Introducción
El web scraping es una técnica esencial para los científicos y analistas de datos que necesitan extraer datos de sitios web para su análisis o investigación. En este tutorial, aprenderá a utilizar rvest, un popular paquete de R, para analizar HTML, extraer datos y hacer frente a los retos más comunes del scraping web. Empezaremos con ejemplos básicos y luego ampliaremos a temas más avanzados como la paginación, el uso de sesiones y el manejo de errores.
Configuración
Antes de empezar, asegúrese de que el paquete rvest está instalado y cargado:
#| label: install-rvest
# Instalar el paquete
install.packages("rvest")
# Cargar el paquete
library(rvest)Ejemplo básico de scraping web
Empecemos con un ejemplo sencillo: recuperar una página web y extraer su título.
#| label: basic-scraping
# Definir la URL que se va a extraer
url <- "https://www.worldometers.info/world-population/population-by-country/"
# Leer el contenido HTML de la URL
page <- read_html(url)
# Extraer el título de la página utilizando un selector CSS
page_title <- page %>% html_node("title") %>% html_text()
print(paste("Page Title:", page_title))Resultados:
[1] "Page Title: Population by Country (2025) - Worldometer"Extracción de enlaces y texto
Puede extraer hipervínculos y su texto de una página web:
#| label: extract-links
# Extraer todos los nodos de hipervínculos
links <- page %>% html_nodes("a")
# Extraer el texto y la URL de los 5 primeros enlaces
for (i in 1:min(5, length(links))) {
link_text <- links[i] %>% html_text(trim = TRUE)
link_href <- links[i] %>% html_attr("href")
print(paste("Link Text:", link_text, "- URL:", link_href))
}Resultados:
[1] "Link Text: - URL: /"
[1] "Link Text: Population - URL: /population/"
[1] "Link Text: CO2 emissions - URL: /co2-emissions/"
[1] "Link Text: Coronavirus - URL: /coronavirus/"
[1] "Link Text: Countries - URL: /geography/countries-of-the-world/"Extraer tablas
Muchos sitios web muestran datos en tablas. Utilice rvest para extraer y convertir tablas en marcos de datos:
#| label: extract-tables
# Encontrar la primera tabla de la página
table_node <- page %>% html_node("table")
# Convertir la tabla en un marco de datos
table_data <- table_node %>% html_table(fill = TRUE)
print(head(table_data))Resultados:

Manejo de la paginación
Para los sitios web que dividen los datos en varias páginas, puede automatizar la paginación. El siguiente código extrae los títulos y las URL de las entradas de un blog de un sitio web paginado iterando a través de un conjunto de números de página y, a continuación, combina los resultados en un marco de datos.
#| label: pagination-example
library(rvest)
library(dplyr)
library(purrr)
library(tibble)
# Definir una función para raspar una página dada su URL
scrape_page <- function(url) {
tryCatch({
read_html(url)
}, error = function(e) {
message("Error accessing URL: ", url)
return(NULL)
})
}
# El sitio web utiliza un parámetro de consulta `#listing-listing-page=` para la paginación
base_url <- "https://quarto.org/docs/blog/#listing-listing-page="
page_numbers <- 1:2 # Ejemplo: extraer las dos primeras páginas
# Inicializar un tibble vacío para almacenar las entradas
all_posts <- tibble(title = character(), url = character())
# Recorrer cada número de página
for (page_number in page_numbers) {
url <- paste0(base_url, page_number)
page <- scrape_page(url)
if (!is.null(page)) {
# Extraer entradas de blog: cada título y URL están dentro de una etiqueta <h3> con clase <no-anchor listing-title>
posts <- page %>%
html_nodes("h3.no-anchor.listing-title") %>%
map_df(function(h3) {
a_tag <- h3 %>% html_node("a")
if (!is.null(a_tag)) {
title <- a_tag %>% html_text(trim = TRUE)
link <- a_tag %>% html_attr("href")
tibble(title = title, url = link)
} else {
tibble(title = NA_character_, url = NA_character_)
}
})
# Añada las entradas de esta página a la lista general
all_posts <- bind_rows(all_posts, posts)
}
# Retraso respetuoso entre solicitudes
Sys.sleep(1)
}
# Mostrar las primeras filas de las entradas recopiladas
print(head(all_posts))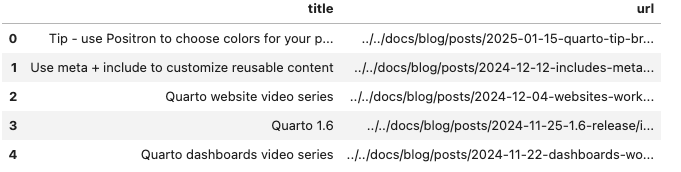
Usar sesiones
El uso de sesiones puede ayudar a mantener el estado (por ejemplo, cookies y cabeceras) a través de múltiples solicitudes, mejorando la eficiencia cuando se extraen múltiples páginas del mismo sitio.
#| label: using-sessions
url <- "https://www.worldometers.info/world-population/population-by-country/"
# Crear un objeto de sesión
session <- session("https://www.worldometers.info")
# Utilizar la sesión para navegar y hacer scraping
page <- session %>% session_jump_to(url)
page_title <- page %>% read_html() %>% html_node("title") %>% html_text()
print(paste("Session-based Page Title:", page_title))Gestión de errores
La integración de la gestión de errores garantiza que su script pueda gestionar problemas inesperados con elegancia.
#| label: error-handling
# Utilizar tryCatch para gestionar errores durante el scraping
safe_scrape <- function(url) {
tryCatch({
read_html(url)
}, error = function(e) {
message("Error: ", e$message)
return(NULL)
})
}
page <- safe_scrape("https://example.com/nonexistent")
if (is.null(page)) {
print("Failed to retrieve the page. Please check the URL or try again later.")
}Resultados:
Error: HTTP error 404.
[1] "Failed to retrieve the page. Please check the URL or try again later."Prácticas recomendadas para el scraping web
- Respetar las políticas del sitio web:
Compruebe siempre el archivorobots.txty las condiciones de servicio del sitio web para garantizar el cumplimiento de sus políticas de scraping. - Implementar la limitación de velocidad:
Utilice retardos (por ejemplo,Sys.sleep()) entre peticiones para evitar saturar el servidor. - Monitorización de cambios:
Los sitios web pueden cambiar su estructura con el tiempo. Actualice regularmente los selectores y el tratamiento de errores para adaptarlos a estos cambios. - Documentar el código:
Comente sus secuencias de comandos y estructúrelas claramente para facilitar su mantenimiento y reproducibilidad.
Conclusión
Ampliando lo básico, este tutorial cubre técnicas avanzadas para el web scraping con rvest, incluyendo el manejo de la paginación, el uso de sesiones y la implementación del manejo de errores. Con estas herramientas y mejores prácticas, puedes construir flujos de trabajo de extracción de datos sólidos para tus proyectos de ciencia de datos.
Lecturas adicionales
- Automatización de informes con RMarkdown
- Cuadros de mando interactivos con Shiny
- Tidyverse for Data Science
Feliz programación y disfrute explorando la web con rvest!
Explorar más artículos
Aquí hay más artículos de la misma categoría para ayudarte a profundizar en el tema.
Reutilización
Cómo citar
@online{kassambara2024,
author = {Kassambara, Alboukadel},
title = {Web scraping con rvest},
date = {2024-02-10},
url = {https://www.datanovia.com/es/learn/programming/r/tools/web-scraping-with-rvest.html},
langid = {es}
}