Erstellen, Diagnostizieren und Verbessern von Regressionsmodellen
Lernen Sie, wie Sie lineare und verallgemeinerte lineare Modellierung in R mit lm() und glm() durchführen können. Dieses erweiterte Tutorium behandelt Modellanpassung, Diagnose, Auswertung und fortgeschrittene Techniken wie Interaktionsterme und polynomiale Regression.
Statistische Modellierung mit R, lm in R, glm in R, lineare Regression R, logistische Regression R, Modelldiagnosen in R, erweiterte Regression R
Einführung
Statistische Modellierung ist ein Eckpfeiler der Datenanalyse in R. In diesem Tutorium lernen Sie, wie Sie Regressionsmodelle mit lm() für lineare Regression und glm() für verallgemeinerte lineare Modelle wie logistische Regression erstellen. Zusätzlich zur Modellanpassung werden wir Techniken zur Diagnose der Modellleistung, zur Auswertung der Ergebnisse und zur Erforschung fortgeschrittener Modellierungstechniken wie Interaktionsterme und polynomiale Regression behandeln.
1. Lineare Modellierung mit lm()
Die Funktion lm() passt ein lineares Modell durch Minimierung der Summe der quadrierten Fehler an. Wir beginnen mit einem einfachen Beispiel, das den mtcars-Datensatz zur Vorhersage des Benzinverbrauchs (mpg) based on car weight (wt) verwendet.
data("mtcars")lm_model <-lm(mpg ~ wt, data = mtcars)summary(lm_model)
Call:
lm(formula = mpg ~ wt, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-4.5432 -2.3647 -0.1252 1.4096 6.8727
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 37.2851 1.8776 19.858 < 2e-16 ***
wt -5.3445 0.5591 -9.559 1.29e-10 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.046 on 30 degrees of freedom
Multiple R-squared: 0.7528, Adjusted R-squared: 0.7446
F-statistic: 91.38 on 1 and 30 DF, p-value: 1.294e-10
Auswertung
Achsenabschnitt und Koeffizient:
Die Ausgabe zeigt den Achsenabschnitt und die Steigung (Koeffizient für wt). Für jede zusätzliche Gewichtseinheit wird erwartet, dass sich mpg um den Koeffizientenwert.
R-Quadrat:
Zeigt an, wie viel von der Variabilität in mpg durch das Modell erklärt wird.
P-Werte:
Bewertung der statistischen Signifikanz der Prädiktoren.
2. Verallgemeinerte lineare Modellierung mit glm()
Die Funktion glm() erweitert lineare Modelle, um nicht-normale Fehlerverteilungen zu berücksichtigen. Eine häufige Anwendung ist die logistische Regression für binäre Ergebnisse. Hier sagen wir die Übertragungsart (am, where 0 = automatic, 1 = manual) based on car weight (wt) voraus.
glm_model <-glm(am ~ wt, data = mtcars, family = binomial)summary(glm_model)
Call:
glm(formula = am ~ wt, family = binomial, data = mtcars)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 12.040 4.510 2.670 0.00759 **
wt -4.024 1.436 -2.801 0.00509 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 43.230 on 31 degrees of freedom
Residual deviance: 19.176 on 30 degrees of freedom
AIC: 23.176
Number of Fisher Scoring iterations: 6
Auswertung
Koeffizienten:
Log-odds darstellen. Verwenden Sie exp(coef(glm_model)), um Odds-Verhältnisse zu erhalten.
Familie und Verknüpfungsfunktion:
Für binäre Ergebnisse wird die Binomialfamilie mit einem Logit-Link verwendet.
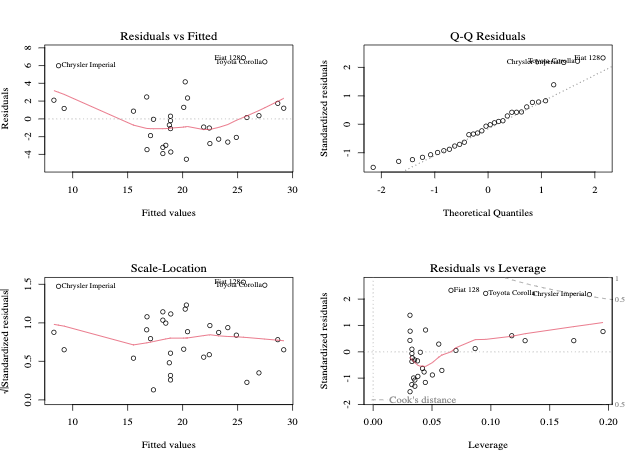
3. Modelldiagnose und -validierung
Nach der Anpassung eines Modells ist es wichtig, zu überprüfen, ob die Modellannahmen zutreffen.
Residuals vs. Fitted: Überprüft auf Nichtlinearität.
Normal Q-Q Plot: Bewertet die Normalität der Residuen.
Skalen-Lage-Plot: Test auf Homoskedastizität.
Residuals vs. Leverage: Identifiziert einflussreiche Beobachtungen.
Diagnosen für glm()
Für verallgemeinerte lineare Modelle können Sie verwenden:
Abweichungsresiduen: Überprüfung der Modellanpassung.
Hosmer-Lemeshow-Test: Bewertung der Anpassungsgüte (erfordert zusätzliche Pakete).
ROC-Kurve: Bewertung der Klassifizierungsleistung.
4. Interpretieren und Visualisieren von Modellergebnissen
Um aussagekräftige Schlussfolgerungen zu ziehen, ist es wichtig, die Ergebnisse Ihres Modells zu verstehen.
Auswertung der lm()-Ergebnisse
Koeffizienten:
Bestimmen der Beziehung zwischen Prädiktoren und dem Ergebnis.
Konfidenzintervalle:
Verwendung von confint(lm_model) zur Bewertung der Unsicherheit von Schätzungen.
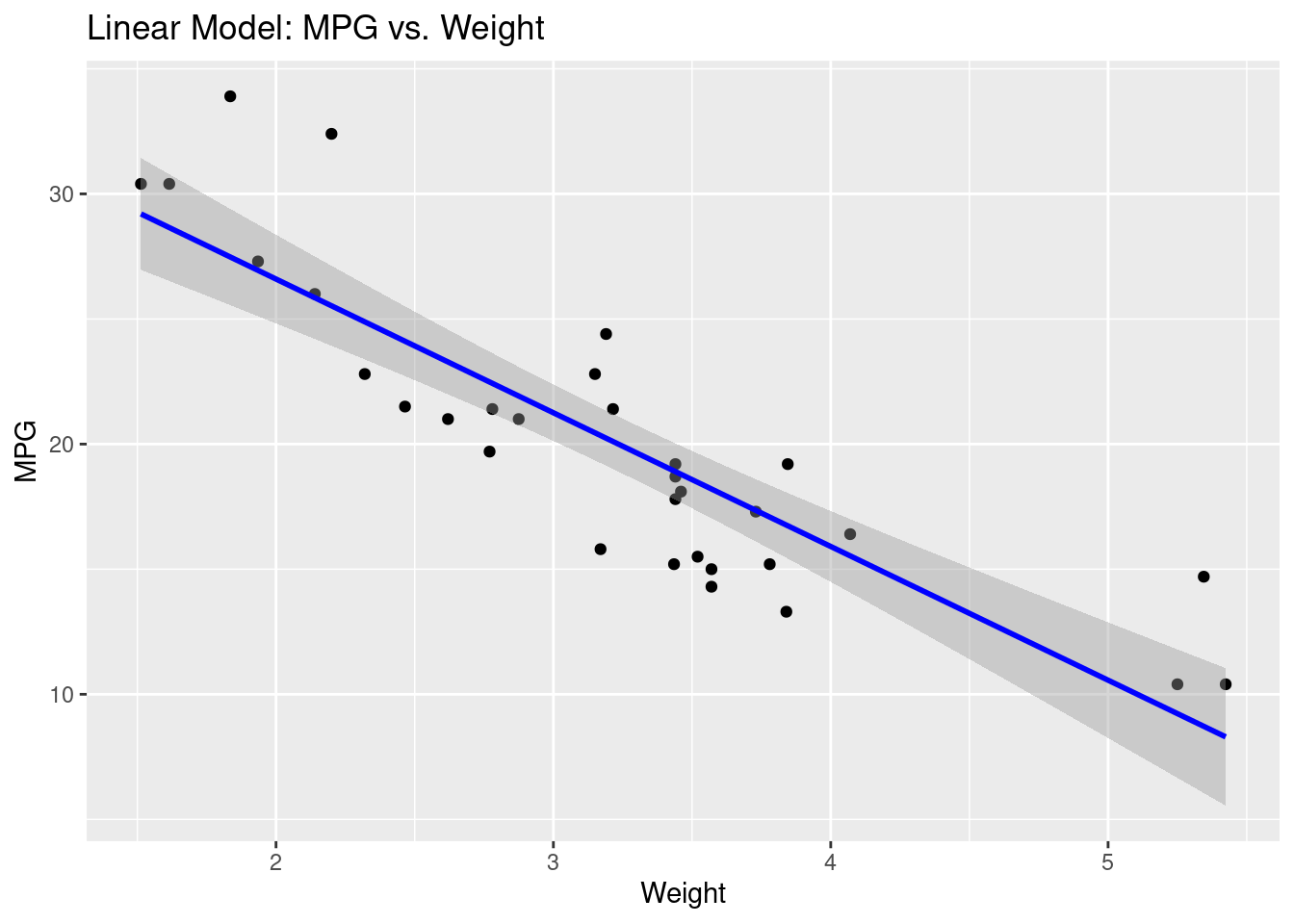
Visualisierung von Vorhersagen
library(ggplot2)ggplot(mtcars, aes(x = wt, y = mpg)) +geom_point() +geom_smooth(method ="lm", se =TRUE, color ="blue") +labs(title ="Linear Model: MPG vs. Weight", x ="Weight", y ="MPG")
Auswertung der glm()-Ergebnisse
Odds-Verhältnisse:
Berechnen Sie mit exp(coef(glm_model)), um die Auswirkungen auf die Wahrscheinlichkeitsskala zu verstehen.
Vorausgesagte Wahrscheinlichkeiten:
Verwenden Sie predict(glm_model, type = 'response'), um Wahrscheinlichkeiten für das binäre Ergebnis zu erhalten.
5. Fortgeschrittene Modellierungstechniken
Verbessern Sie Ihre Modelle, indem Sie zusätzliche Prädiktoren einbeziehen oder Variablen transformieren.
Interaktionsbedingungen
Einbeziehung von Wechselwirkungen, um zu untersuchen, ob die Wirkung eines Prädiktors von einem anderen abhängt.
interaction_model <-lm(mpg ~ wt * cyl, data = mtcars)summary(interaction_model)
Call:
lm(formula = mpg ~ wt * cyl, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-4.2288 -1.3495 -0.5042 1.4647 5.2344
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 54.3068 6.1275 8.863 1.29e-09 ***
wt -8.6556 2.3201 -3.731 0.000861 ***
cyl -3.8032 1.0050 -3.784 0.000747 ***
wt:cyl 0.8084 0.3273 2.470 0.019882 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.368 on 28 degrees of freedom
Multiple R-squared: 0.8606, Adjusted R-squared: 0.8457
F-statistic: 57.62 on 3 and 28 DF, p-value: 4.231e-12
Polynomielle Regression
Modellierung nichtlinearer Beziehungen durch Hinzufügen polynomieller Terme.
poly_model <-lm(mpg ~poly(wt, 2), data = mtcars)summary(poly_model)
Call:
lm(formula = mpg ~ poly(wt, 2), data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-3.483 -1.998 -0.773 1.462 6.238
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 20.0906 0.4686 42.877 < 2e-16 ***
poly(wt, 2)1 -29.1157 2.6506 -10.985 7.52e-12 ***
poly(wt, 2)2 8.6358 2.6506 3.258 0.00286 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.651 on 29 degrees of freedom
Multiple R-squared: 0.8191, Adjusted R-squared: 0.8066
F-statistic: 65.64 on 2 and 29 DF, p-value: 1.715e-11
Modell-Vergleich
Verwenden Sie Kriterien wie das AIC (Akaike Information Criterion), um verschiedene Modelle zu vergleichen.
model1 <-lm(mpg ~ wt, data = mtcars)model2 <-lm(mpg ~ wt + cyl, data = mtcars)AIC(model1, model2)
df AIC
model1 3 166.0294
model2 4 156.0101
Schlussfolgerung
Dieses Tutorium bot einen umfassenden Überblick über die statistische Modellierung in R mit lm() und glm(). Sie haben gelernt, wie Sie Modelle anpassen, Probleme diagnostizieren, Ergebnisse interpretieren und Ihre Modelle mit fortgeschrittenen Techniken verbessern können. Durch die Integration dieser Methoden können Sie robuste statistische Modelle erstellen, die aufschlussreiche und zuverlässige Ergebnisse liefern.
@online{kassambara2024,
author = {Kassambara, Alboukadel},
title = {Statistische Modellierung mit lm() und glm() in R},
date = {2024-02-10},
url = {https://www.datanovia.com/de/learn/programming/r/data-science/statistical-modeling-with-lm-and-glm.html},
langid = {de}
}