Einführung
Web-Scraping ist eine unverzichtbare Technik für Datenwissenschaftler und Analysten, die Daten aus Websites für Analysen oder Forschungszwecke extrahieren müssen. In diesem Tutorial lernen Sie, wie Sie rvest, ein beliebtes R-Paket, verwenden, um HTML zu analysieren, Daten zu extrahieren und allgemeine Web-Scraping-Herausforderungen zu bewältigen. Wir beginnen mit grundlegenden Beispielen und gehen dann auf fortgeschrittenere Themen wie Paginierung, Verwendung von Sitzungen und Fehlerbehandlung ein.
Einrichten
Bevor Sie beginnen, stellen Sie sicher, dass das Paket rvest installiert und geladen ist:
#| label: install-rvest
# Installieren Sie das Paket
install.packages("rvest")
# Laden Sie das Paket
library(rvest)Grundlegendes Web-Scraping-Beispiel
Beginnen wir mit einem einfachen Beispiel: Abrufen einer Webseite und Extrahieren ihres Titels.
#| label: basic-scraping
# Definieren Sie die zu scrappende URL
url <- "https://www.worldometers.info/world-population/population-by-country/"
# Lesen Sie den HTML-Inhalt aus der URL
page <- read_html(url)
# Extrahieren des Seitentitels mithilfe eines CSS-Selektors
page_title <- page %>% html_node("title") %>% html_text()
print(paste("Page Title:", page_title))Ergebnisse:
[1] "Page Title: Population by Country (2025) - Worldometer"Extrahieren von Links und Text
Sie können Hyperlinks und deren Text aus einer Webseite extrahieren:
#| label: extract-links
# Alle Hyperlink-Knoten extrahieren
links <- page %>% html_nodes("a")
# Extrahieren von Text und URLs für die ersten 5 Links
for (i in 1:min(5, length(links))) {
link_text <- links[i] %>% html_text(trim = TRUE)
link_href <- links[i] %>% html_attr("href")
print(paste("Link Text:", link_text, "- URL:", link_href))
}Ergebnisse:
[1] "Link Text: - URL: /"
[1] "Link Text: Population - URL: /population/"
[1] "Link Text: CO2 emissions - URL: /co2-emissions/"
[1] "Link Text: Coronavirus - URL: /coronavirus/"
[1] "Link Text: Countries - URL: /geography/countries-of-the-world/"Tabellen extrahieren
Viele Websites zeigen Daten in Tabellen an. Verwenden Sie rvest zum Extrahieren und Konvertieren von Tabellen in Datenrahmen:
#| label: extract-tables
# Suchen Sie die erste Tabelle auf der Seite
table_node <- page %>% html_node("table")
# Konvertieren Sie die Tabelle in einen Datenrahmen
table_data <- table_node %>% html_table(fill = TRUE)
print(head(table_data))Ergebnisse:

Paginierung behandeln
Bei Websites, die Daten auf mehrere Seiten aufteilen, können Sie den Seitenumbruch automatisieren. Der folgende Code extrahiert Blogpost-Titel und URLs aus einer paginierten Website, indem er durch eine Reihe von Seitenzahlen iteriert, und kombiniert die Ergebnisse dann in einem Datenrahmen.
#| label: pagination-example
library(rvest)
library(dplyr)
library(purrr)
library(tibble)
# Definieren Sie eine Funktion zum Scrapen einer Seite mit ihrer URL
scrape_page <- function(url) {
tryCatch({
read_html(url)
}, error = function(e) {
message("Error accessing URL: ", url)
return(NULL)
})
}
# Die Website verwendet einen Abfrageparameter `#listing-listing-page=` für die Paginierung
base_url <- "https://quarto.org/docs/blog/#listing-listing-page="
page_numbers <- 1:2 # Beispiel: Scraping der ersten 2 Seiten
# Initialisieren einer leeren Tibble zum Speichern von Beiträgen
all_posts <- tibble(title = character(), url = character())
# Schleife über jede Seitennummer
for (page_number in page_numbers) {
url <- paste0(base_url, page_number)
page <- scrape_page(url)
if (!is.null(page)) {
# Extrahieren von Blogbeiträgen: Jeder Titel und jede URL befindet sich in einem <h3>-Tag mit der Klasse 'no-anchor listing-title'
posts <- page %>%
html_nodes("h3.no-anchor.listing-title") %>%
map_df(function(h3) {
a_tag <- h3 %>% html_node("a")
if (!is.null(a_tag)) {
title <- a_tag %>% html_text(trim = TRUE)
link <- a_tag %>% html_attr("href")
tibble(title = title, url = link)
} else {
tibble(title = NA_character_, url = NA_character_)
}
})
# Hängen Sie die Beiträge dieser Seite an die Gesamtliste an
all_posts <- bind_rows(all_posts, posts)
}
# Respektvolle Verzögerung zwischen den Anfragen
Sys.sleep(1)
}
# Zeigen Sie die ersten paar Zeilen der gesammelten Beiträge an
print(head(all_posts))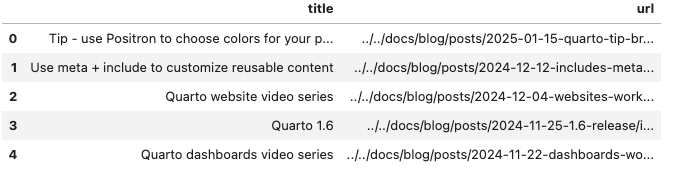
Sitzungen verwenden
Die Verwendung von Sitzungen kann dabei helfen, den Status (z. B. Cookies und Header) über mehrere Anfragen hinweg beizubehalten, was die Effizienz beim Scraping mehrerer Seiten derselben Website verbessert.
#| label: using-sessions
url <- "https://www.worldometers.info/world-population/population-by-country/"
# Ein Session-Objekt erstellen
session <- session("https://www.worldometers.info")
# Verwenden Sie die Sitzung zum Navigieren und Scrapen
page <- session %>% session_jump_to(url)
page_title <- page %>% read_html() %>% html_node("title") %>% html_text()
print(paste("Session-based Page Title:", page_title))Fehlerbehandlung
Die Integration einer Fehlerbehandlung stellt sicher, dass Ihr Skript unerwartete Probleme problemlos bewältigen kann.
#| label: error-handling
# Verwendung von tryCatch zur Behandlung von Fehlern beim Scraping
safe_scrape <- function(url) {
tryCatch({
read_html(url)
}, error = function(e) {
message("Error: ", e$message)
return(NULL)
})
}
page <- safe_scrape("https://example.com/nonexistent")
if (is.null(page)) {
print("Failed to retrieve the page. Please check the URL or try again later.")
}Ergebnisse:
Error: HTTP error 404.
[1] "Failed to retrieve the page. Please check the URL or try again later."Best Practices für Web-Scraping
- Website-Richtlinien respektieren:
Überprüfen Sie immer dierobots.txt-Datei und die Nutzungsbedingungen der Website, um sicherzustellen, dass die Scraping-Richtlinien eingehalten werden. - Ratenbegrenzung implementieren:
Verwenden Sie Verzögerungen (z. B.Sys.sleep()) zwischen Anfragen, um den Server nicht zu überlasten. - Monitor für Änderungen:
Websites können ihre Struktur im Laufe der Zeit ändern. Aktualisieren Sie regelmäßig Ihre Selektoren und die Fehlerbehandlung, um diese Änderungen zu berücksichtigen. - Dokumentieren Sie Ihren Code:
Kommentieren Sie Ihre Skripte und strukturieren Sie sie klar, um die Wartung und Reproduzierbarkeit zu erleichtern.
Schlussfolgerung
Dieses Tutorial erweitert die Grundlagen und behandelt fortgeschrittene Techniken für Web-Scraping mit rvest, einschließlich Paginierung, Verwendung von Sessions und Implementierung von Fehlerbehandlung. Mit diesen Tools und bewährten Verfahren können Sie robuste Datenextraktions-Workflows für Ihre Data-Science-Projekte erstellen.
Weiterführende Literatur
- Berichte automatisieren mit RMarkdown
- Interaktive Dashboards mit Shiny
- Tidyverse für Datenwissenschaft
Viel Spaß beim Programmieren und beim Erforschen des Webs mit rvest!
Weitere Artikel erkunden
Hier finden Sie weitere Artikel aus derselben Kategorie, die Ihnen helfen, tiefer in das Thema einzutauchen.
Wiederverwendung
Zitat
@online{kassambara2024,
author = {Kassambara, Alboukadel},
title = {Web-Scraping mit rvest},
date = {2024-02-10},
url = {https://www.datanovia.com/de/learn/programming/r/tools/web-scraping-with-rvest.html},
langid = {de}
}