Clustering Distance Measures in R
Every clustering algorithm starts from a distance matrix. Learn how to prepare your data (numeric, scaled), compute Euclidean, Manhattan and correlation-based (Pearson…
The complete, practical guide to cluster analysis in R — partitioning (k-means, PAM, CLARA), hierarchical clustering and dendrograms, choosing and validating the number of clusters, and advanced methods (fuzzy, model-based, DBSCAN). Recipe-first, reproducible, with factoextra visuals.
Learn › Machine Learning › Cluster Analysis
Cluster analysis finds groups of similar observations — patients with a shared gene-expression profile, customers with similar buying habits, houses of the same type. It is unsupervised: you don’t tell the algorithm the groups, it learns them from the data. This is the complete, modernized Practical Guide to Cluster Analysis in R — every method as a recipe you can run, with publication-ready factoextra visuals.
01 · Basics
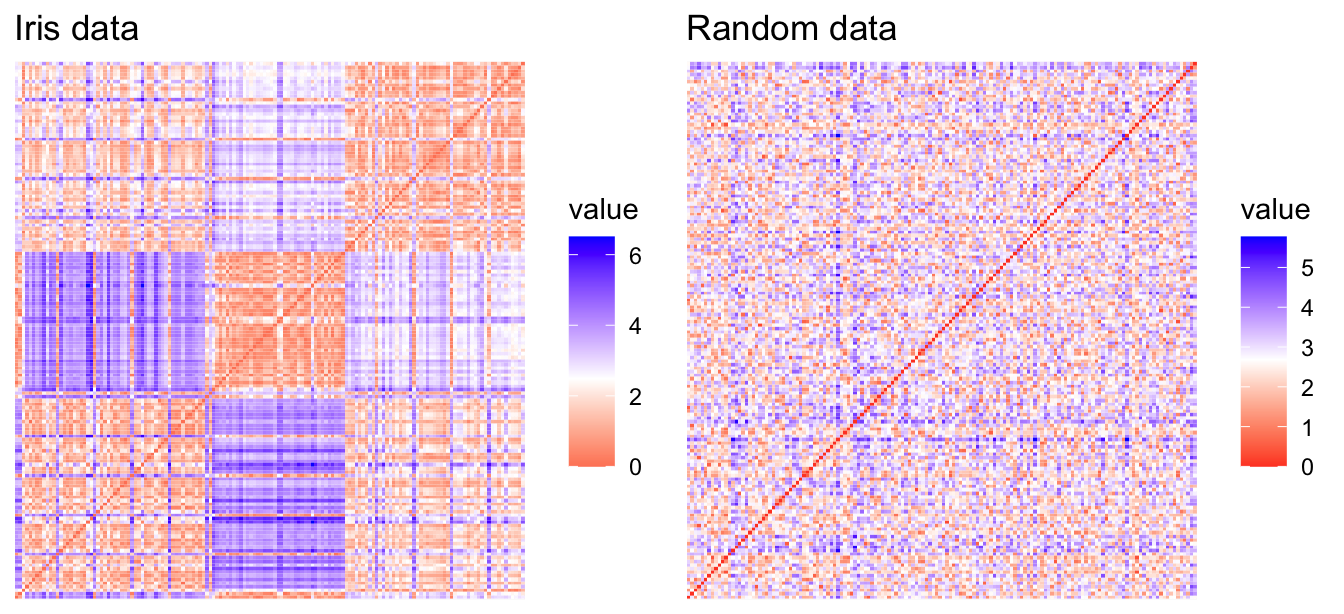
Data preparation · distance measures
02 · Partitioning
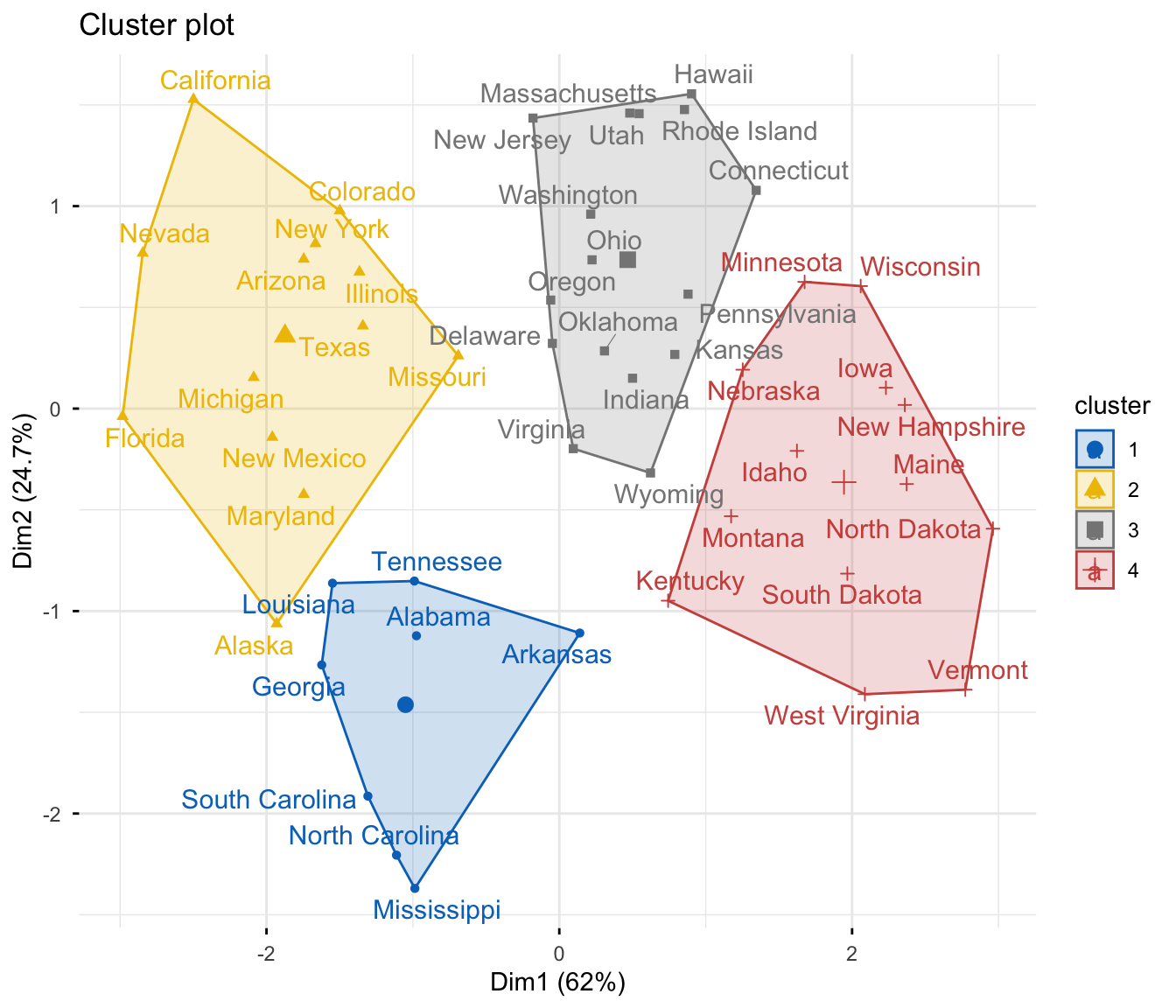
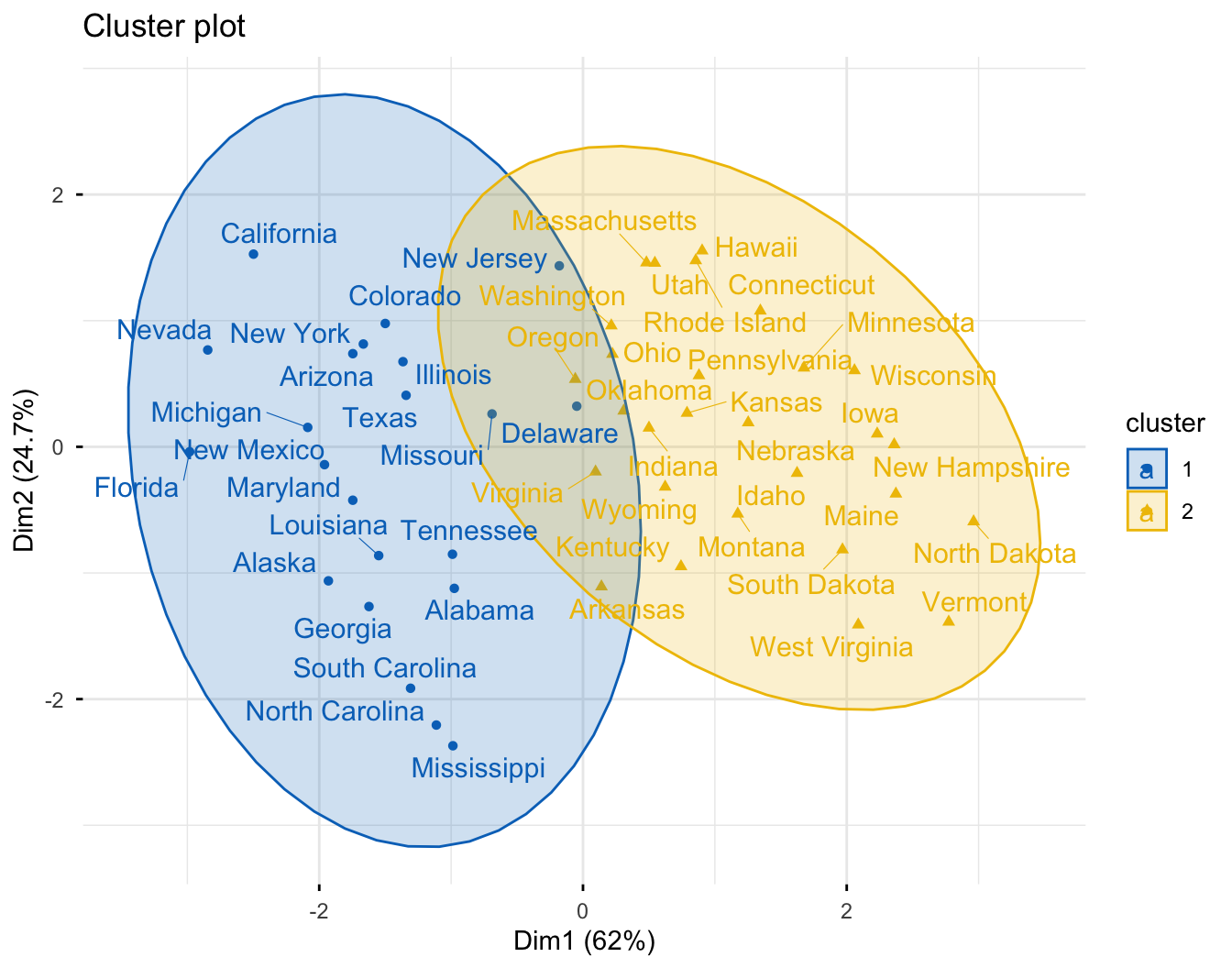
k-means · PAM · CLARA
03 · Hierarchical
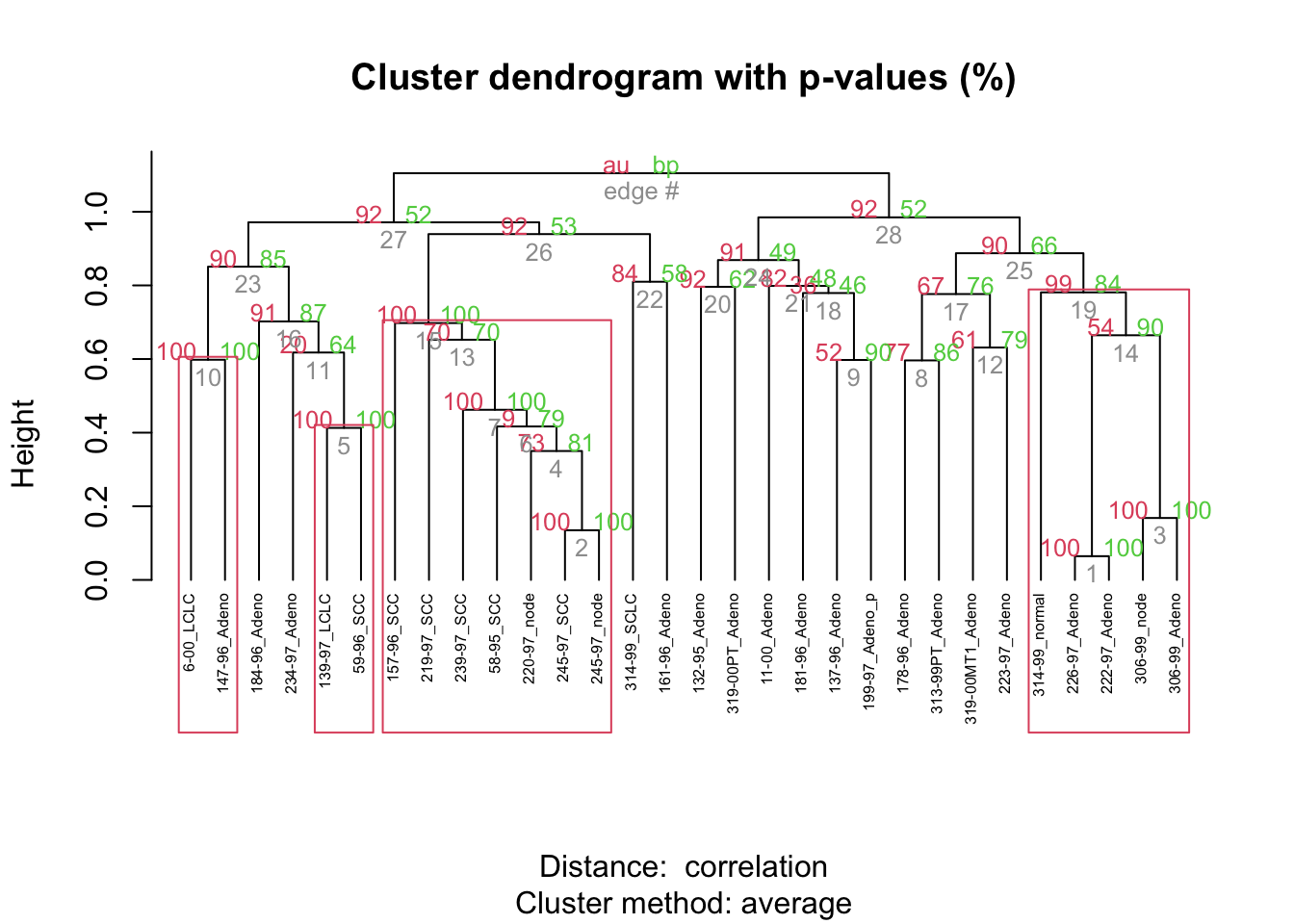
Agglomerative · dendrograms · heatmap
04 · Validation
Cluster tendency · optimal k · validation stats · p-value
05 · Advanced
Hybrid · fuzzy · model-based · density
The guide follows the same five parts as the book, in order:
Clustering methods fall into five families. The right one depends on whether you can fix the number of clusters up front, the shape of the groups you expect, and how big and noisy the data is:
| Family | How it groups | Pick the number of clusters? | Reach for it when… | Start here |
|---|---|---|---|---|
| Partitioning | each cluster around a centre (mean or medoid) | you set k up front |
groups are roughly round and you have a sensible k (or estimate one) |
k-means · PAM · CLARA (large data) |
| Hierarchical | a nested tree (dendrogram) you cut | read k off the tree afterwards |
you want a visual hierarchy and don’t want to pre-commit to k; small–medium data |
hierarchical clustering |
| Fuzzy | soft membership — each point partly in every cluster | you set k |
clusters overlap and a hard assignment loses information | fuzzy clustering |
| Model-based | data as a mixture of Gaussians; k chosen by BIC |
chosen automatically (BIC) | you want a statistical model + automatic k and soft probabilities |
model-based clustering |
| Density-based | dense regions = clusters; sparse points = noise | found automatically | clusters have arbitrary shapes and there are outliers/noise | DBSCAN |
Whatever you choose, the workflow is the same: prepare the data and pick a distance → check the data is actually clusterable → cluster → validate the result. New to this? Start with the step-by-step worked example.
This guide is filling in wave by wave — k-means, optimal number of clusters, hierarchical clustering and distance measures first, then the rest of partitioning, the dendrogram and heatmap chapters, validation, and the advanced methods.
Ask Prova “cluster this dataset and tell me how many groups it has” — it answers with R code you can run on your own data, then helps you read the cluster plot and validation stats. The runtime is the judge. Ask Prova →
Prove you can do it. Master the whole Cluster Analysis in R series — track your path, build projects, and earn a certificate.
Go Pro — unlimited Prova on your own data and a verifiable certificate that proves the skill.
from $15/mo billed yearly
✓ You're Pro — keep going. The runtime is the judge.
Ready to level up?
@online{untitled,
author = {},
title = {Cluster {Analysis} in {R}},
url = {https://www.datanovia.com/learn/machine-learning/clustering/},
langid = {en}
}