Um tutorial aprofundado sobre dplyr, tidyr e ggplot2
Aprenda a aproveitar o poder do tidyverse para ciência de dados. Este tutorial oferece uma visão aprofundada do dplyr para manipulação de dados, tidyr para organização de dados e ggplot2 para visualização de dados em R.
Tutorial tidyverse, Guia dplyr, tidyverse em R, ciência de dados tidyverse, R dplyr, R tidyr, Tutorial ggplot2
Introdução
O tidyverse é uma coleção de pacotes R que compartilham uma filosofia de design comum e são personalizados para ciência de dados. Neste tutorial, exploraremos três pacotes principais:
dplyr para manipulação de dados,
tidyr para organização de dados e
ggplot2 para visualização de dados.
Ao dominar essas ferramentas, você pode transformar, limpar e visualizar seus dados com um código elegante e eficiente. Esteja você preparando dados para análise ou criando gráficos prontos para publicação, o tidyverse oferece funções poderosas para otimizar seu fluxo de trabalho.
Usando dplyr para manipulação de dados
dplyr fornece um conjunto de funções intuitivas para filtrar, selecionar, mutar e resumir dados.
Exemplo: filtrando e resumindo com dplyr
library(dplyr)# Use o conjunto de dados mtcars integradodata("mtcars")# Filtre carros, selecione colunas-chave e resuma mtcars_summary <- mtcars %>%1filter(cyl >4) %>%2select(mpg, cyl, hp) %>%3group_by(cyl) %>%4summarize(avg_mpg =mean(mpg), avg_hp =mean(hp))
1
Filtre carros com mais de 4 cilindros.
2
Selecione colunas específicas para análise.
3
Agrupe os dados pelo número de cilindros.
4
Calcule a média de milhas por galão (mpg) e potência (hp) para cada contagem de cilindros.
Este exemplo demonstra como filtrar dados, selecionar colunas específicas, agrupar dados e calcular estatísticas resumidas, tudo em um único pipeline.
tidyr foi projetado para ajudá-lo a remodelar e organizar seus dados, facilitando sua análise. Tarefas comuns incluem pivotar dados do formato largo para o longo e vice-versa.
Exemplo: pivotando dados com tidyr
library(tidyr)library(dplyr)# Crie uma estrutura de dados de amostra em formato amplowide_data <-data.frame(id =1:3,measure_A =c(10, 20, 30),measure_B =c(40, 50, 60))print(wide_data)
# Converta os dados do formato amplo para o formato longolong_data <- wide_data %>%pivot_longer(cols =starts_with("measure"),names_to ="measure",values_to ="value")print(long_data)
Este exemplo mostra como organizar dados, remodelando-os em um formato longo mais fácil de analisar.
Visualizando dados com ggplot2
ggplot2 é um pacote versátil e poderoso para criar visualizações de dados de alta qualidade no R.
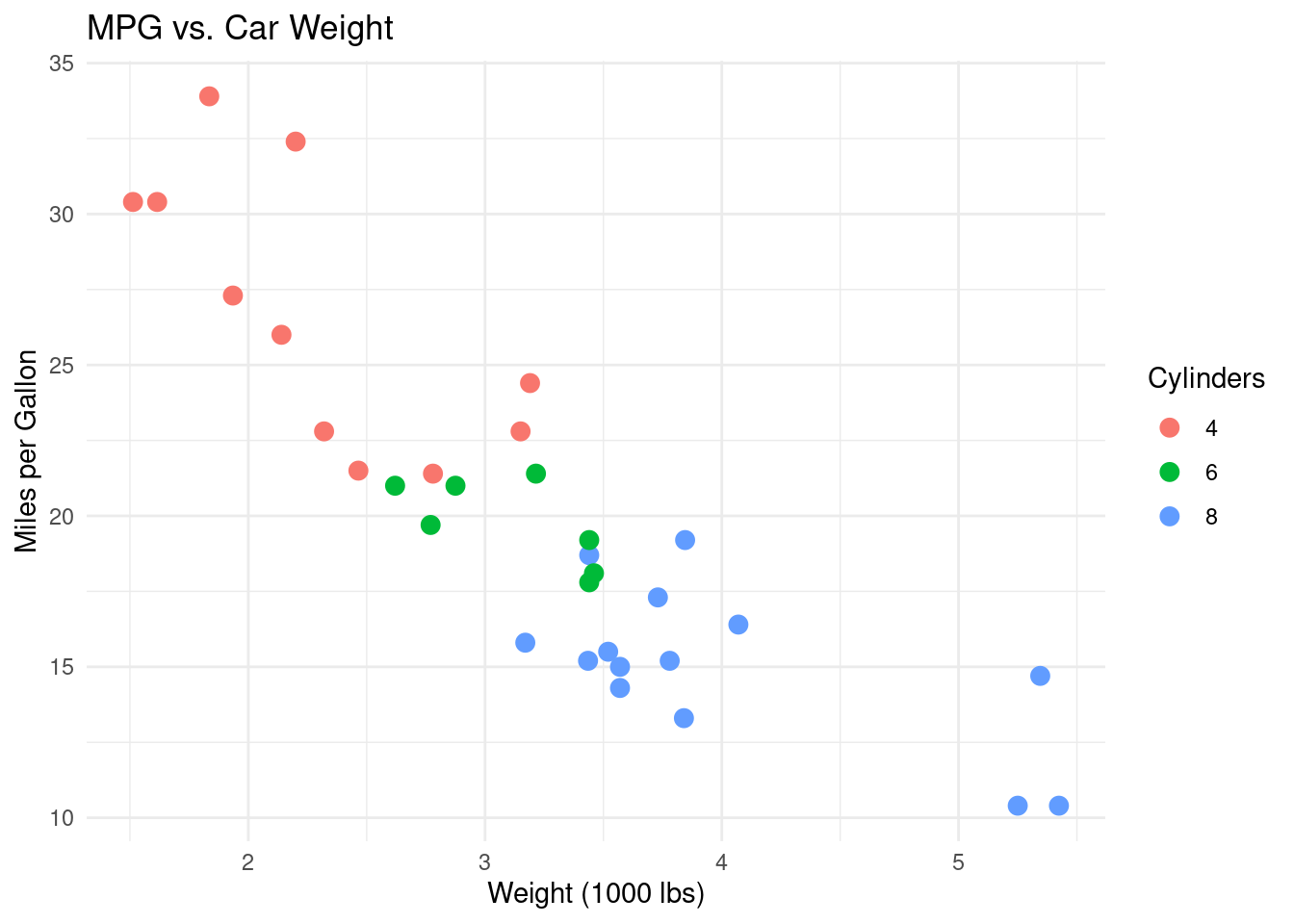
Exemplo: Criação de um gráfico de dispersão com ggplot2
library(ggplot2)# Use o conjunto de dados mtcars integradodata("mtcars")# Crie um gráfico de dispersão básico de mpg vs. peso, # Colorir pelo número de cilindrosggplot(data = mtcars, aes(x = wt, y = mpg, color =factor(cyl))) +geom_point(size =3) +labs(title ="MPG vs. Car Weight",x ="Weight (1000 lbs)",y ="Miles per Gallon",color ="Cylinders") +theme_minimal()
Este exemplo ilustra como usar ggplot2 para criar um gráfico de dispersão com rótulos e temas personalizados.
Conclusão
O tidyverse é um kit de ferramentas essencial para ciência de dados em R. Ao dominar dplyr, tidyr e ggplot2, você pode manipular, organizar e visualizar dados com eficiência. Essas ferramentas não apenas simplificam seu fluxo de trabalho, mas também ajudam a escrever código claro e reproduzível. Experimente os exemplos fornecidos e explore outras opções de personalização para adaptar o tidyverse às suas necessidades de análise de dados.