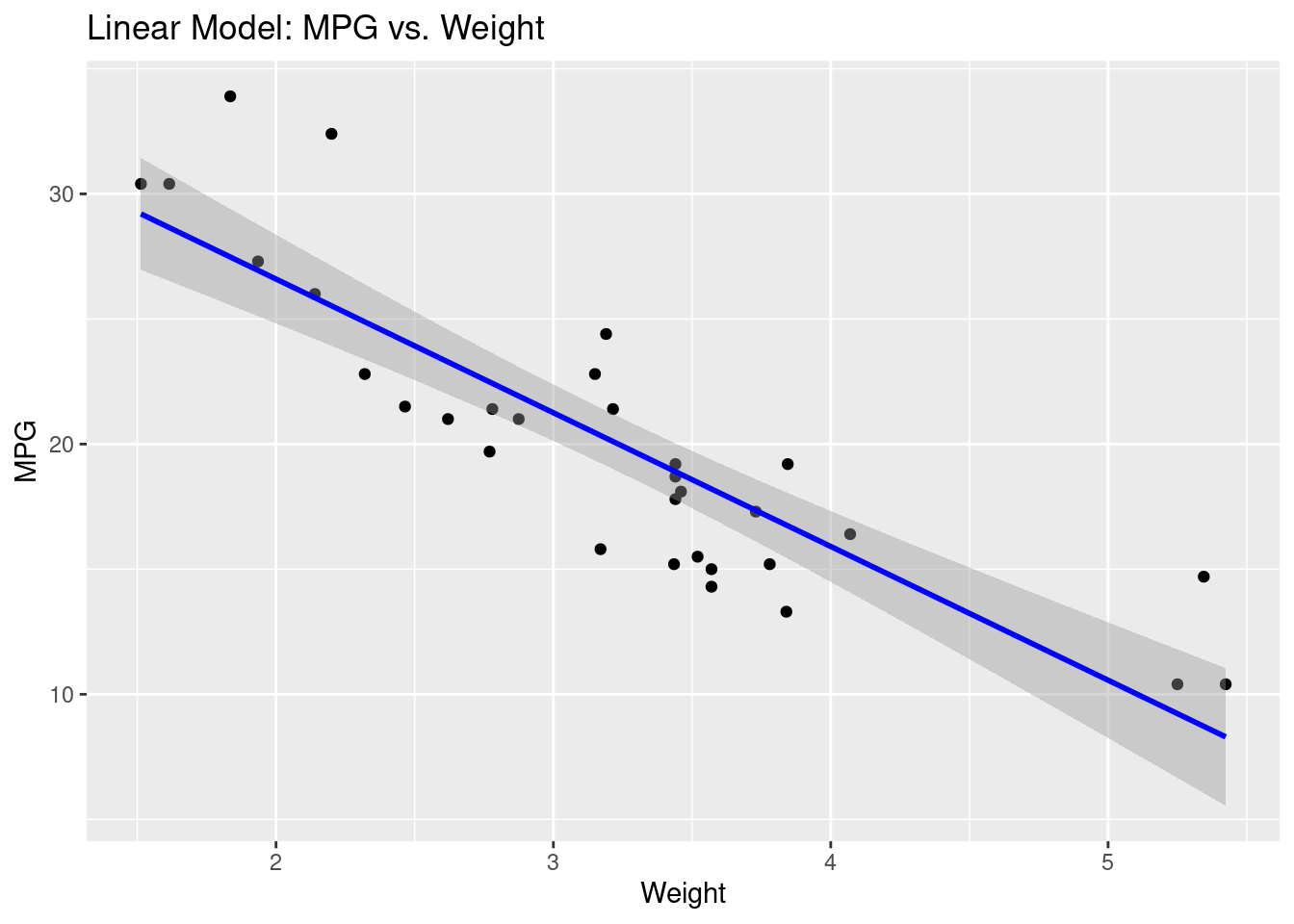
Visualización de predicciones
library(ggplot2)ggplot(mtcars, aes(x = wt, y = mpg)) +geom_point() +geom_smooth(method ="lm", se =TRUE, color ="blue") +labs(title ="Linear Model: MPG vs. Weight", x ="Weight", y ="MPG")
Interpretación de los resultados de glm()
Odds Ratios:
Calcule utilizando exp(coef(glm_model)) para comprender el efecto en la escala de probabilidad.
Probabilidades predichas:
Utilice predict(glm_model, type = 'response') para obtener probabilidades para el resultado binario.
5. Técnicas avanzadas de modelización
Mejore sus modelos incorporando predictores adicionales o transformando variables.
Términos de interacción
Incluya interacciones para explorar si el efecto de un predictor depende de otro.
interaction_model <-lm(mpg ~ wt * cyl, data = mtcars)summary(interaction_model)
Call:
lm(formula = mpg ~ wt * cyl, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-4.2288 -1.3495 -0.5042 1.4647 5.2344
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 54.3068 6.1275 8.863 1.29e-09 ***
wt -8.6556 2.3201 -3.731 0.000861 ***
cyl -3.8032 1.0050 -3.784 0.000747 ***
wt:cyl 0.8084 0.3273 2.470 0.019882 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.368 on 28 degrees of freedom
Multiple R-squared: 0.8606, Adjusted R-squared: 0.8457
F-statistic: 57.62 on 3 and 28 DF, p-value: 4.231e-12
Regresión polinómica
Modela relaciones no lineales añadiendo términos polinómicos.
poly_model <-lm(mpg ~poly(wt, 2), data = mtcars)summary(poly_model)
Call:
lm(formula = mpg ~ poly(wt, 2), data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-3.483 -1.998 -0.773 1.462 6.238
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 20.0906 0.4686 42.877 < 2e-16 ***
poly(wt, 2)1 -29.1157 2.6506 -10.985 7.52e-12 ***
poly(wt, 2)2 8.6358 2.6506 3.258 0.00286 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.651 on 29 degrees of freedom
Multiple R-squared: 0.8191, Adjusted R-squared: 0.8066
F-statistic: 65.64 on 2 and 29 DF, p-value: 1.715e-11
Comparación de modelos
Utilice criterios como AIC (Criterio de Información de Akaike) para comparar diferentes modelos.
model1 <-lm(mpg ~ wt, data = mtcars)model2 <-lm(mpg ~ wt + cyl, data = mtcars)AIC(model1, model2)
df AIC
model1 3 166.0294
model2 4 156.0101
Conclusión
Este tutorial proporciona una visión general de los modelos estadísticos en R utilizando lm() y glm(). Ha aprendido a ajustar modelos, diagnosticar problemas, interpretar resultados y mejorar sus modelos con técnicas avanzadas. Mediante la integración de estos métodos, puede construir modelos estadísticos robustos que produzcan resultados perspicaces y fiables.
@online{kassambara2024,
author = {Kassambara, Alboukadel},
title = {Modelización estadística con lm() y glm() en R},
date = {2024-02-10},
url = {https://www.datanovia.com/es/learn/programming/r/data-science/statistical-modeling-with-lm-and-glm.html},
langid = {es}
}