
The Hierarchical clustering [or hierarchical cluster analysis (HCA)] method is an alternative approach to partitional clustering for grouping objects based on their similarity.
In contrast to partitional clustering, the hierarchical clustering does not require to pre-specify the number of clusters to be produced.
Hierarchical clustering can be subdivided into two types:
- Agglomerative clustering in which, each observation is initially considered as a cluster of its own (leaf). Then, the most similar clusters are successively merged until there is just one single big cluster (root).
- Divise clustering, an inverse of agglomerative clustering, begins with the root, in witch all objects are included in one cluster. Then the most heterogeneous clusters are successively divided until all observation are in their own cluster.
The result of hierarchical clustering is a tree-based representation of the objects, which is also known as dendrogram (see the figure below).
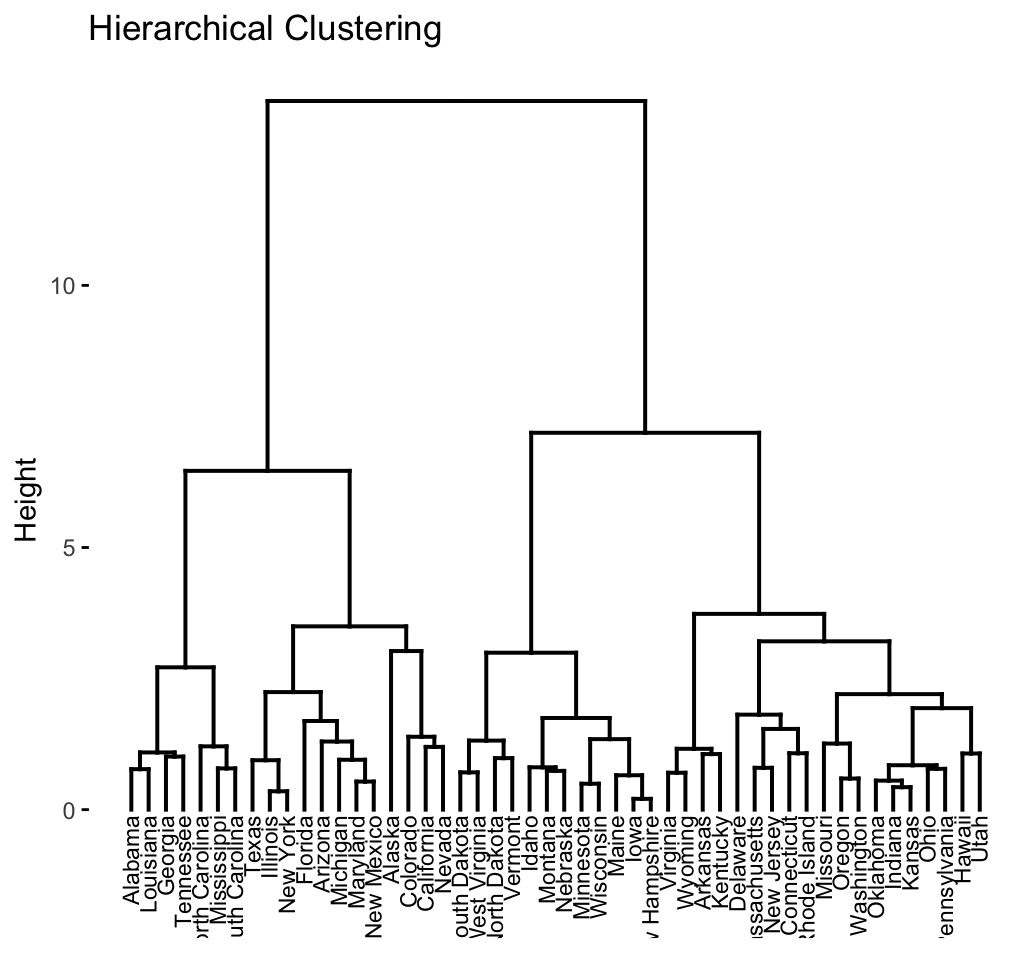
The dendrogram is a multilevel hierarchy where clusters at one level are joined together to form the clusters at the next levels. This makes it possible to decide the level at which to cut the tree for generating suitable groups of a data objects.
In this course, you will learn:
- The hierarchical clustering algorithms
- Examples of computing and visualizing hierarchical clustering in R
- How to cut dendrograms into groups.
- How to compare two dendrograms.
- Solutions for handling dendrograms of large data sets.




 (6 votes, average: 4.67 out of 5)
(6 votes, average: 4.67 out of 5)

Hi, I am new to this site and can’t find how to start the course. Where should I click to start the lesson? Thanks
Hi, you just need to click on a specific lesson title to read the corresponding contents
Thanks!
this is such a helpful course! Where can I download the raw data USarrests so I can follow along with the steps in R on my computer?
USArrests is a built-in R data set. So, to load it, just type this in R console: data(“USArrests”)
Hello,
Is it possible to get a course certificate on the completion of this course?